







例子描述:
搜索和“buying a home”相关的书。
数据库中有一个Book表,存在下图9条记录
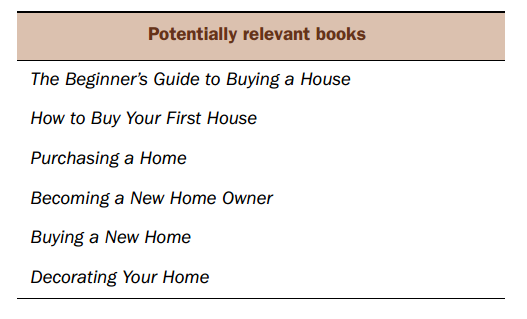
(图一 与”buying a home"相关的book name 6条)

(图二 与"buying a home"不相关的book name 3条)
当我们在输入框输入buying a home的时候,期望结果是搜出图一中的6条数据。以下使用SQL进行查询测试。
1,使用 = 匹配
SELECT * FROM Books
WHERE Name = 'buying new home';
无查询结果
SELECT * FROM Books
WHERE Name = 'buying a new home';
查到一条记录
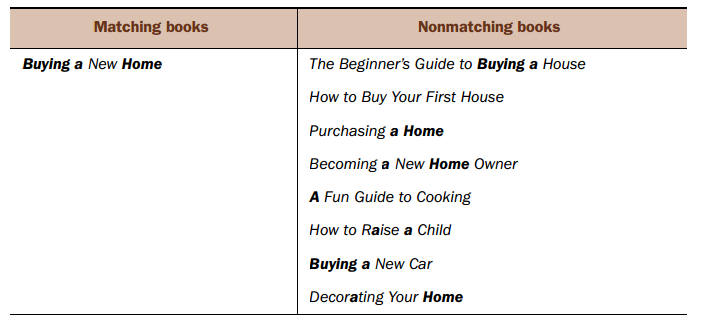
2, 使用like进行模糊匹配,and连接的结果
SELECT * FROM Books
WHERE Name LIKE '%buying%'
AND Name LIKE '%a%'
AND Name LIKE '%home%';
仍然只查询到了一条相关记录
![]()
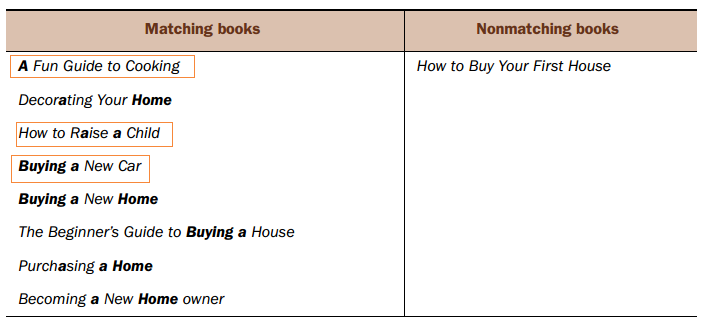
3,使用like进行模糊匹配,or连接
SELECT * FROM Books
WHERE Name LIKE ‘%buying%’
OR Name LIKE ‘%a%’
OR Name LIKE ‘%home%’;
显然很多不相关的book被查询了出来
使用传统的关系型数据库进行查询,我们发现主要存在以下问题:
1,只能够进行子字符串的匹配查询。如上例中,只能对查询词分开来进行匹配查询,如果使用“=”进行匹配很多相关的文档没有被检索出来。
2,无法区分语言学上的变化。这里指buy到buying的变化(中文不存在这种问题)。
3,同义词无法区分。buying和purchasing都有购买的意思,但是数据库的匹配查询无法认为他们是一样的。
4,不重要的词仍然被作为查询条件进行查询。这里指查询 a 也作为了一个条件。同理中文查询中“的”这种无意义的词在查询时也不应包含。
5,没有相关性的排序。从上图的查询结果看,不相关的内容却被排到了前面。这个顺序依赖于数据库的内部顺序。
当这个表的数据逐渐变大的时候,like查询的匹配会非常慢,即使在有索引的情况下。况且关系型数据库也不应该对文本字段进行索引(感兴趣的同学可以了解一下数据库的索引创建过程)。
根据以上的实验得出结论:关系型数据库不适合全文检索。
更多内容可关注微信公众号,金沙数据

















 533
533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









