






作者简介:大厂一线资深开发。从crud开发到资深开发,再到研究员兼技术经理。《资深开发讲技术》 从一线实战中总结有故事,有背景的案例,希望带给大家一系列技术盛宴。
背景:
后端Java服务,Linux环境,resin容器(历史原因,新的服务都是tomcat),此服务承担公司内部的业务,是本团队非常重要的线上业务系统。
现象:
某天下午2点左右,内部用户反馈,系统操作的时候,非常卡,好半天才能打开一个页面。而且反馈的人数在不断增加。
初步排查:
登录到线上服务后,观察日志等,并没有发现日志异常。重点排查了下,编辑反馈接口的耗时,感觉正常。但是很明显,感觉到日志量,较正常的时候少一些。
随后排查了下nginx的access log。发现耗时确实比较多,大约5秒、6秒。
总结起来:后端日志没发现异常,反馈的接口,从日志看响应正常,但是nginx层看耗时很高。很奇怪,怀疑是耗时都阻塞在了获得work线程上了。
简单和小伙伴沟通后,考虑到上午有新发布代码。所以立马要求,我的小伙伴打印jstack日志,保留现场信息,后回滚代码。
回滚后服务正常。初步结论:上午发布新功能,引发了本次故障。
进一步排查:
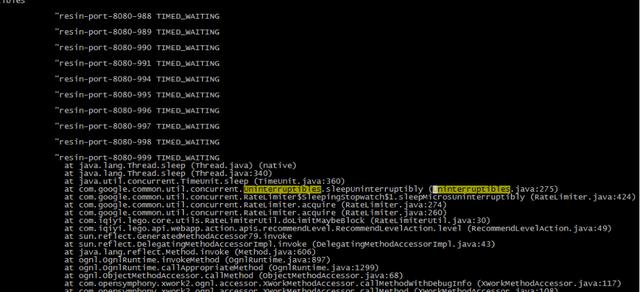
大量线程time_wait在限速组件上
通过jstack日志排查发现,大量resin容器work线程(形如 resin-port-8080-xx)阻塞在分布式限速组件上了。
和相关的小伙伴走读代码,定位到本次,新提供的第三方代码的入口处增加了限速。限速本身并没有错,但是错在api接口侧,使用了阻塞式限速,导致work线程大量被阻塞。影响了系统中的所有接口。
排查后还发现,新增限速的接口,日志量明显增大异常。沟通后发现。他们在线上刷数据,和当时约定的qps相差甚远。
处理结果:
限速调整为非阻塞式,如果超过qps 接口,直接返回超QPS异常。同时和业务方重新沟通了合理的限速阈值。
思考:
此问题的处理结果很简单,但是根本原因,出现在了开发同学,对容器的work 线程,理解不到位。此问题,面向端的开发,一般不会出现此问题,端的开发大多接口,要求毫秒级返回。但是对于后端开发,需要考虑很多业务逻辑以及限制,可能对这个问题认识,并不都是那么深刻。
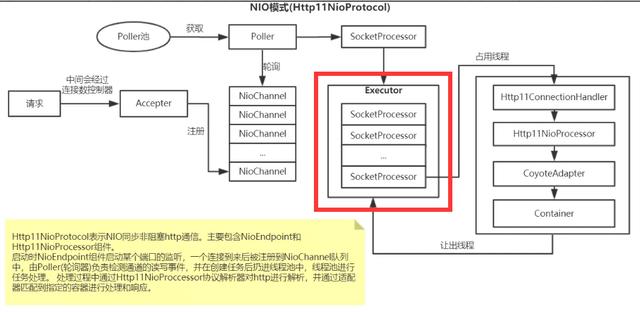
NIO
往期文章
增加消费能力,导致的线上故障
日志中的连接异常信息,你get到了吗?
听过限流熔断,但是对于超时你重视了吗?
cpu 负载过高,服务抗不住了?















 144
144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









