







先附上测试代码:
采用spring的junit测试工具,
@org.junit.Test
public void test1() throws InterruptedException {
CountDownLatch startSignal = new CountDownLatch(1);
CountDownLatch doneSignal = new CountDownLatch(3000);
for (int i = 0; i < 3000; i++) {
new Thread(new Worker(startSignal,doneSignal)).start();
}
System.out.println("准备。。。");
long beginTime = System.currentTimeMillis();
startSignal.countDown();
System.out.println("线程开始执行");
doneSignal.await();
long endTime = System.currentTimeMillis();
System.out.println("线程执行结束:"+(endTime-beginTime));
}
//核心工作类
class Worker implements Runnable {
private final CountDownLatch startSignal;
private final CountDownLatch doneSignal;
Worker(CountDownLatch startSignal, CountDownLatch doneSignal) {
this.startSignal = startSignal;
this.doneSignal = doneSignal;
}
public void run() {
try {
startSignal.await();
doWork();
doneSignal.countDown();
} catch (InterruptedException ex) {} // return;
}
void doWork() {
System.out.println(Thread.currentThread().getName());
studentService.queryStudent();
}
}同时开启1000写,测试结果:
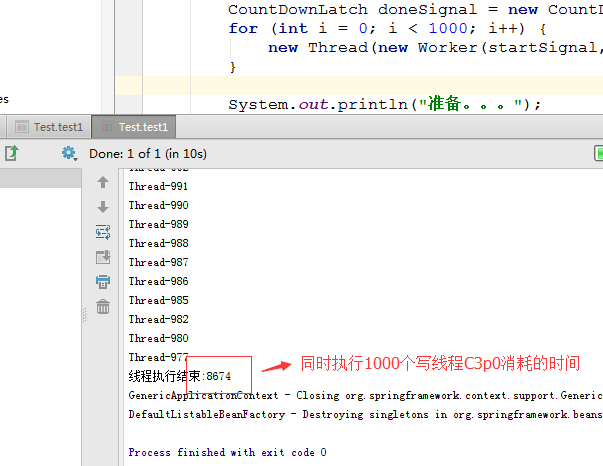

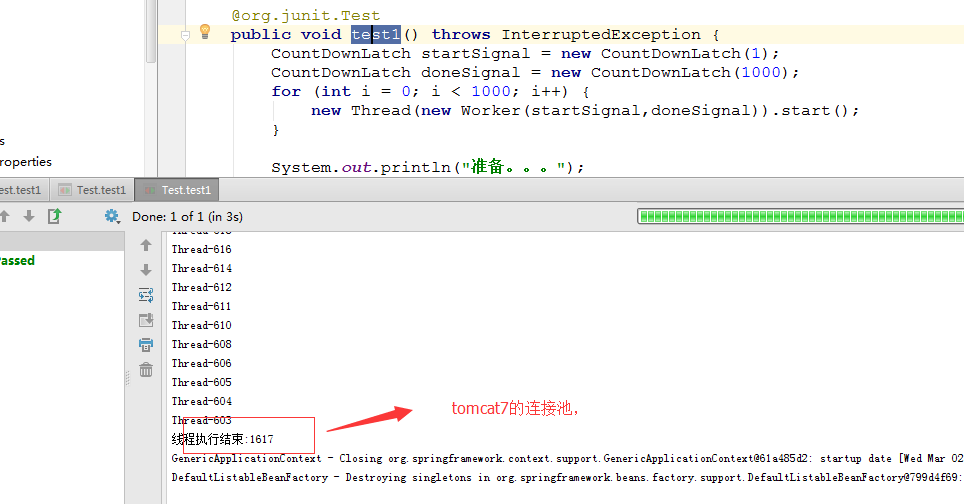
从图中可以看出,c3p0的性能被完爆。druid的性能优于tomcat的写。
下面测试3000个并发读:
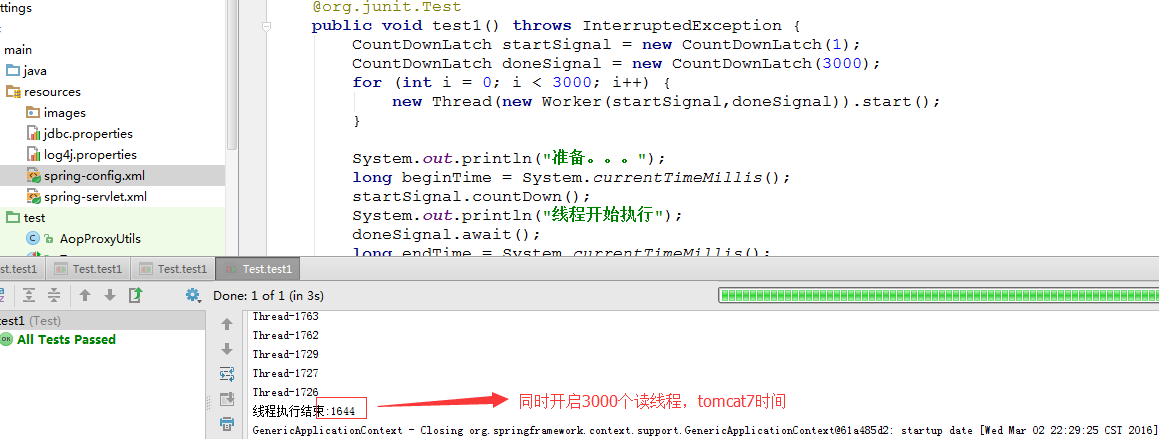
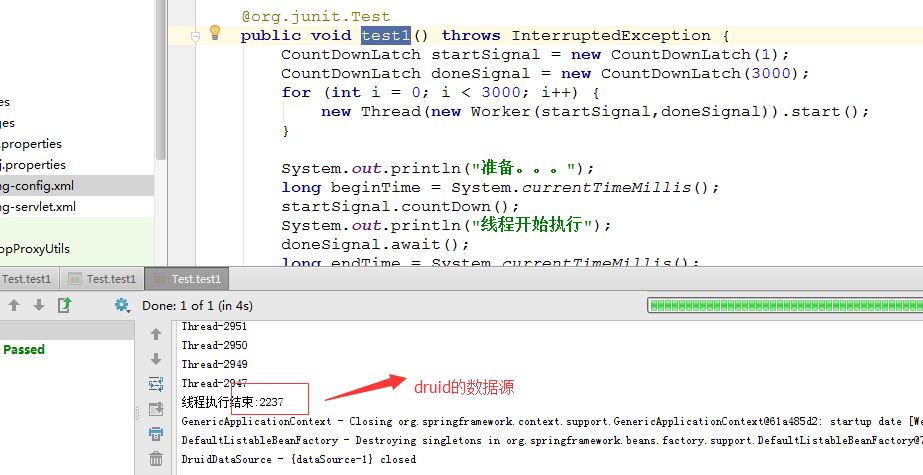

从图中可以看出,tomcat的连接池性能和c3p0的读取差不多,稍微好一点。druid的读性能稍微差。















 226
226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









