







subprocess的目的就是启动一个新的进程并且与之通信。
subprocess模块中只定义了一个类: Popen。可以使用Popen来创建进程,并与进程进行复杂的交互。它的构造函数如下:
class subprocess.Popen( args,
bufsize=0,
executable=None,
stdin=None,
stdout=None,
stderr=None,
preexec_fn=None,
close_fds=False,
shell=False,
cwd=None,
env=None,
universal_newlines=False,
startupinfo=None,
creationflags=0)参数args可以是字符串或者序列类型(如:list,元组),用于指定进程的可执行文件及其参数。如果是序列类型,第一个元素通常是可执行文件的路径。我们也可以显式的使用executeable参数来指定可执行文件的路径。
subprocess.Popen(["cat","test.txt"])
subprocess.Popen("cat test.txt")
这两个之中,后者将不会工作。因为如果是一个字符串的话,必须是程序的路径才可以。(考虑unix的api函数exec,接受的是字符串
列表)
但是下面的可以工作
subprocess.Popen("cat test.txt", shell=True)
这是因为它相当于
subprocess.Popen(["/bin/sh", "-c", "cat test.txt"])
在*nix下,当shell=False(默认)时,Popen使用os.execvp()来执行子程序。args一般要是一个【列表】。如果args是个字符串的
话,会被当做是可执行文件的路径,这样就不能传入任何参数了。
注意:
shlex.split()可以被用于序列化复杂的命令参数,比如:
>>> shlex.split('ls ps top grep pkill')
['ls', 'ps', 'top', 'grep', 'pkill']
>>>import shlex, subprocess
>>>command_line = raw_input()
/bin/cat -input test.txt -output "diege.txt" -cmd "echo '$MONEY'"
>>>args = shlex.split(command_line)
>>> print args
['/bin/cat', '-input', 'test.txt', '-output', 'diege.txt', '-cmd', "echo '$MONEY'"]
>>>p=subprocess.Popen(args)可以看到,空格分隔的选项(如-input)和参数(如test.txt)会被分割为列表里独立的项,但引号里的或者转义过的空格不在此列
。这也有点像大多数shell的行为。
在*nix下,当shell=True时,如果arg是个字符串,就使用shell来解释执行这个字符串。如果args是个列表,则第一项被视为命令,
其余的都视为是给shell本身的参数。也就是说,等效于:
subprocess.Popen(['/bin/sh', '-c', args[0], args[1], ...])
参数bufsize一般0 无缓冲,1 行缓冲,其他正值 缓冲区大小,负值 采用默认系统缓冲(一般是全缓冲)
executable一般不用,args字符串或列表第一项表示程序名
参数stdin, stdout, stderr分别表示程序的标准输入、输出、错误句柄。他们可以是PIPE,文件描述符或文件对象,也可以设置为None,表示从父进程继承。
如果参数shell设为true,程序将通过shell来执行。
参数env是字典类型,用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父进程中继承。
subprocess.PIPE
在创建Popen对象时,subprocess.PIPE可以初始化stdin, stdout或stderr参数。表示与子进程通信的标准流。
subprocess.STDOUT
创建Popen对象时,用于初始化stderr参数,表示将错误通过标准输出流输出。
Popen的方法:
Popen.poll()
用于检查子进程是否已经结束。设置并返回returncode属性。
Popen.wait()
等待子进程结束。设置并返回returncode属性。
Popen.communicate(input=None)
与子进程进行交互。向stdin发送数据,或从stdout和stderr中读取数据。可选参数input指定发送到子进程的参数。Communicate()返回一个元组:(stdoutdata, stderrdata)。注意:如果希望通过进程的stdin向其发送数据,在创建Popen对象的时候,参数stdin必须被设置为PIPE。同样,如果希望从stdout和stderr获取数据,必须将stdout和stderr设置为PIPE。
Popen.send_signal(signal)
向子进程发送信号。
Popen.terminate()
停止(stop)子进程。在windows平台下,该方法将调用Windows API TerminateProcess()来结束子进程。
Popen.kill()
杀死子进程。
Popen.pid
获取子进程的进程ID。
Popen.returncode
获取进程的返回值。如果进程还没有结束,返回None。
进程通信:
如果想得到进程的输出,管道是个很方便的方法:
p=subprocess.Popen("dir", shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
(stdoutput,erroutput) = p.communicate() p.communicate会一直等到进程退出,并将标准输出和标准错误输出返回,这样就可以得到子进程的输出了。

上面的例子通过communicate给stdin发送数据,然后使用一个tuple接收命令的执行结果。
上面,标准输出和标准错误输出是分开的,也可以合并起来,只需要将stderr参数设置为subprocess.STDOUT就可以了,这样子:
p=subprocess.Popen("dir", shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
(stdoutput,erroutput) = p.communicate() 如果你想一行行处理子进程的输出,也没有问题:
p=subprocess.Popen("dir", shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
while True:
buff = p.stdout.readline()
if buff == '' and p.poll() != None:
break 死锁
但是如果你使用了管道,而又不去处理管道的输出,那么小心点,如果子进程输出数据过多,死锁就会发生了,比如下面的用法:
p=subprocess.Popen("longprint", shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
p.wait() longprint是一个假想的有大量输出的进程,那么在我的xp, Python2.5的环境下,当输出达到4096时,死锁就发生了。当然,如果我们用p.stdout.readline或者p.communicate去清理输出,那么无论输出多少,死锁都是不会发生的。或者我们不使用管道,比如不做重定向,或者重定向到文件,也都是可以避免死锁的。
subprocess还可以连接起来多个命令来执行。
在shell中我们知道,想要连接多个命令可以使用管道。
在subprocess中,可以使用上一个命令执行的输出结果作为下一次执行的输入。例子如下:
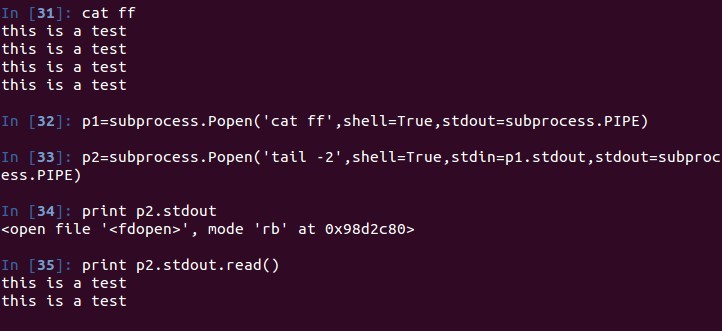















 606
606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









