







随着大数据的兴起,网络爬虫也变得热起来。在学习大数据的过程中,通过搜集大量的网络数据来验证自己的技能显然比WordCount更具吸引力。
各种编程语言都有爬虫的实现,来自Apache的Nutch毫无疑问属于爬虫的先驱,即便有先驱的名号,未必是使用最广的爬虫软件。入门的曲线陡峭是其中一个重要的因素。
最近正在琢磨和实现一个通用的爬虫服务,服务的内容是根据你给的一个域名,将该域名下的已有的网页和更新的网页每天发送给你。因此,需要比较深入的了解Nutch2的运作原理,顺便将这些理解通过文字分享给Nutch2的学习者。
如果你习惯开箱即用的软件,Nutch2显然不属此列。在QQ交流群里经常有新手提出一些非常基础的问题,多半是因为不熟悉Nutch2的工作原理。
在项目的更目录下会生成以下内容:
到了这一步,已经了解如何生成Nutch可运行程序。请问网页存储在哪里呢?这就需要开始修改源代码了,此处以Hbase为例。
然后重新运行ant runtime。
到了这一步,已经了解如何生成Nutch可运行程序。请问网页存储在哪里呢?这就需要开始修改源代码了,此处以Hbase为例。
-
-
conf/nutch-site.xml
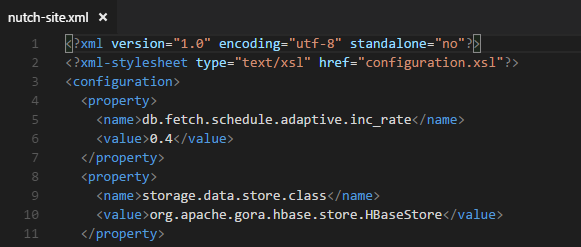
告诉Nutch存储使用的类是org.apache.gora.hbase.store.HBaseStore。这个类在哪个包里面呢?所以需要继续修改。
ivy/ivy.xml
-
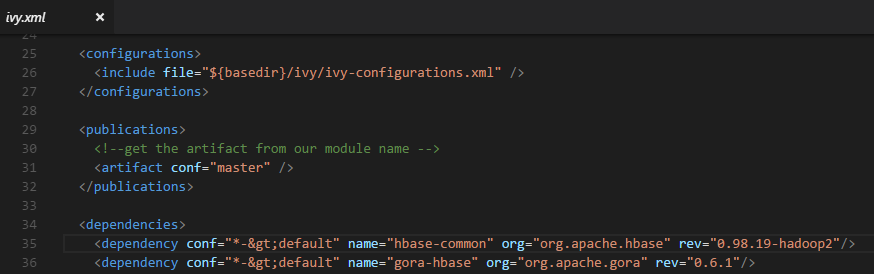
a设置值所指的类在gora-base包里面,这里添加之后ivy就会下载依赖。
-
conf/groa.properties
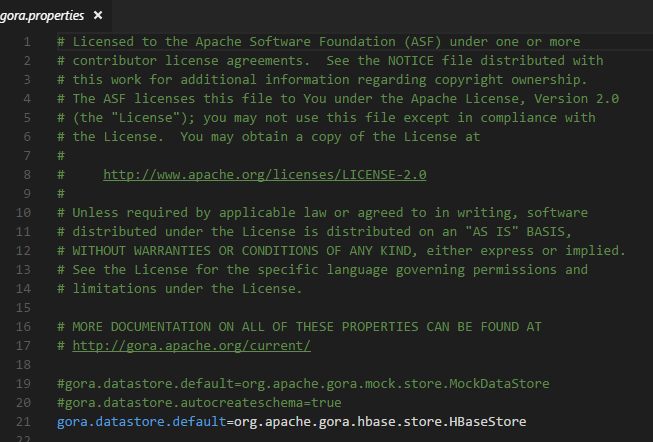
-
可以借机仔细看一下gora.properties的内容,如果是sql存储的话,会看到熟悉的jdbc的配置。但是gora.properties里面没有关于Hbase的进一步配置,因为没有必要,既然选择Hbase作为存储,你肯定知道原因。
-
2.Nutch的运行
编译后在runtime/bin下生成了可执行脚本,是bash脚本。如果你在Windows下面开发,到了这一步难免会感到气馁。重新找一台安装了Linux的开发机,或者一个Linux虚拟机,或者仔细阅读这写bash脚本然后用Powershell重写一遍,我的选择是重写一遍。
Nutch本质上是一个java程序,你所有关于java的知识都可用。脚本不过是辅助你用最少的键盘输入来运行程序而已。
Nutch分几个步骤完成一个爬取任务。再问自己一个问题,抓取哪个网站的内容呢?前面都没提到啊!是的,还需要再回头修改源代码,然后重新ant runtime。比如conf/nutch-site.xml里面的http.agent.name的值,更重要的是conf/regex-urlfilter.txt文件(如果你不是全网抓取的话),它限定了要抓取的url的范围。
![]()
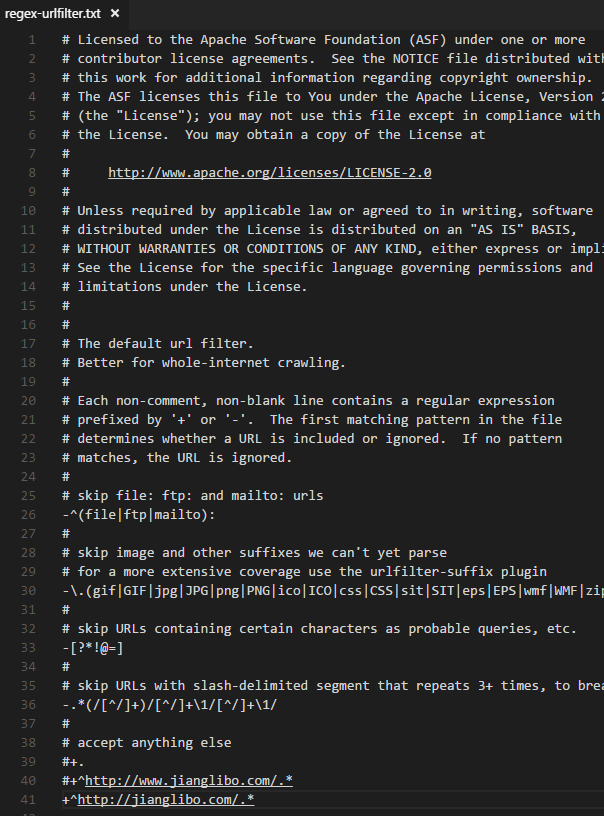
上图中的配置,限定了url的范围,即使该url中存在外部链接,爬虫也不会顺着这些链接继续前进。
接下来详细描述步骤:
-
注入(Inject)nutch inject /someseedDir
注意Nutch2在deploy模式下最终运行的都是hadoop jar命令,最最终是执行一个mapreduce任务。所以这个/someseedDir通常是hdfs://aa.bb.cc/someseedDir。从现在开始你会碰到各种各样的问题,基本上都是Hadoop一侧的问题,千万不要气馁,最终总能够解决。
注入的东西去哪里了呢?当然是Hbase里面啦,怎么存储的呢?可以查看下WebPage类,Nutch在不同的步骤中一次次地修改这个存储的对象。
-
Generate步骤,产生需要重新抓取的页面
如果一个页面刚刚抓过,还需要马上抓取吗?显然不需要,Nutch需要根据已经存在的WebPage对象,加上不同的配置策略决定要不要将某个WebPage对象标注成需要抓取。对于刚刚Inject的页面,都会标记成需要抓取。
-
Fetch步骤,抓取已经被Generate步骤标记的URL
这个不需要解释了,获取页面。将内容写入WebPage对象。
-
Parse步骤,解析页面
获取页面之后,将页面内所有的链接提取出来,再次更新WebPage对象,比如outlinks等等。
-
updatedb步骤。
从Inject到Parse,WebPage的数量并没有变化。但Parse之后显然发现了更多的页面,而且信息已经保存在已有的WebPage里面了,updatedb步骤根据这些信息生成新的WebPage对象。
然后从Generate步骤开始循环,将新的WebPage标注,忽略刚刚抓取的页面。loop,loop,loop,终于目标站点的页面全部抓取完了,Generate步骤在没有标注任何WebPage的情况下返回1,作为终止循环的条件。以上所述的内容就是阅读crawl脚本的过程!
更多的问题:
-
怎么抓取ajax页面啊?
这是插件的工作,通过headless的浏览器,加载页面之后,把整个dom导出来即可,你将得到完整信息的html。
-
网络上有许多傻瓜式的爬虫软件,可以直接选择dom,获取最终信息
既然Nutch已经捕获了所有页面,这个功能只是将html从数据库里取出来,然后用java的regex或者xpath提取信息而已。Nutch已经做了最核心的功能,特别是同步目标站点的内容。
-
其它关于Nutch的问题基本上是Nutch之外的问题,特别是Hadoop一侧的内容居多。
回到文章开头提到的我正在琢磨的服务,就是你不用操作本文提到的任何内容,仅仅通过服务的页面输入你感兴趣的域名,你将获得该域名下所有页面,并且保持同步更新。如果你是代码编写者,不妨考虑做一个类似市场上流行的爬虫客户端,只需将内容从HTML中提取出来,最终用户不知道后面发生了什么。所以你也可以写上类似“百万量级的轻松抓取”的广告词。
















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









