







运行代码如下
package spark.DataDimensionReduction
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.linalg.distributed.RowMatrix
import org.apache.spark.{SparkConf, SparkContext}
/**
* 数据降维
* 主成分分析PCA
* 设法将原来具有一定相关行(比如 P个指标)的指标
* 重新组合成一组新的互相无关的综合指标来代替原来的指标,从而实现数据降维的目的
* Created by eric on 16-7-24.
*/
object PCA {
val conf = new SparkConf() //创建环境变量
.setMaster("local") //设置本地化处理
.setAppName("PCA") //设定名称
val sc = new SparkContext(conf)
def main(args: Array[String]) {
val data = sc.textFile("./src/main/spark/DataDimensionReduction/a.txt")
.map(_.split(" ").map(_.toDouble))
.map(line => Vectors.dense(line))
val rm = new RowMatrix(data)
val pc = rm.computePrincipalComponents(3)//提取主成分,设置主成分个数为3
val mx = rm.multiply(pc)//创建主成分矩阵
mx.rows.foreach(println)
}
}
a.txt
1 2 3 4 5 6 7 8 9 0 8 7 6 4 2 1
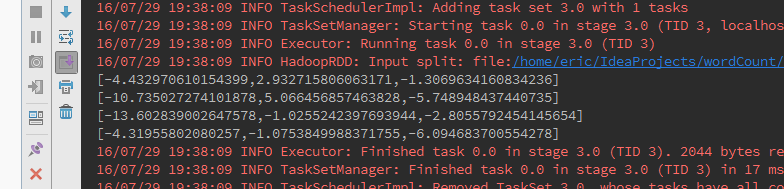
结果如下















 422
422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









