







本篇是游戏开发系列第三篇,如若你有兴趣,请持续关注,后期会持续更新。其他文章列表如下:
如果你有看过上一篇《游戏开发-协议设计-protobuf》,就会了解到prtobuf的what和how,那么这一篇主要分析一下why的问题,protobuf为何解析速度快,占用空间小,以及兼容性好,它是如何做到的,我们将从 占用空间,解析速度,兼容三个问题着手进行分析。
上一篇发出后也有同学留言,说直接二进制read和write比protobuf会节省空间,某种程度上他说的对,但是需要在极端条件下才成立,一般情况下protobuf 还是比二进制序列化节省空间的,具体为何,以下会详细介绍。
占用空间
一条消息数据,用protobuf序列化后的大小是json的10分之一,xml格式的20分之一,是二进制序列化的10分之一(极端情况下,会大于等于直接序列化),总体看来ProtoBuf的优势还是很明显的。那么protobuf是如何做到的,我们主要从以下4个方面进行分析。
1、数据紧凑
相对于json或者xml,protobuf没有定义标签,直接生成的二进制,令消息非常紧凑,这个和我们直接定义消息,然后顺序解析二进制数据相似。期间没有多余的数据。
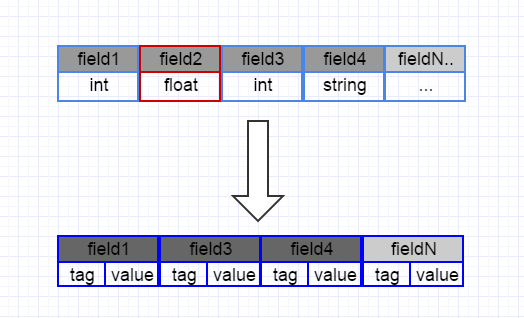
一个message的信息结构如下:

每个field由一个tag和value组成,每个field之间在字节流中紧密相连,这意味着消息的信息没用冗余,保持最紧凑的样子。
2、剔除无效字段
剔除无值字段一般json和xml这种标签式结构数据在序列化的时候也会处理,同样protobuf也做了处理。我们先看一下一个常规定义的的二进制信息:

此种常规定义,可以对数据顺序写入,然后再顺序读取,也支持数据的序列化。但会带来一个问题,某些字段没有赋值的情况下,不得不传一个默认值。比如field3的值是一个int,占位4个字节。如果client的field2没有赋值,而不写入一个默认值(比如0),那么server解包就会偏移量就会出错,最终整个包的数据读不出。
protobuf 是如何解决这个问题,因为它引入了tag。
我们看下tag的组成。
static int makeTag(final int fieldNumber, final int wireType) {
return (fieldNumber << 3) | wireType;
}tag是由:fieldNumber和wireType组成,fieldNumber定义字段的标识位,以此来处理写入和读取顺序,wireType定义字段类型,以此来定义单个field的占用字节大小。
wireType 可以支持的类型如下:

我们看下每个的field解析方式:
boolean done = false;
while (!done) {
//读取tag
int tag = input.readTag();
switch (tag) {
case 0:
done = true;
break;
default: {
if (!input.skipField(tag)) {
done = true;
}
break;
}
case tag1: {
//读取value
a_ = input.readFloat();
break;
}
}读取field的时候,先读取tag,然后基于tag知道value的数据类型,获取value。write也一样,单个field的写入也是先写入tag再写入value。
因为每个field都定义了tag,如若field没有赋值,编码的时候它的tag不会被写入流中,相应也不会有它的value,如此解析期间因为没有此字段的tag,可以直接无视,读取其他field。如此去除无效字段之后,可以有效的节省空间。
比如上述的常规定义的的二进制信息,在field2没有赋值的情况下,protobuf可以如此处理。
3、Varints & Zigzag
Varints
我们在上面的wireType中也看到有一种Varint类型的field定义,这是要说第三个特点。
Varint 是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。我们看下它的算法:
public final void writeUInt32NoTag(int value) throws IOException {
if (HAS_UNSAFE_ARRAY_OPERATIONS && spaceLeft() >= MAX_VARINT_SIZE) {
long pos = ARRAY_BASE_OFFSET + position;
while (true) {
if ((value & ~0x7F) == 0) {
UnsafeUtil.putByte(buffer, pos++, (byte) value);
position++;
return;
} else {
UnsafeUtil.putByte(buffer, pos++, (byte) ((value & 0x7F) | 0x80));
position++;
value >>>= 7;
}
}
} else {
try {
while (true) {
if ((value & ~0x7F) == 0) {
buffer[position++] = (byte) value;
return;
} else {
buffer[position++] = (byte) ((value & 0x7F) | 0x80);
value >>>= 7;
}
}
} catch (IndexOutOfBoundsException e) {
throw new OutOfSpaceException(
String.format("Pos: %d, limit: %d, len: %d", position, limit, 1), e);
}
}
}我们知道, int32数据类型 ,一般需要4 个 字节 来表示,采用 Varint编码之后,对于很小的 int32 类型的数字,比如小于127的,则可以用 1 个 字节 来存储,小于255的2个字节来存储,依次类推,最优占用字节的大小。当然这也有不好的一面,采用 Varint 表示法,太大的数字则需要 5 个 byte 来表示。不过一般不会所有的消息中的数字都是大数,而且大数的概率比较低,所以大多数情况下,采用 Varint 后,可以用更少的字节数来表示数字信息。
ZigZag
我们知道有符号的整型数值,因为采用的是补码,所以一个负数会比正数占用的字节多,比如-1,二进制结构是11111111 11111111 11111111 11111111,如果我们还是采用 Varint 表示一个负数,那么需要 5 个 byte。为此 protobuf 定义了 sint32 ,采用 zigzag 编码。
我们看下zigzag的算法:
public static int encodeZigZag32(final int n) {
// Note: the right-shift must be arithmetic
return (n << 1) ^ (n >> 31);
}Zigzag 编码用无符号数来表示有符号数字,正数和负数交错,无论正负都可以采用较少的 byte 来表示。
4、字符串
一般单个字符串的定义,需要两个部分组成:leg+value ,如下图所示:

leg 表示字符串数据的长度,value是字符串真实数据,protobuf里面这个leg 采用Varint定义,一般情况下一个字节足够了。
解析速度
解析速度快,主要归功于protobuf对message 没有动态解析,没有了动态解析的处理序列化速度自然快了。就比如xml ,获取文件之后,还需要解析标签、节点、字段,每一个都需要遍历,而protobuf不需要,直接将field装入流。
我们知道.proto文件定义了整个message的结构,但这只是一个定义的配置文件,结合compiler的使用,单个message的read和write代码已经被生成,无需再基于配置文件解析,直接操作field到二进制流里面,这个速度就好比你直接操作IO一样快,没有其他代价。
我们看下生成的message代码(还是LoginMsg)
write
public void writeTo(com.google.protobuf.CodedOutputStream output)
throws java.io.IOException {
if (!getUseranmeBytes().isEmpty()) {
com.google.protobuf.GeneratedMessageV3.writeString(output, 1, useranme_);
}
if (pwd_ != 0) {
output.writeInt32(2, pwd_);
}
}read
boolean done = false;
while (!done) {
int tag = input.readTag();
switch (tag) {
case 0:
done = true;
break;
default: {
if (!input.skipField(tag)) {
done = true;
}
break;
}
case 10: {
java.lang.String s = input.readStringRequireUtf8();
useranme_ = s;
break;
}
case 16: {
pwd_ = input.readInt32();
break;
}
}
}我们看到,read的代码中tag的生成(转换为int)也已经帮你处理,所以都是基于流直接操作。
兼容性
兼容性什么意思,就是说message需要支持向上兼容,不能说单个message的升级,就会导致old message解析出错,这是我们不能忍受的,开发过程中,需求总变,谁都无法保证协议不会有变更。
比如这种场景下:message 需要增加一个字段,如若client没有升级,sever升级了,此时client 请求的message格式必定是old 格式,server 采用的new message来解析,此时会出现找不到新字段的问题,流数据错乱之后,后续的数据都会乱。
那么protobuf是如何处理?这时候fieldNumber就派上用途了,看似可又可无的设计,其实包含很大用处。
fieldNumber 为每个field定义一个编号,其一保证不重复,其二保证其在流中的位置。如若当前数据流中有某个字段,而解析方没有相关的解析代码,解析放会直接skip 吊这个field,而且读数据的position也会后移,保证后续读取不出问题。
boolean done = false;
while (!done) {
int tag = input.readTag();
switch (tag) {
case 0:
done = true;
break;
// 解析方没有这个field的解析方法,skip掉
default: {
if (!input.skipField(tag)) {
done = true;
}
break;
}
}
}如上,线读取tag,某个字段没有被赋值,就没有这个字段的tag,解析方不处理,如若有某个字段,而没有解析方法,就skip了,不影响消息的处理。老数据依然被获取。
---------------------------------------------------end---------------------------------------------------
扫描关注更多,关注个人成长和技术学习,期待用自己的一点点改变,带给你一些启发及感悟。
















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









