






想请教一下python2.7下字符编码的两个问题。
python2.7爬虫爬取一个utf-8的中文网页,为了对防止乱码首先decode(‘utf-8’)转化为unicode。然后如果将这些unicode编码的内容保存到文件的时候有调用encode(‘utf-8’)以utf-8编码保存有没有必要?# -*-coding:utf-8 -*-的作用是不是保存当前.py文件为utf-8编码?
1.有必要
decode(‘utf-8’)的作用是将utf8编码的字符串解码为unicode,而unicode是python最接受的字符串编码格式,不会因为各个工具库对字符编码处理不好而带来问题。
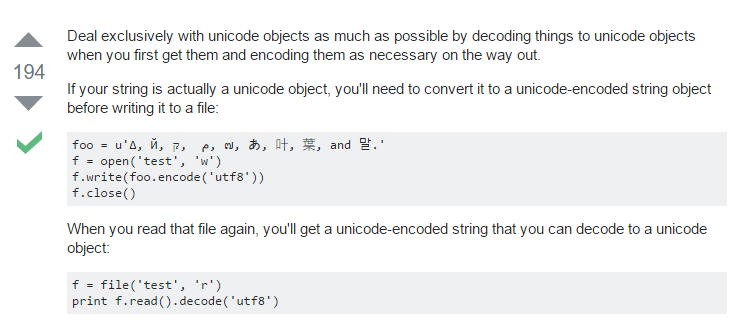
2.是的
coding:utf-8的作用是指定当前这个python代码文件里面所有字符串的编码
1、没必要。仅保存网页,只要将respone.read()获得的字节对象以二进制模式写入文件即可。
2、是的。
1.如果你用的Python2的话,不是有没有必要,而是必须。 Unicode只能存在与内存中,保存到文件需要编码为utf-8或者gbk啊等等, 不然肯定报错的
是的,因为不声明的话,默认是Ascii的格式,那样比如文件中出现中文就会报错,比如中文注释
python 3版本已经将默认编码格式ASCII改了
建议你看一看廖雪峰这篇关于字符串编码的教程,字符串和编码。 看完就会知道 utf-8,unicode 之间联系。
保存文件时是否必要encode为utf-8
这个两种都可以,纯粹看你的希望以哪种编码存储文件,以及那种编码后续处理更方便。
只不过write unicode字符串时,最好使用codes.open来打开文件并设置编码。
源代码编码定义(# –-coding:utf-8 –-)的作用
告诉python编译器如何解码代码文件,但并不能保证文件的实际编码一定与之匹配。
实际文件的编码还是由编辑器决定的(有些编辑器可能会识别# –-coding:utf-8 –-,并进行相应的编码存储)。
举个例子,我的vim的fileencoding设置为utf-8,但py文件编码设置为ascii(-– coding:ascii –-)。
这时我的py文件的实际编码为utf-8,但python编译器会按ascii来解析源文件,如果遇到非ascii字符就会抛异常:
SyntaxError: ‘ascii’ codec can’t decode byte 0xe4 in position 5: ordinal not in range(128)
unicode 与 utf-8 的关系
unicode 是 character set
character set 是把每个字符对应成数字的集合,比如unicode中 A对应0041,汉字『我』对应 ‘6211’
unicode 是个很大的集合,几乎覆盖世界上所有的字符,现在的规模已经可以容纳100万个字符。
utf-8 是对 unicode 存储的实现方式
unicode 只定义字符对应的数字,但没有规定这些数字如何存储起来,比如像中文的『我』字存储时需要两个字节来表示,而英文字母A却只需要一个字节,有些其他的字符可能需要3-4个字节。
如果统一规定每个字符用3个或者4个字节来存储,那么每个英文字符都必然需要额外2到3个0,这对存储是很大的浪费。
如果每个字符按照实际需要的字节数来存储,计算机就分不清三个字节是表示三个字符还是一个字符。
utf-8 是对 unicode 编码存储的一种实现方式,同样的还有 utf-16, utf-32。
utf-8 是使用最广泛的编码方式,采用变长的编码方式,可以使用1-4个字节来表示一个字符; utf-16 用2个或4个字节,utf-32 用4个字节表示。编码规则如下:
对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母, UTF-8编码和ASCII码是相同的。
对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
python2 中的 str 和 unicode
python2 中有字符串类型有两种:
byte string (str)
和
unicode string (unicode)
。
>>> s = '美的'
>>> s
'\xe7\xbe\x8e\xe7\x9a\x84'
>>> s = u'美的'
>>> s
u'\u7f8e\u7684'
>>> s = '美的'
>>> s.decode('utf-8')
u'\u7f8e\u7684'
上面的输出中,第一个s的类型是 str,打印出来的内容是 utf-8 编码过的内容。第二个s的类型是 unicode,打印出来的两个双字节的数字分别表示了两个汉字『美的』。
encode
和
decode
提供 str 和 unicode 这两种的类型的互相转化。
encode 把 unicode 转化成 str(byte string)
decode 把 str(byte string) 转化成 unicode
本质上,str是存放的字节序,有可能是 ascii, gbk, utf-8 等等中的任意一种,通过调用 decode 可以把他们转化成 unicode ,默认的 decode 编码是 ascii 。str中到底是用的哪一种编码,取决于它所在的场景,跟 locale ,文件编码等等都有关系。
文本文件、编辑器的处理
#!/usr/bin/env python
# -*- coding: GBK -*-
s = u'中文'
print repr(s)
print repr(s.encode('GBK'))
比如上面的文件
enc.py
,保存的时候选择
文件编码
是GBK,程序文件本质上也是文件,当我们使用某个外部的应用 打开它时(编辑器或者python解释器等),外部应用是不知道该文件的编码格式的,
这个时候有三种情况:
应用使用其默认的编码方式去解析,比如UTF-8或者ASCII;python解释器默认是ASCII,编辑器可以自己设置;
应用根据文件中的字节内容,自动检测编码方式;
文本文件告诉应用使用什么编码方式去解码;比如
# -*- coding: GBK -*-
告知解释器使用GBK来解码;
试验一下,把
# -*- coding: GBK -*-
删除后,执行
python enc.py
,输出:
File "enc.py", line 4
SyntaxError: Non-ASCII character '\xd6' in file enc.py on line 4, but no encoding declared;
试着用vim打开该文件时,『中文』两个字就会显示成乱码,因为vim默认的文件编码方式被设置成UTF-8了。
#!/usr/bin/env python
# -*- coding: GBK -*-
s1 = u'中文'
print repr(s1)
print repr(s1.encode('GBK'))
s2 = '中文'
print repr(s2)
print repr(s2.decode('GBK'))
输出结果:
u'\u4e2d\u6587'
'\xd6\xd0\xce\xc4'
'\xd6\xd0\xce\xc4'
u'\u4e2d\u6587'
从这里可以看出来, s2中存放的是byte格式的从文件中读到的GBK编码的内容。
再看下面的这段代码,程序文件
utf8_enc.py
,保存成UTF-8编码的。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
s1 = u'中文'
print repr(s1)
print repr(s1.encode('GBK'))
s2 = '中文'
print repr(s2)
print repr(s2.decode('GBK'))
输出:
u'\u4e2d\u6587'
'\xd6\xd0\xce\xc4'
'\xe4\xb8\xad\xe6\x96\x87'
Traceback (most recent call last):
File "unicode_enc.py", line 12, in <module>
print repr(s2.decode('GBK'))
UnicodeDecodeError: 'gbk' codec can't decode bytes in position 2-3: illegal multibyte sequence
这里同样可以知道,s2中存放的是文件保存的编码UTF-8的byte码。
References
http://www.rrn.dk/the-differe…
http://www.ruanyifeng.com/blo…
https://docs.python.org/2/how…
http://yergler.net/2012/bytes…















 1765
1765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









