







1.SELECT
[hadoop@hadoop05 data]$ hadoop fs -ls hdfs://192.168.199.105:9000/user/hive/warehouse/hive2_gordon.db/gordon_emp;
Found 1 items
-rwxr-xr-x 1 hadoop supergroup 700 2018-06-14 21:36 hdfs://192.168.199.105:9000/user/hive/warehouse/hive2_gordon.db/gordon_emp/emp.txt
hive> select * from gordon_emp;
hive> desc extended gordon_emp;
OK
hive> desc formatted gordon_emp;
####简单语句不走mapreduce
hive> use hive2_gordon;
OK
Time taken: 0.355 seconds
hive> select * from gordon_emp where ename ='SCOTT';
OK
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
Time taken: 2.326 seconds, Fetched: 1 row(s)
hive> select * from gordon_emp where empno >'7500';
OK
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
8888 HIVE PROGRAM 7839 1988-1-23 10300.0 NULL NULL
Time taken: 0.454 seconds, Fetched: 13 row(s)
hive> select * from gordon_emp where salary between 800 and 1500;
OK
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
Time taken: 0.394 seconds, Fetched: 7 row(s)
hive> select * from gordon_emp limit 5;
OK
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
Time taken: 0.242 seconds, Fetched: 5 row(s)
hive> select * from gordon_emp where ename in ('SCOTT');
OK
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
Time taken: 0.22 seconds, Fetched: 1 row(s)
hive> select * from gordon_emp where comm is null;
OK
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
8888 HIVE PROGRAM 7839 1988-1-23 10300.0 NULL NULL
Time taken: 0.413 seconds, Fetched: 11 row(s)
hive>
2.聚合函数
聚合函数对一组值执行计算,并返回单个值。"多进一出"
max/min/count/sum/avg
聚合函数走mapreduce。
hive>select avg(salary),max(salary),min(salary) ,sum(salary)from gordon_emp;
Query ID = hadoop_20180615224545_4f9c5c70-7aed-4745-a503-ff5e4a3dfe90
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2018-06-15 22:48:31,340 Stage-1 map = 0%, reduce = 0%
2018-06-15 22:48:33,612 Stage-1 map = 100%, reduce = 0%
2018-06-15 22:48:34,656 Stage-1 map = 100%, reduce = 100%
Ended Job = job_local187248363_0001
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 9800 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
2621.6666666666665 10300.0 800.0 39325.0
Time taken: 8.633 seconds, Fetched: 1 row(s)
####分组函数 group by
求每个部门的平均工资
hive>select deptno, avg(salary) from gordon_emp group by deptno;
NULL 10300.0
10 2916.6666666666665
20 2175.0
30 1566.6666666666667
Time taken: 2.968 seconds, Fetched: 4 row(s)
hive>select deptno,ename, avg(salary) from gordon_emp group by deptno;
FAILED: SemanticException [Error 10025]: Line 1:14 Expression not in GROUP BY key 'ename'
注意:select中出现的字段,如果没有出现在组函数/聚合函数中,必须出现在group by里面
求每个部门(deptno)、工作岗位(job)的最高工资(salary)
hive>select deptno,job, avg(salary) from gordon_emp group by deptno,job;
NULL PROGRAM 10300.0
10 CLERK 1300.0
10 MANAGER 2450.0
10 PRESIDENT 5000.0
20 ANALYST 3000.0
20 CLERK 950.0
20 MANAGER 2975.0
30 CLERK 950.0
30 MANAGER 2850.0
30 SALESMAN 1400.0
Time taken: 7.369 seconds, Fetched: 10 row(s)
求每个部门的平均工资大于2000的部门
hive>select deptno, avg(salary) from gordon_emp group by deptno where avg(salary)>2000;
FAILED: ParseException line 1:60 missing EOF at 'where' near 'deptno'
hive>select deptno, avg(salary) from gordon_emp group by deptno having avg(salary)>2000;
NULL 10300.0
10 2916.6666666666665
20 2175.0
Time taken: 2.434 seconds, Fetched: 3 row(s)
注意:where是需要写在group by之前,where和having的执行位置。聚合之后就不能用where
3.case when
分类
select ename,salary,
case
when salary>1 and salary<=1000 then 'lower'
when salary>1000 and salary<=2000 then 'middle'
when salary>2000 and salary<=4000 then 'high'
else 'highest'
end
from gordon_emp ;
SMITH 800.0 lower
ALLEN 1600.0 middle
WARD 1250.0 middle
JONES 2975.0 high
MARTIN 1250.0 middle
BLAKE 2850.0 high
CLARK 2450.0 high
SCOTT 3000.0 high
KING 5000.0 highest
TURNER 1500.0 middle
ADAMS 1100.0 middle
JAMES 950.0 lower
FORD 3000.0 high
MILLER 1300.0 middle
HIVE 10300.0 highest
Time taken: 0.329 seconds, Fetched: 15 row(s)
4.Join
join_a.txt join
1 gordon
2 j
3 k
join_b.txt
1 30
2 29
4 21
create table a(
id int, name string
) row format delimited fields terminated by '\t';
create table b(
id int, age int
) row format delimited fields terminated by '\t';
load data local inpath '/home/hadoop/data/join_a.txt' overwrite into table a;
load data local inpath '/home/hadoop/data/join_b.txt' overwrite into table b;
####笛卡尔积
hive> select * from a join b;
1 gordon 1 30
1 gordon 2 29
1 gordon 4 18
2 j 1 30
2 j 2 29
2 j 4 18
3 k 1 30
3 k 2 29
3 k 4 18
Time taken: 28.875 seconds, Fetched: 9 row(s)
inner join = join
hive>select a.id ,a.name,b.age from a left join b on a.id = b.id;
1 gordon 30
2 j 29
3 k NULL
Time taken: 34.857 seconds, Fetched: 3 row(s)
hive>select a.id ,a.name,b.age from a right join b on a.id = b.id;
1 gordon 30
2 j 29
NULL NULL 18
hive>select a.id ,a.name,b.age from a full join b on a.id = b.id;
1 gordon 30
2 j 29
3 k NULL
NULL NULL 18
Time taken: 9.929 seconds, Fetched: 4 row(s)
LEFT SEMI JOIN 是 IN/EXISTS 子查询的一种更高效的实现。
Hive 当前没有实现 IN/EXISTS 子查询,所以你可以用 LEFT SEMI JOIN 重写你的子查询语句。
LEFT SEMI JOIN 的限制是, JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行。
hive>select * from a left semi join b on a.id =b.id;
1 gordon
2 j
Time taken: 32.552 seconds, Fetched: 2 row(s)
5.分区表 partition
日志:who when what 一般日志表比较大
click_log
click_log_yyyyMMdd
分区表存在的意义:
hive hdfs + partition <== 通过where partition 指定分区
==> reduce io 降低IO
静态分区-单级分区
create table order_partition(
ordernumber string,
eventtime string
)
partitioned by (event_month string)
row format delimited fields terminated by '\t';
HIVE清屏!clear
加载数据:
LOAD DATA LOCAL INPATH '/home/hadoop/data/order.txt'
OVERWRITE INTO TABLE order_partition
PARTITION(event_month='2014-05');
查看hive日志

解决方案:mysql下面执行。
Use gordon;
alter table PARTITIONS convert to character set latin1;
alter table PARTITION_KEYS convert to character set latin1;
重新加载:
查看HDFS上的数据。
[hadoop@hadoop05 sbin]$ hadoop fs -ls /user/hive/warehouse/hive2_gordon.db/order_partition;
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2018-06-15 23:28 /user/hive/warehouse/hive2_gordon.db/order_partition/event_month=2014-05
hive> select * from order_partition where event_month='2014-05';
OK
10703007267488 2014-05-01 06:01:12.334+01 NULL 2014-05
10101043505096 2014-05-01 07:28:12.342+01 NULL 2014-05
10103043509747 2014-05-01 07:50:12.33+01 NULL 2014-05
10103043501575 2014-05-01 09:27:12.33+01 NULL 2014-05
10104043514061 2014-05-01 09:03:12.324+01 NULL 2014-05
Time taken: 0.165 seconds, Fetched: 5 row(s)
hive>
####手工创建hdfs分区,hive没有数据。
[hadoop@hadoop05 sbin]$ hadoop fs -mkdir /user/hive/warehouse/hive2_gordon.db/order_partition/event_month=2014-06;
[hadoop@hadoop05 sbin]$ hadoop fs -put order.txt /user/hive/warehouse/hive2_gordon.db/order_partition/event_month=2014-06;
put: `order.txt': No such file or directory
[hadoop@hadoop05 sbin]$ cd /home/hadoop/data
[hadoop@hadoop05 data]$ hadoop fs -put order.txt /user/hive/warehouse/hive2_gordon.db/order_partition/event_month=2014-06;
[hadoop@hadoop05 data]$ hadoop fs -ls /user/hive/warehouse/hive2_gordon.db/order_partition/event_month=2014-06;
Found 1 items
-rw-r--r-- 1 hadoop supergroup 242 2018-06-15 23:36 /user/hive/warehouse/hive2_gordon.db/order_partition/event_month=2014-06/order.txt
hive>select * from order_partition where event_month='2014-06';
OK
Time taken: 0.237 seconds
####mysql元数据没有加载。
mysql> select * from partitions;
+---------+-------------+------------------+---------------------+-------+--------+
| PART_ID | CREATE_TIME | LAST_ACCESS_TIME | PART_NAME | SD_ID | TBL_ID |
+---------+-------------+------------------+---------------------+-------+--------+
| 1 | 1529076506 | 0 | event_month=2014-05 | 34 | 33 |
+---------+-------------+------------------+---------------------+-------+--------+
1 row in set (0.03 sec)
mysql> select * from partition_keys;
+--------+--------------+-------------+-----------+-------------+
| TBL_ID | PKEY_COMMENT | PKEY_NAME | PKEY_TYPE | INTEGER_IDX |
+--------+--------------+-------------+-----------+-------------+
| 33 | NULL | event_month | string | 0 |
+--------+--------------+-------------+-----------+-------------+
1 row in set (0.00 sec)
mysql> select * from partition_key_vals;
+---------+--------------+-------------+
| PART_ID | PART_KEY_VAL | INTEGER_IDX |
+---------+--------------+-------------+
| 1 | 2014-05 | 0 |
+---------+--------------+-------------+
1 row in set (0.00 sec)
解决方案一:
hive> MSCK REPAIR TABLE ORDER_PARTITION;
OK
Partitions not in metastore: order_partition:event_month=2014-06
Repair: Added partition to metastore ORDER_PARTITION:event_month=2014-06
Time taken: 0.56 seconds, Fetched: 2 row(s)
mysql去查看 就有了
mysql> select * from partitions;
+---------+-------------+------------------+---------------------+-------+--------+
| PART_ID | CREATE_TIME | LAST_ACCESS_TIME | PART_NAME | SD_ID | TBL_ID |
+---------+-------------+------------------+---------------------+-------+--------+
| 1 | 1529076506 | 0 | event_month=2014-05 | 34 | 33 |
| 2 | 1529077282 | 0 | event_month=2014-06 | 35 | 33 |
+---------+-------------+------------------+---------------------+-------+--------+
2 rows in set (0.00 sec)
注意:操作比较暴力,如果表时间长,执行很长时间
解决方案二:
hdfs上创建一个07分区
工作上建议方案:
ALTER TABLE order_partition ADD IF NOT EXISTS
PARTITION (event_month='2014-07') ;
mysql> select * from partitions;
+---------+-------------+------------------+---------------------+-------+--------+
| PART_ID | CREATE_TIME | LAST_ACCESS_TIME | PART_NAME | SD_ID | TBL_ID |
+---------+-------------+------------------+---------------------+-------+--------+
| 1 | 1529076506 | 0 | event_month=2014-05 | 34 | 33 |
| 2 | 1529077282 | 0 | event_month=2014-06 | 35 | 33 |
| 3 | 1529077487 | 0 | event_month=2014-07 | 36 | 33 |
+---------+-------------+------------------+---------------------+-------+--------+
3 rows in set (0.00 sec)
通过insert方法
create table order_4_partition(
ordernumber string,
eventtime string
)
row format delimited fields terminated by '\t';
load data local inpath '/home/hadoop/data/order.txt' overwrite into table order_4_partition;
insert overwrite table order_partition
partition(event_month='2014-08')
select * from order_4_partition;
查看表的分区:
hive> show partitions order_partition;
OK
event_month=2014-05
event_month=2014-06
event_month=2014-07
event_month=2014-08
Time taken: 0.197 seconds, Fetched: 4 row(s)
注意:分区的字段不能在表的字段中。
多级分区
create table order_mulit_partition(
ordernumber string,
eventtime string
)
partitioned by (event_month string,event_day string)
row format delimited fields terminated by '\t';
LOAD DATA LOCAL INPATH '/home/hadoop/data/order.txt'
OVERWRITE INTO TABLE order_mulit_partition
PARTITION(event_month='2014-05', event_day='01');
查询带分区条件:
hive> show partitions order_mulit_partition;
OK
event_month=2014-05/event_day=01
Time taken: 0.151 seconds, Fetched: 1 row(s)
动态分区
实验:注意:分区的字段不能在表的字段中。
hive> create table gordon_static_emp
> (empno int, ename string, job string, mgr int, hiredate string, salary double, comm double,deptno string )
> PARTITIONED by(deptno string)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t' ;
FAILED: SemanticException [Error 10035]: Column repeated in partitioning columns
hive>create table gordon_static_emp
(empno int, ename string, job string, mgr int, hiredate string, salary double, comm double)
PARTITIONED by(deptno string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t' ;
按分区插入数据,每次都要写比较繁琐,引出动态分区。
hive>insert into table gordon_static_emp partition(deptno='20')
select empno,ename,job,mgr,hiredate,salary,comm from gordon_emp
where deptno=20;
Query ID = hadoop_20180615235353_00afe0ef-4679-4699-b907-c8bd25dc6361
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Job running in-process (local Hadoop)
2018-06-15 23:55:27,821 Stage-1 map = 0%, reduce = 0%
2018-06-15 23:55:28,854 Stage-1 map = 100%, reduce = 0%
Ended Job = job_local966661548_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://192.168.199.105:9000/user/hive/warehouse/hive2_gordon.db/gordon_static_emp/deptno=20/.hive-staging_hive_2018-06-15_23-55-19_985_12010454832864485-1/-ext-10000
Loading data to table hive2_gordon.gordon_static_emp partition (deptno=20)
Partition hive2_gordon.gordon_static_emp{deptno=20} stats: [numFiles=1, numRows=5, totalSize=214, rawDataSize=209]
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 700 HDFS Write: 311 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
Time taken: 10.982 seconds
动态分区表建立:
create table gordon_dynamic_emp
(empno int, ename string, job string, mgr int, hiredate string, salary double, comm double)
PARTITIONED by(deptno string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t' ;
动态分区明确要求:分区字段写在select的最后面,名称是否要一致?可以测试一下。
insert into table gordon_dynamic_emp partition(deptno)
select empno,ename,job,mgr,hiredate,salary,comm,deptno from gordon_emp ;
hive>
> insert into table ruozedata_dynamic_emp partition(deptno)
> select empno,ename,job,mgr,hiredate,salary,comm,deptno from ruozedata_emp ;
FAILED: SemanticException [Error 10001]: Line 2:60 Table not found 'ruozedata_emp'
Moving data to: hdfs://192.168.199.105:9000/user/hive/warehouse/hive2_gordon.db/gordon_dynamic_emp/.hive-staging_hive_2018-06-16_00-02-44_572_3957465789389434554-1/-ext-10000
解决方案:
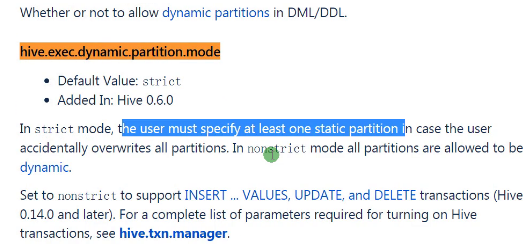
动态分区必须非严格模式:
set hive.exec.dynamic.partition.mode=nonstrict;
这是hive中常用的设置key=value的方式
语法格式:
set key=value; 设置
set key; 取值
官网:
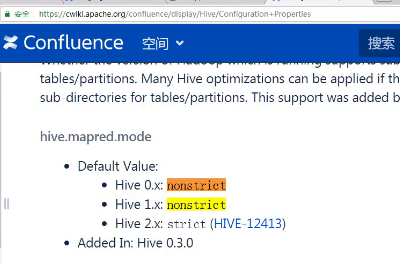
在hive中提供了一种“严格模式”的设置来阻止用户执行可能会带来未知不好影响的查询。
设置属性hive.mapred.mode 为strict能够阻止以下三种类型的查询:
1、 除非在where语段中包含了分区过滤,否则不能查询分区了的表。这是因为分区表通常保存的数据量都比较大,没有限定分区查询会扫描所有分区,耗费很多资源。
Table: logs(…) partitioned by (day int);
不允许:select *from logs;
允许:select *from logs where day=20151212;
2、 包含order by,但没有limit子句的查询。因为orderby 会将所有的结果发送给单个reducer来执行排序,这样的排序很耗时。
3、 笛卡尔乘积;简单理解就是JOIN没带ON,而是带where的
分区是hive在处理大型表时常用的方法。分区(partition)在hive的物理存储中,体现为表名下的某个目录,这个目录下存储着这个分区下对应的数据。分区的好处在于缩小查询扫描范围,从而提高速度。分区分为两种:静态分区static partition和动态分区dynamic partition。静态分区和动态分区的区别在于导入数据时,是手动输入分区名称,还是通过数据来判断数据分区。对于大数据批量导入来说,显然采用动态分区更为简单方便。
可见,通过动态分区技术,不但可以一次导入数据,而且同时能够根据源数据中不同的分区列的值,动态的生成对应的目录,并把对应的数据写入对应的目录中
6.function
内置函数:build-in
通过 查看:show functions
hive.exec.dynamic.partition.mode=nonstrict
hive> set hive.exec.dynamic.partition.mode;
hive.exec.dynamic.partition.mode=nonstrict
hive> show functions;
OK
!
!=
%
hive> desc function upper;
OK
upper(str) - Returns str with all characters changed to uppercase
Time taken: 0.119 seconds, Fetched: 1 row(s)
hive>
>
> desc function extended upper;
OK
upper(str) - Returns str with all characters changed to uppercase
Synonyms: ucase
Example:
> SELECT upper('Facebook') FROM src LIMIT 1;
'FACEBOOK'
Time taken: 0.091 seconds, Fetched: 5 row(s)
hive>
hive> create table dual(x string);
OK
Time taken: 0.301 seconds
insert into table dual values('');
测试分割
hive> select split("192.168.199.151","\\.") from dual;
OK
["192","168","199","151"]
Time taken: 0.189 seconds, Fetched: 1 row(s)
测试时间戳
hive> select unix_timestamp() from dual;
OK
1529079431
Time taken: 0.335 seconds, Fetched: 1 row(s)
hive> select current_date from dual;
OK
2018-06-16
Time taken: 1.089 seconds, Fetched: 1 row(s)
hive> select current_timestamp from dual;
OK
2018-06-16 00:19:24.063
Time taken: 0.397 seconds, Fetched: 1 row(s)
hive> select year("2018-08-08 20:08:08") from dual;
OK
2018
Time taken: 0.426 seconds, Fetched: 1 row(s)
hive>
hive> select date_add("2018-08-08",10) from dual;
OK
2018-08-18
注意:分区的时候会用时间内置函数
Cast 类型转换
hive> select cast("5" as int) from dual;
OK
5
Time taken: 1.685 seconds, Fetched: 1 row(s)
hive> select cast("5" as date) from dual;
OK
NULL
Time taken: 0.232 seconds, Fetched: 1 row(s)
hive> select cast(current_timestamp as date) from dual;
OK
2018-06-16
Time taken: 0.442 seconds, Fetched: 1 row(s)
字符串:
hive>
> desc function extended substr;
OK
substr(str, pos[, len]) - returns the substring of str that starts at pos and is of length len orsubstr(bin, pos[, len]) - returns the slice of byte array that starts at pos and is of length len
Synonyms: substring
pos is a 1-based index. If pos<0 the starting position is determined by counting backwards from the end of str.
Example:
> SELECT substr('Facebook', 5) FROM src LIMIT 1;
'book'
> SELECT substr('Facebook', -5) FROM src LIMIT 1;
'ebook'
> SELECT substr('Facebook', 5, 1) FROM src LIMIT 1;
'b'
Time taken: 0.072 seconds, Fetched: 10 row(s)
hive> desc function extended concat_ws;
OK
concat_ws(separator, [string | array(string)]+) - returns the concatenation of the strings separated by the separator.
Example:
> SELECT concat_ws('.', 'www', array('facebook', 'com')) FROM src LIMIT 1;
Time taken: 0.047 seconds, Fetched: 4 row(s)
hive> desc function extended split;
OK
split(str, regex) - Splits str around occurances that match regex
Example:
> SELECT split('oneAtwoBthreeC', '[ABC]') FROM src LIMIT 1;
["one", "two", "three"]
Time taken: 0.031 seconds, Fetched: 4 row(s)















 3829
3829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









