







环境概览
| 框架 | 版本号 |
| Spring Boot | 1.5.12.RELEASE |
| Sharding-JDBC | 2.0.3 |
| MyBatis-Plus | 2.2.0 |
前言介绍
Sharding-JDBC是当当网的一个开源项目,只需引入jar即可轻松实现读写分离与分库分表。与MyCat不同的是,Sharding-JDBC致力于提供轻量级的服务框架,无需额外部署,底层是对JDBC进行增强,兼容各种连接池和ORM框架。不仅如此还提供分布式事务及分布式治理功能,即将出世的3.X版本可能会提供更加全面的功能。有兴趣的小伙伴们,可以去了解下,这里提供官方文档、GitHub地址和码云地址。
读写分离
引自Sharding-JDBC官方文档
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。 对于同一时间有大量并发读操作和较少写操作类型的应用系统来说,将单一的数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。 通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。 使用多主多从的方式,不但能够提升系统的吞吐量,还能够提升系统的可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行。
虽然读写分离可以提升系统的吞吐量和可用性,但同时也带来了数据不一致的问题,这包括多个主库之间的数据一致性,以及主库与从库之间的数据一致性的问题。并且,读写分离也带来了与数据分片同样的问题,它同样会使得应用开发和运维人员对数据库的操作和运维变得更加复杂。透明化读写分离所带来的影响,让使用方尽量像使用一个数据库一样使用主从数据库,是读写分离中间件的主要功能。
读写分离,简单来说,就是将DML交给主数据库去执行,将更新结果同步至各个从数据库保持主从数据一致,DQL分发给从数据库去查询,从数据库只提供读取查询操作。读写分离特别适用于读多写少的场景下,通过分散读写到不同的数据库实例上来提高性能,缓解单机数据库的压力。
这里解释一下什么是DML和DQL?SQL语言四大分类:DQL、DML、DDL、DCL。
- DQL(Data QueryLanguage):数据查询语言,比如select查询语句
- DML(Data Manipulation Language):数据操纵语言,比如insert、delete、update更新语句
- DDL():数据定义语言,比如create/drop/alter等语句
- DCL():数据控制语言,比如grant/rollback/commit等语句
实现步骤
实现步骤非常简单,仅需两步,即可在代码上实现读写分离功能,感觉非常带劲。
1.引入jar包
<dependency>
<groupId>io.shardingjdbc</groupId>
<artifactId>sharding-jdbc-core-spring-boot-starter</artifactId>
<version>2.0.3</version>
</dependency>2.配置读写分离
sharding:
jdbc:
# 配置真实数据源
datasource:
names: ds_master_0,ds_slave_0_1,ds_slave_0_2
# 配置主库
ds_master_0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://ip:3306/test?useSSL=false&useUnicode=true&characterEncoding=utf8&autoReconnect=true
username: username
password: password
maxPoolSize: 20
# 配置第一个从库
ds_slave_0_1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://ip:3307/test?useSSL=false&useUnicode=true&characterEncoding=utf8&autoReconnect=true
username: username
password: password
maxPoolSize: 20
# 配置第二个从库
ds_slave_0_2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://ip:3308/test?useSSL=false&useUnicode=true&characterEncoding=utf8&autoReconnect=true
username: username
password: password
maxPoolSize: 20
# 配置读写分离
config:
masterslave:
# 配置从库选择策略,提供轮询与随机,这里选择用轮询
load-balance-algorithm-type: round_robin
name: ds_m_1_s_2
master-data-source-name: ds_master_0
slave-data-source-names: ds_slave_0_1,ds_slave_0_2
sharding:
props:
# 开启SQL显示,默认值: false,注意:仅配置读写分离时不会打印日志!!!
sql:
show: true准备测试
在测试开始之前,我们先明确一点,由于只配置了读写分离,即使上文中配置了sql.show=true也不会有日志打印出来(如果配置了分库/分表就不会有这种情况),那么我们怎么知道数据库操作到底是走的主库还是主库呢?怎么知道如果走从库有没有遵循轮询算法走的具体是哪个从库呢?
带着上述的疑问,追溯源码进入MasterSlaveDataSource这个类中(友情提示:IDEA连续按两次shift在弹框中输入MasterSlaveDataSource即可查看该类),主要关注其中的getDataSource()方法。下面贴出关键源码。
/**
* Get data source from master-slave data source.
*
* @param sqlType SQL type
* @return data source from master-slave data source
*/
public NamedDataSource getDataSource(final SQLType sqlType) {
if (isMasterRoute(sqlType)) {
DML_FLAG.set(true);
return new NamedDataSource(masterSlaveRule.getMasterDataSourceName(), masterSlaveRule.getMasterDataSource());
}
String selectedSourceName = masterSlaveRule.getStrategy().getDataSource(masterSlaveRule.getName(),
masterSlaveRule.getMasterDataSourceName(), new ArrayList<>(masterSlaveRule.getSlaveDataSourceMap().keySet()));
DataSource selectedSource = selectedSourceName.equals(masterSlaveRule.getMasterDataSourceName())
? masterSlaveRule.getMasterDataSource() : masterSlaveRule.getSlaveDataSourceMap().get(selectedSourceName);
Preconditions.checkNotNull(selectedSource, "");
return new NamedDataSource(selectedSourceName, selectedSource);
}
private boolean isMasterRoute(final SQLType sqlType) {
return SQLType.DQL != sqlType || DML_FLAG.get() || HintManagerHolder.isMasterRouteOnly();
}isMasterRoute() 方法判断当前操作是否应该路由到主库数据源,如果SQL类型是DML则返回true
getDataSource() 方法根据SQL类型返回一个数据源。如果SQL类型是DQL则通过配置的算法返回一个从库数据源,如果SQL类型是DML则返回主库数据源。
那么了解了以上两个方法后,通过打断点DEBUG的方式,我们可以很容易的得知,执行SQL时到底走的是哪个库。
开始测试
这边我准备了两个测试接口,一个用于测试读操作,一个用于测试写操作。
@RestController
@RequestMapping("/users")
public class UserController {
@Autowired
private IUserService userService;
/**
* 查询用户列表
* @return
*/
@GetMapping
public List<User> getUser() {
return userService.selectList(null);
}
/**
* 创建/修改用户信息
* @param user
* @return
*/
@PostMapping
public User saveUser(@RequestBody User user) {
return userService.insertOrUpdate(user) ? userService.selectById(user.getId()) : null;
}
}发起GET请求/users接口,期望通过轮询算法去从库中查询获取数据

第一次,通过上图我们可以很容易发现SQL类型是DQL,走的是ds_slave_0_1从数据库,且策略是轮询策略
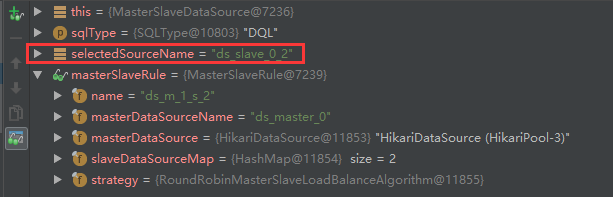
第二次,我们可以发现走的是ds_slave_0_2从数据库,读操作和轮询算法都没毛病
发起POST请求/users接口,期望从主库中创建或修改用户数据。
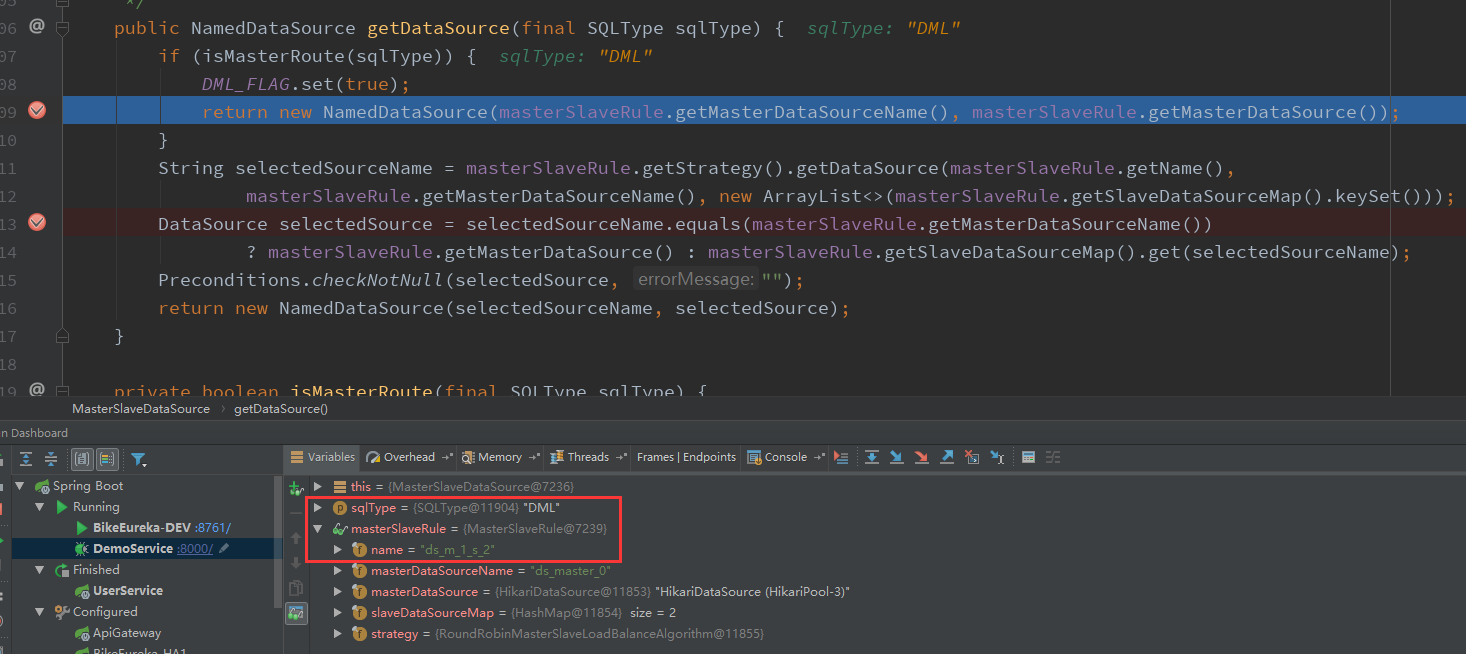

可见,写操作时,走的是ds_master_0主数据库。当userService.insertOrUpdate(user)执行成功返回true后,接着再执行userService.selectById(user.getId())时,又会走到ds_slave_0_1从库读取数据。写操作也没毛病,以上我们的测试阶段就大功告成了。
轮询策略
有兴趣的小伙伴可以看下轮询策略的源码,非常的简单。这里贴出轮询策略主要源码
/**
* Round-robin slave database load-balance algorithm.
*
* @author zhangliang
*/
public final class RoundRobinMasterSlaveLoadBalanceAlgorithm implements MasterSlaveLoadBalanceAlgorithm {
private static final ConcurrentHashMap<String, AtomicInteger> COUNT_MAP = new ConcurrentHashMap<>();
@Override
public String getDataSource(final String name, final String masterDataSourceName, final List<String> slaveDataSourceNames) {
AtomicInteger count = COUNT_MAP.containsKey(name) ? COUNT_MAP.get(name) : new AtomicInteger(0);
COUNT_MAP.putIfAbsent(name, count);
count.compareAndSet(slaveDataSourceNames.size(), 0);
return slaveDataSourceNames.get(count.getAndIncrement() % slaveDataSourceNames.size());
}
}其内部通过并发容器ConcurrentHashMap与AtomicInteger的CAS保障高并发下计数线程安全,使用无锁的方式比加锁效率更高。
灵活性
Sharding-JDBC使用简单,容易上手且十分灵活,不仅可以使用默认策略,还可以使用自定义的策略。可以说是对Java开发者十分的友好,通过写Java代码的方式就可以实现更加深度的定制化路由规则。这里如果想要自定义轮询策略可以使用如下配置来自定义的轮询策略。
sharding:
jdbc:
config:
masterslave:
load-balance-algorithm-class-name: 自定义算法类的全限定名注意点
在玩转读写分离时,遇到如下几个需要注意的地方
- Sharding-JDBC目前仅支持一主多从的结构
- Sharding-JDBC没有提供主从同步的实现,该功能需要自己额外搭建,可参照《基于Docker搭建MySQL主从复制》简易搭建测试使用
- 主库和从库的数据同步延迟导致的数据不一致问题需要自己去解决
- Sharding-JDBC虽然提供了打印SQL日志的开关,但是如果仅配置了读写分离好像是没有用的
- 文中配置使用的是HikariCP连接池,使用其他连接池时,需要将jdbc-url配置名该为url,否则可能会抛异常
总结
这一篇,简单带大家用Java代码实现了读写分离,下一篇预计会带大家玩一下数据库的分库分表。

















 8973
8973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









