






Hive不同文件的读取对照
stored as textfile
直接查看hdfs
hadoop fs -text
hive> create table test_txt(name string,val string) stored as textfile;
stored as sequencefile
hadoop fs -text
hive> create table test_seq(name string,val string) stored as sequencefile;
stored as rcfile
hive –service rcfilecat path
hive> create table test_rc(name string,val string) stored as rcfile;
stored as inputformat ‘class’自己定义
outformat ‘class’
基本步骤:
1、编写自己定义类
2、打成jar包
3、加入jar文件,hive> add jar /***/***/***.jar(当前生效)或者复制到hive安装文件夹的lib文件夹下。重新启动client(永久生效)。
4、创建表,指定自己定义的类
Hive使用SerDe
SerDe是”Serializer”和”Deserializer”的简写。
Hive使用SerDe(和FileFormat)来读、写表的行。
读写数据的顺序例如以下:
HDFS文件-->InputFileFormat--><key,value>-->Deserializer-->Row对象
Row对象-->Serializer--><key,value>-->OutputFileFormat-->HDFS文件Hive自带的序列化与反序列化
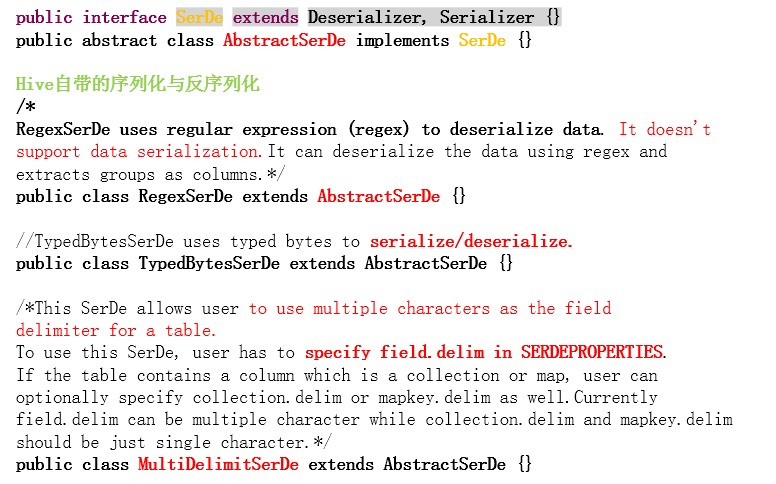
当然我们也能够自己实现自己定义的序列化与反序列化
Hive自己定义序列化与反序列化步骤
1、实现接口SerDe或者继承AbstractSerDe抽象类
2、重写里面的方法
Demo:
创建表
drop table apachelog;
create table apachelog(
host string,
identity string,
user string,
time string,
request string,
status string,
size string,
referer string,
agent string
)
row format serde 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
with serdeproperties(
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([0-9]*) ([0-9]*) ([^ ]*) ([^ ]*)"
)stored as textfile;
cat serdedata
110.52.250.126 test user - GET 200 1292 refer agent
27.19.74.143 test root - GET 200 680 refer agent载入数据
load data local inpath '/liguodong/hivedata/serdedata' overwrite into table apachelog;查看内容
select * from apachelog;
select host from apachelog;















 1386
1386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









