






怎么快速提取PDF文档中的有效图片

具体操作如下:
1、打开已经安装好的PDF编辑器和PDF文档;
图1:打开PDF Expert for Mac
2、在黑色工具栏中点击编辑选项,然后在下级工具栏中选择图片选项;
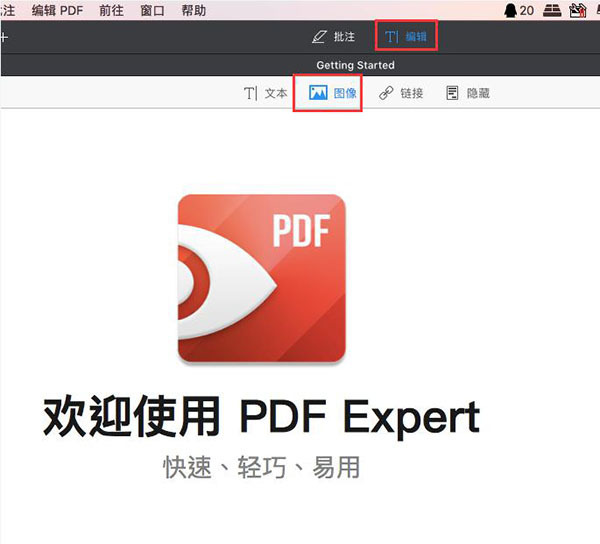
图2:点击图像
3、选中你需要提取的图片,单击这个图片,这时候在右侧工具栏中就会出现这个图片的相关信息,选择“导出”;
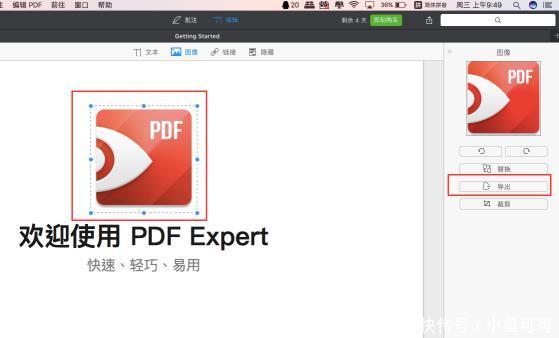
图3:选中图片
4、在出现的“导出图片”小窗口中填写好存储名称和相应的位置,然后确认好之后点击存储即可;
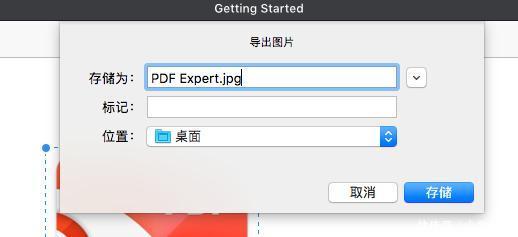
图4:导出图片
5、接下来就可以看到这个名为PDF Expert的图片已经在相应的位置存储好了。
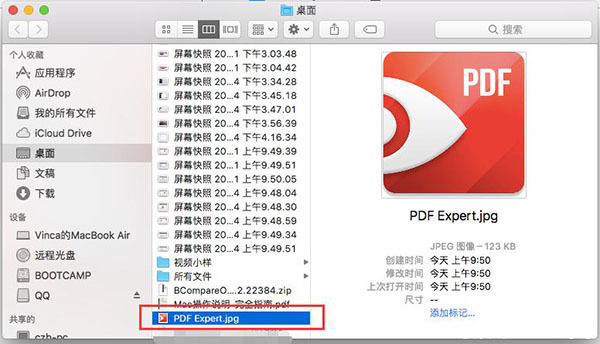
图5:导出完成
只要经过以上简单五步我们就可以将PDF文档中的图片提取出来,以便进行使用,可见这款PDF编辑器不仅编辑文档起来非常方便,实用的小功能也是非常符合大家的心意的,对此有兴趣的小伙伴们赶紧进行下载使用吧,只需要输入邮箱就可以免费激活七天使用,如果想要一直使用的话,只需要正确获取PDF Expert for Mac激活码就可以啦,操作起来也是相当方便的哦。
















 493
493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









