






用imagemagick和tesseract-ocr破解简单验证码
Tesseract-ocr据说辨识程度是世界排名第三,可谓神器啊。
准备工作:
1.安装tesseract-ocr
- sudo apt-get install tesseract
2.安装imagemagick
- sudo apt-get install imagemagick
3.安装rmagick
- sudo apt-get remove --purge librmagick-ruby-doc librmagick-ruby1.8
- sudo apt-get install libmagick9-dev ruby1.8-dev
- sudo gem install rmagick
先试一个简单的:
- require 'rubygems'
- require 'rtesseract'
- img = RTesseract.new("tmp/test.jpg")
- img.to_s.sub(/\s+$/, "") # => "3R8Z"
很成功,但这个太简单了。一般破解复杂点的验证码处理步骤是先用imagemagick灰度化,灰度反转,提高对比度,二值化等。然后再用ocr去识别。ocr识别黑白图片效果比较好些。
这个是人民网的验证码:![]()
- img = MiniMagick::Image.new("tmp/people.jpg")
- img.colorspace("GRAY")#灰度化
- image = RTesseract.new(img.path)
- image.to_s.sub(/\s+$/, "") # => "254369"
这个还是简单,再复杂一点的,这个是4399.com的验证码:![]()
有黑色边框,有背景色,文字稍微扭曲。
- img = MiniMagick::Image.new("tmp/4399.jpg")
- img.crop("#{img[:width] - 2}x#{img[:height] - 2}+1+1") #去掉边框(上下左右各1像素)
- img.colorspace("GRAY") #灰度化
- img.monochrome #二值化
- image = RTesseract.new(img.path) #ocr识别
- image.to_s.sub(/\s+$/, "") #=> "5692"
像上面这样简单的识别率几乎能达到80%以上,扭曲太严重的识别率就很低了。有轻微噪点的就得自己写去噪算法了。。
还有一些验证码看起来很变态但是是纸老虎。像当当的 。刷新了几次发现结果在1-20之间,选中一个数暴力破解每次也有1/20正确的概率。
。刷新了几次发现结果在1-20之间,选中一个数暴力破解每次也有1/20正确的概率。
还有139的: 。答案就12种1-4A-Da-d。而且不区分大小写。选中一个字母每次有1/6的概率命中。
。答案就12种1-4A-Da-d。而且不区分大小写。选中一个字母每次有1/6的概率命中。
下载jTessBoxEditor用于修改box文件
下载地址:http://download.csdn.net/detail/a443475601/5896893 里面自带java运行库,安装后 然后启动命令行 java -jar jTessBoxEditor.jar即可打开
为了方便 tif文面命名格式[lang].[fontname].exp[num].tif
lang是语言 fontname是字体
比如我们要训练自定义字库 chi 字体名:黑体
那么我们把tif文件重命名 chi.黑体.exp0.tif
把多个.tif文件合并成一个.tif文件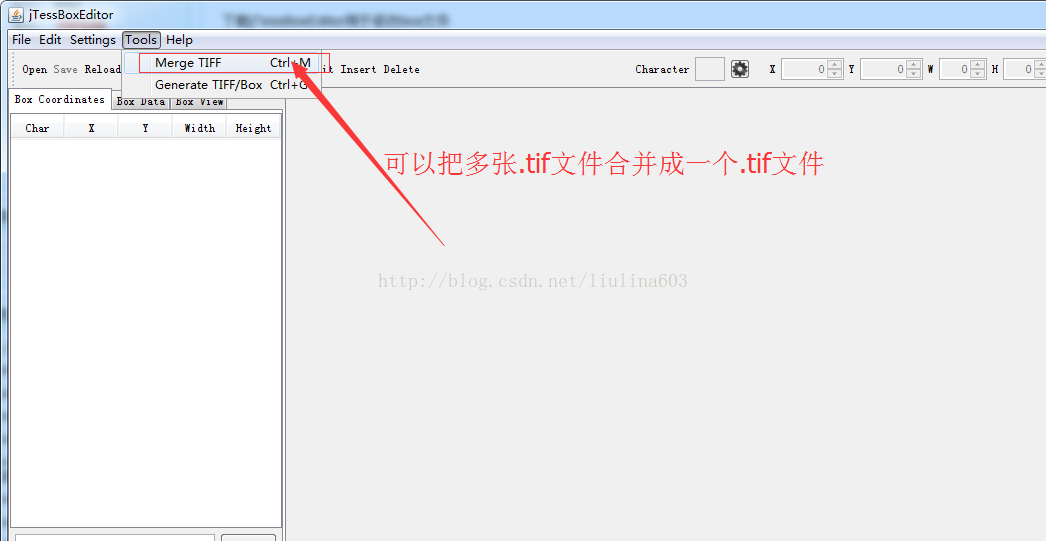
下面开始训练字库:
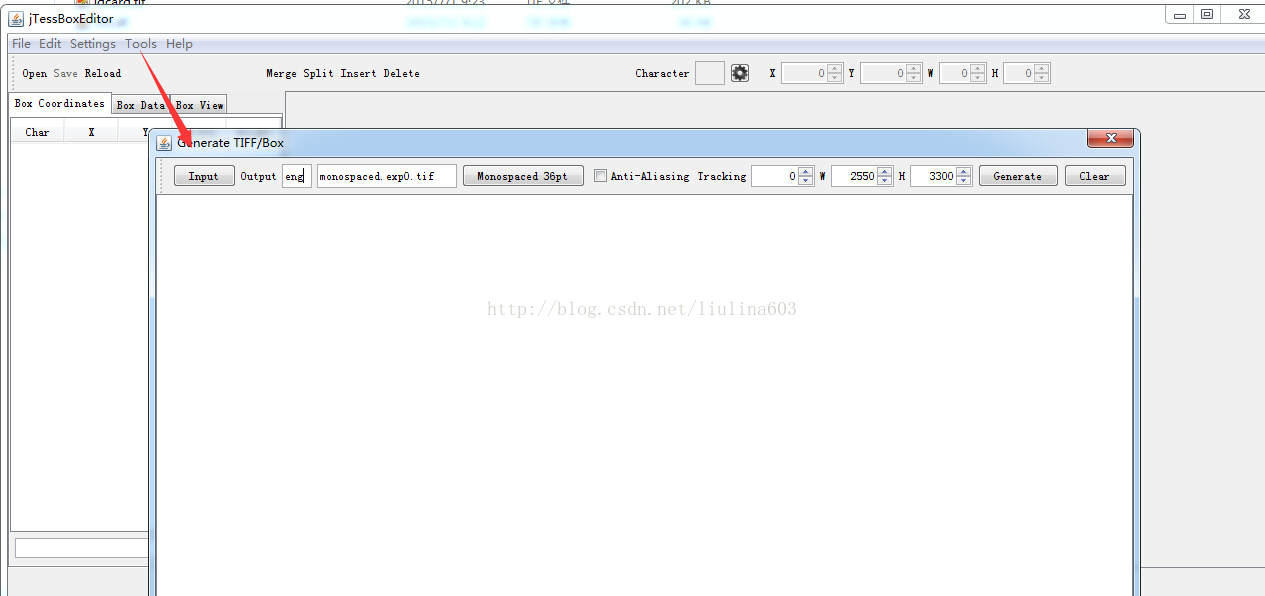
下面第一条命令与上图功能一样,产生.box文件
1、E:\Tesseract-ocr\tesseract.exe chi.黑体.exp0.tif chi.黑体.exp0 batch.nochop makebox
运行以上命令也会产生一个box文件。产生box文件的过程是必须的,也是最重要的,没有box文件以下的内容都无法进行。
需要记住的是生成的.box要和这个.tif文件同在一个目录下。
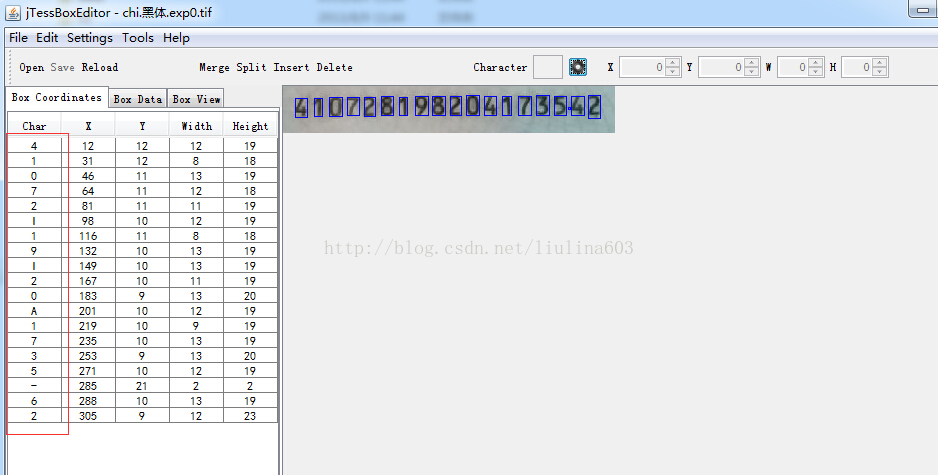
2、文字校正。运行jTessBoxEditor工具,打开chi.黑体.exp0.tif文件(必须将上一步生成的.box和.tif样本文件放在同一目录),如上图所示。可以看出有些字符识别的不正确,可以通过该工具手动对每张图片中识别错误的字符进行校正。校正完成后保存即可。
2、产生字符特征文件
tesseract chi.黑体.exp0.tif chi.黑体.exp0 nobatch box.train
这一步将会产生 chi.黑体.exp0.tr文件和一个 chi.黑体.exp0.txt文件,txt文件貌似没什么用,看看而以。
3、计算字符集
unicharset_extractor chi.黑体.exp0.box
这一步会产生一个unicharset字符集文件.
4、定义字体特征文件,---Tesseract-OCR3.01以上的版本在训练之前需要创建一个名称为font_properties.txt的字体特征文件
手工建立一个文件font_properties.txt
内容如:黑体 0 0 0 0 0
注意:这里 必须与训练名中的名称保持一致,填入下面内容 ,这里全取值为0,表示字体不是粗体、斜体等等。
5、聚集字符特征
1) shapeclustering -F font_properties.txt -U unicharset chi.黑体.exp0.tr 注意:如果font_properties不加扩展名.txt,可能会报错
2) mftraining -F font_properties.txt -U unicharset -O chi.unicharset chi.黑体.exp0.tr
使用上一步产生的字符集文件unicharset,来生成当前新语言的字符集文件chi.unicharset。同时还会产生图形原型文件inttemp和每个字符所对应的字符
特征数文件pffmtable。最重要的就是这个inttemp文件了,他包含了所有需要产生的字的图形原型。
3)cntraining chi.黑体.exp0.tr
这一步产生字符形状正常化特征文件normproto。
6、把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件前面都加上chi.
7、执行combine_tessdata chi.
然后把chi.traineddata放到tessdata目录
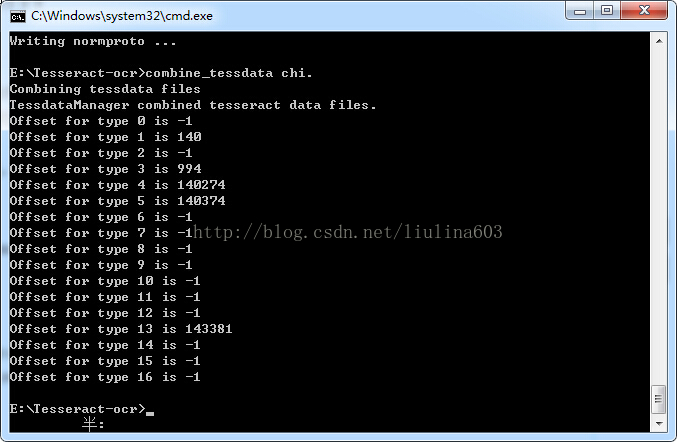
必须确定的是第2、4、5、6行的数据不是-1,那么一个新的字典就算生成了.
8、用新的字库对图片进行分析
tesseract test.tif output -l chi
内容会写到output.txt文件中,这个文件与测试图片在同一个目录下
识别问题:
1、一个字分成2部分识别,如:好,会认为女 子,如何解决???















 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









