






本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
以下为译文:
最近我决定参加CrowdAnalytix主办的 Extraction of product attribute values竞赛,在这个网站上公司可以将数据处理的问题以外包的方式交给有能力处理的人。一直以来,我擅长的是图像和视频数据处理,而这次,我尝试着处理文本。 问题是从不同长度的产品标题和产品描述中提取出制造商零件编号(MPN),这是一个标准的正则表达式问题。在简单浏览数据之后,我发现大约有54000个训练样本。因此,我决定使用深度学习的方法。在这我公布我在排行榜上排名第四的方法。
免责申明
由于这是一个盈利的方案,根据CrowdAnalytix的条款,我只能将方法的大致思想分享出来。
问题
在竞赛的网站上,赛题是这样的“请使用正则表达式从产品标题或产品描述中提取出制造商零件编号”。虽然我不知道需要什么样的正则规则,但是我知道是从长文本中提取数据。以下就是一个标题的样例:
EVGA NVIDIA GeForce GTX 1080 Founders Edition 8gb Gddr5x 08GP46180KR
接下来我只是想从产品标题和描述中提取出MPN “08GP46180KR”
下图是一个匹配邮箱的案例,使用正则表达式的要旨其实就是对想要找的文本按照一定规则硬编码,然后再去匹配。

在这里,正则表达式围绕的预定义字符是“@”和“.”。而深度学习的魅力则是经过大量的训练,我们可以学习出正则表达式,而不是硬编码,这也是我采取的方法。
数据设置
用来训练的54000条数据有一下的参数[id,产品标题,产品描述,mpn]。用来测试的数据除了没有mpn属性,其他和训练集一样。通过对数据的检查,我发现在大多数情况下,MPN要么存在于产品标题中,要么存在于产品描述中。数据中的干扰是数据处理过程中的一大难题,这些干扰往往和MPN很像,比如在显卡单元中,Gddr5x看起来就很像MPN。因为问题是提取MPN,我设置的输入包括产品名称、描述,设定的输出为MPN。
现在我已经知道输入输出是什么了,我需要决定一些映射来使用神经网络。由于MPN 、HTML片段以及其他一些奇怪字符的出现,这不是一个常规的自然语言处理问题。因此,像word2vec 类似的解决方案是不合适的(如果我错了,请纠正我)。我很幸运有一个攀岩的朋友,Joseph Prusa,一直与性格和情感分析工作(Prusa和khoshgoftaar,2014)。他非常亲切地分享了他的代码,并针对我的问题做了一些订制。于是,我整合出了我的解决方案。
映射的过程将每一个字符变换成一个8位的向量。举个例子,“EVGA NVIDIA GeForce GTX 1080 Founders Edition 8gb Gddr5x 08GP46180KR”可以用下图表示:

另外一个问题是,输入(标题和描述)的长度是各不相同的。因此我需要采取一些方法,使得它们长度统一,这样才能输入到网络中。我的第一步是可视化的所有输入的长度分布。
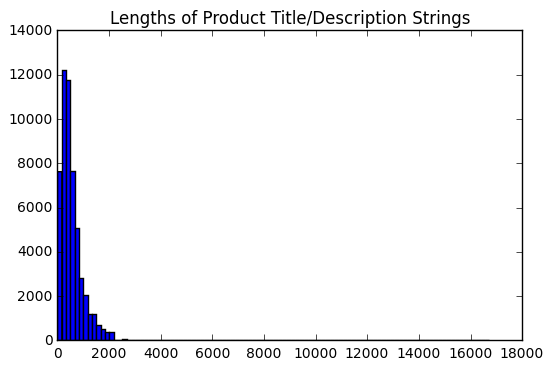
基于这个分布,我设置最大长度为2000,因为它包括大多数的情况。并避免了很长的异常值。首先,我将输入按照上面说的方法进行处理,如果长度不够两千的,后面会被补上0。在输入的长度大于2000的情况,如果MPN在前2000中,则不会造成影响,而如果不是这样,则MPN会丢失(在数据集中非常不常见)。这样一来,每一个输入都被归一化成了8*2000的图。
问题构想
如果我们要用神经网络的向后传播算法,接下来的问题就是什么是合适的输出和损失函数。最自然的选择似乎是输出向量格式的MPN。一般来说以Mean-Squared Error 作为损失函数是无监督学习生成模型的常规做法。而且这么做在技术上没有难度。
但是,我决定采用一个不同的方式。我把输出定义为两个独热二进制向量,每一个的长度是最大长度(2000)。其中第一个向量表示MPN的开始索引,第二个向量表示MPN的结束索引。然后损失是两个向量分类交叉熵的总和。
给出输出之后,后台会运行一个辅助方法。该方法使用之前的索引作为输入,提取出MPN的向量表现形式,然后将向量转化为字符串表示形式,这也就是最终的输出。如果MPN不存在,结果就是两个向量最后的那个。
模型结构
既然数据设置完了,目标也明确了,接下来要做的事情就是构建一个模型来完成之前设计的任务。我尝试了包括深度卷积神经网络在内的许多种神经网络。这些方法效果都不错,但是并不能达到我的预期。
幸运的是 Google DeepMind刚发表了一篇文章,介绍了他们的新模型WaveNet ,这个模型正是我想要的。这样的模型因其使用多层的卷积操作且没有进行池化而有趣。由于每一个随后的层都使用了扩张操作,该模型在保证参数数量在合理的范围内的同时能得到有巨大容纳域的滤波器(请参考下图的红色部分,图片来自 Neural Machine Translation in Linear Time)。
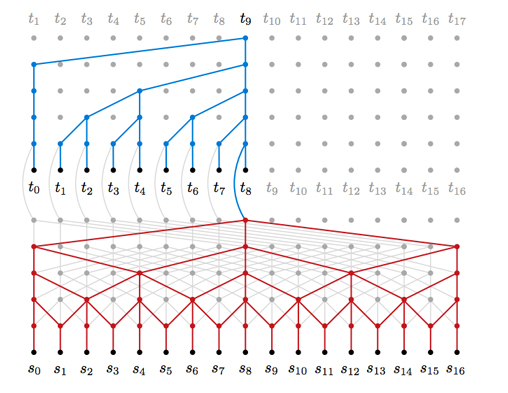
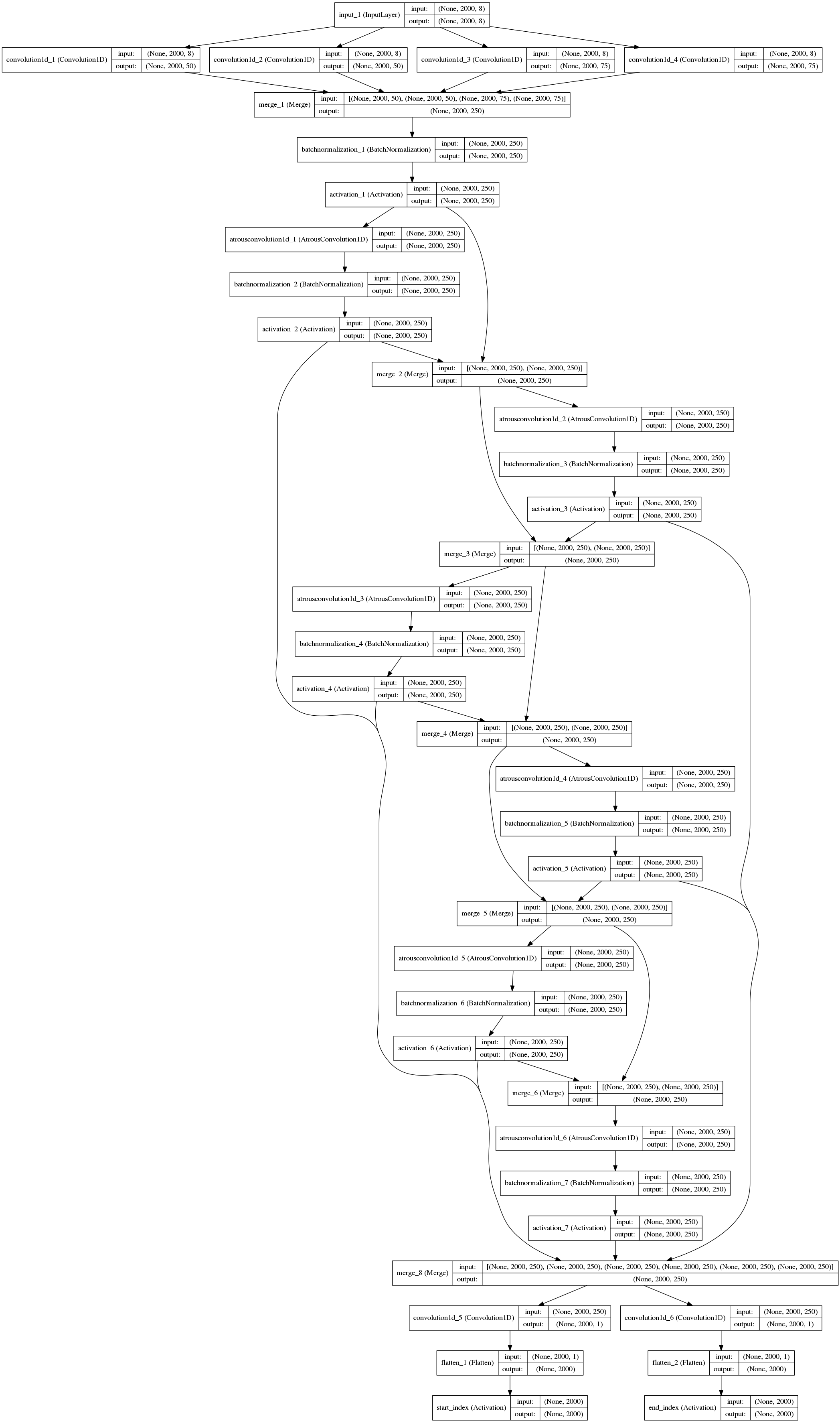
我最终模型思想是从输入提取一组基本特征,通过一系列扩大的卷积,然后用softmax激活函数分支两个卷积过滤器,最终预测预测开始和结束索引。更详细地,该模型如下:
- 使用1D卷积来从不同长度的数据中提取基本特征。这些展现不同长度的单字符到多字符的转换。这些都被串起来输送给下一层网络。
- 接下来,这些表示形式被送到一个个块中处理。这些块用Batch Normalization, Rectified Linear Units来处理。这允许网络基于由于扩大的卷积而覆盖几乎整个输入的范围来选择最佳匹配的开始和结束索引。
- 最后,两个使用softmax激活函数的1D卷积滤波器在剩余输出上执行。最大参数表示开始和结束位置的最高概率的索引。
模型架构如下图所示,显示了模型的主要特征:
性能
训练完之后,模型在训练集上展现出了近乎完美的表现,对于验证集达到了90%的准确率!在排行榜上也达到了84%的准确率。
当我准备提交的时候,我发现由于样本数量太少模型以非常快的速度过拟合数据。我知道,对于54000个样本来说,从中学习是非常困难的。但是我对我的模型有信心,如果有几十万条数据,我的解决方案会有更高的排名。由于竞赛我迟到了,所以在最后的提交中,我选择了较低的学习率,也只进行几轮学习。如果还有时间的话,我会尝试去探索数据增强和模型规则化技术来让模型更完善,同时也可以防止过拟合。此外,训练其他文本可能是一个成功的策略。暴力法会使最大长度参数略有增加,这可能会给我们带来一些边际的改进,但代价是非常高的计算成本。
结论
考虑到以前我从来没有遇到这样类型的问题,本次的竞赛是令人满意且充满挑战的。首先要说一声抱歉,因为我要为深度学习打广告了。看起来好像这个领域和深度学习没太多关系,但是应用深度学习确实非常有趣而且效果不错。这也体现了深度学习应用的普适性。希望这次分享能帮助到遇到类似问题的童鞋。
引用
Prusa, J. D., & Khoshgoftaar, T. M. (2014). Designing a Better Data Representation for Deep Neural Networks and Text Classification.
文章原标题《Deep Learning for RegEx》,作者:Daniel C. LaCombe, Jr
文章为简译,更为详细的内容,请查看原文















 543
543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









