







1、type指令查看命令的来源:bash内建,alias别名,其他文件。还可以查看命令的文件地址
2、一长串指令中。需由其他指令提供指令提供信息,可以使用反单引号``或者$()来运行
如version=$(uname -r)
3、取消变量设定,使用unset, 如unset myname。
4、在一串指令中,在 ``内的指令将会被先执行,而其执行出指令结果将做为外部指令输入信
息!
5、locate指令可以列出所有相关的命令文档名。
6、export: 自定义变量转成环境变量
7、env和set的区别:环境变量和自定义变量。两种差异主要在于该变量是否会被子程序所继续引用。当linux取得一个bash之后,你的bash就是一个独立的程序,成为PID,接下来你在这个bash底下所下达的任何指令都是有这个bash所衍生出来的。那些被下达的指令就被称为子程序了。子程序只会继承父程序的环境变量,不会继承父程序的自定义变量。
8、将环境变量变为自定义变量可以使用declare。
9、文件系统和程序的限制关系:ulimit
10、shell特殊字符
echo ${PATH#/usr/bin:} echo ${PATH##/usr/bin:} #表示从前面开始删除
#:符合取代文字的最短的那一个
##:符合取代文字的最长的那一个
%是从后面往前删除,即由后面往前匹配
取代:使用/或//,类似#,##
/旧字符/新字符
11、shell中特殊字符变量使用说明
删除和替换
变量测试和内容替换
减号不会更改旧变量,如果想要旧变量和新变量同时更改的话,可以使用“=”
如果旧变量不存在,我想让测试告知我有错误,此时可以使用问好?。
12、命令别名的设定,使用alias和unalias
13、linux指令搜寻顺序可以这么看,也可以通过type -a 指令来查看。
14、login shell 和 non-login shell
区别在于有没有登录,其读取的文件数据(配置)并不一样。
login shell :有tty1--tty6登入,需要输入用户名和密码,此时的shell就称为login shell。
non-login shell:X windows登录linux,启动终端机。此时shell就叫做non-login shell。
在次shell下再次下达bash。这个bash也是non-login shell
15、login shell会读取这两个配置文件。依次为
/etc/profile:这是系统整体的设定,最好不要修改这个档案。(login shell 才会读)
~/.bash_profile或~/.bash_login 或~/.profile:需与使用者个人设定,要修改的数据可以写在这里。
16、non-login shell 只读取~/.bashrc
17、source:读入环境配置文件的指令。也可以用.(小数点)来表示。
18、终端机环境设定:stty,set
19、bash下的通配符,如下

20、bash环境中的特殊符号


备注:>,>> 与<,<<对应不同
<<代表的是结束的输入字符
21标准的输入和输出,可以使用特殊字符表示,如下

22、/dev/null:垃圾桶黑洞装置,如果我知道错误讯息会发生,如果要将错误讯息忽略掉而不显示或存储,可以将其导入到/dev/null中。
23、将stdout和stderr导入到同一个文件中;比如
1)find /home -name bash >list 2>list(可以写入,不过两股数据同时写入,造成次序的错乱)
2)find /home -name bash >list 2>&1(可以,不造成次序错乱)
3)find /home -name bash &>list(可以,不造成次序错乱)
24、命令执行:; && ||
;是不分命令的相关性,顺序执行。

25、管线命令 |
处理示意图,其中对stderr没有直接处理能力。
并且每个管线后面的接的指令必须能够接受standard input的数据才行。这样的指令才可以是为管线命令。如less, more ,head, tail等,至于ls, cp,mv等就不是管线命令了。
因此管线命令有两个比较需要注意的地方:
26、截取命令:cut,grep
27、排序命令:sort, wc, uniq
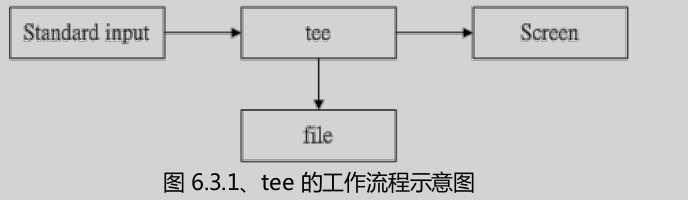
28、双向重导向:tee,tee会同时将数据流分送到档案与屏幕去,分送到屏幕,其实就是stdout,可以让下个指令继续处理。
29、字符转换命令:tr,col,join,paste,expand
tr:可以用来删除一段讯息当中的文字,或者是进行文字讯息的替换。
col:
col -x 将tab键转换为对等的空格键。
col -b 在文字内有反斜杠(/)时,进保留反斜杠最后的那个字符。
join:处理两个档案之间的数据。而且主要是处理两个档案当中,有“相同数据”的那一行,才将它们加在一起。
paste:简单将两行链接在一起,用tab键隔开。
expand:将tab键转成空格,-t后面可以接数字,指定一个tab键可以用几个空格键来取代。
二)linux帐号管理和ACL权限设定
30、使用者的标识:UID和GID
其实linux主机并不会直接认识你的帐号名称,它仅认识ID(一组号码)。
那么档案如何判别他的拥有者和群组呢,其实就是利用UID和GID。每个档案都会有所谓的拥有者ID和拥有群组ID,当我们有要显示文件属性的需求时,系统会依据/etc/passwd和/etc/group 的内容。找到UID和GID对应的帐号名称和组名在显示出来。
31、用户登录主机去的shell的环境来工作时,需要如何进行呢?首先利用tty1~tty7的终端机提供的login接口,输入帐号和密码登录,或在网络中利用ssh。那么你输入帐号和密码后,系统帮你处理了什么呢?
1、先找寻/etc/passwd里面是否有你的输入帐号。如果没有则跳出。如果有的话则将该帐号对应的UID和GID读出来,另外,该帐号的家目录与shell设定也一并读出。
2、再来则是核对密码表啦!这是linux会进入/etc/shadow里面找出对应的帐号和UID,然后核对一下你刚刚输入的密码和里头的密码是否相符。
3、一切OK的话,就进入shell控管阶段。
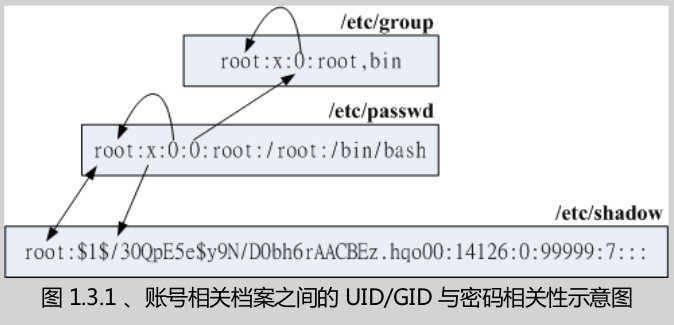
32、/etc/passwd档案结构
每一行都代表一个帐号,每一行使用:分隔开,共有七个咚咚。
1、帐号名称,用来对应UID
2、密码。早期UNIX系统密码就放在这个字段上。但由于该文件的权限(能够被其他程序读取),后来将该字段的密码数据改到了/etc/shadow。所以现在这里用X来替代。
很多程序的运作和权限有关,而权限与UID/GID有关,因此个程序当然需要读取/etc/shadow来了解不同帐号的权限。因此/etc/passwd的权限需设定-rw-r--r--。
3、UID使用者标识符。
4、GID。这个与/etc/group。/etc/group用来规范组名和GID的对应而已。
5、用户信息说明栏。只是用来解释这个帐号的意义而已
6、家目录。这是用户的家目录。
7、shell。用户登入系统后所取得的shell
33、/etc/shadow结构
用来保存账户密码。以:作为分隔符。共有就九个字段。
1、帐号名称,必须要与/etc/相同才行。
2、帐号密码,真正的密码,经过编码加密。
3、最近更动密码的日期,数值为与1970年1月1日作为1而累加
4、密码不可被改动的太念书。0的话就是可以随意变动了。
5、密码需要重新变更的天数
6、密码需要变更期限其的警告天数
7、密码过期后的帐号宽限的天数
8、帐号失效的日期。与第三字段一样,使用1970年以来的总日数设定。
9、保留
34、
三)程序管理与SELinux初探
1、program与process的差异

2、子程序和父程序
可以使用ps -l指令案例查看程序的父程序ID是多少。
如果我将有问题的程序关闭了,怎么过一段时间有自动产生。而且产生的PID与原先不一样。如果不是crontab工作排查的影响,那肯定有一个父程序在运行。那么要找出父程序,然后将它删除掉。
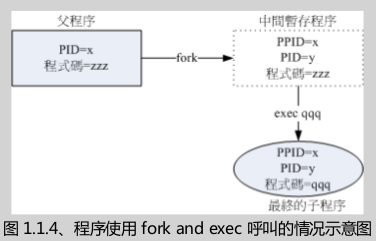
3、父程序和子程序的相互之间的呼叫:fork 和 exec
其程序都会借由父程序以复制的方式(fork)产生一个一模一样的子程序,然后被复制出来的子程序在以exec的方式来执行实际要进行的程序。最终就成为了一个子程序的存在。流程示意图如下:
4、工作管理
kill掉jobs时在jobs序号前加上%,
fg:将背景工作拿到前景来处理
bg:让工作在背景下的状态变成运作中
kill:管理背景中的工作
5、程序管理
ps
top
pstree
kill
killall
kill和killall的区别:
kill后面要加上PID或者job number。所以kill都会配合ps, pstree等指令。因为我们必须找到相对应程序的ID。killall后面加的是下达指令的名称。删除服务的话,用killall比较方便。会删除系统中所有的该服务。
6、系统运行的优先级:Priority和Nice。
PRI是核心动态调整的。用户无权干涉。
NI(Nice),用户可以修改这个进行调整。
PRI(New) = PRI(old) + Nice
可以使用nice指令进行调整。
使用renice调整已存在程序的nice值。
7、系统资源的查看
free:观察内存使用情况
uname:查阅系统和核心的相关信息
uptime:观察系统启动时间与工作负载
netstat:追踪网络或插糟文件,比较常用在网络监控方面。输出分为两个部分:分别是网络与系统自己的程序相关性部分。
dmesg:分析核心产生的讯息。
系统在开机癿时候,核心会去侦测系统癿硬件,你癿某些硬件到底有没有被捉到,那就不这个时候癿侦测有关。 但是这些侦测癿过程要丌是没有显示在屏幕上,就是徆飞忚癿在屏幕上一闪而逝能把核心侦测癿讯息捉出来瞧瞧。
vmstat:侦测系统资源变化。
若想了解系统资源的运作。vmstat可以侦测CPU,内存,磁盘输入输出状态的变化。
三)开机流程、模块管理与loader
四)认识和分析登录档
五)linux磁盘和文件系统管理
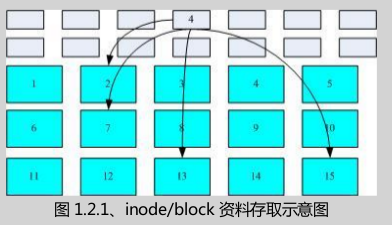
1、linux文件系统属性。操作系统的档案数据除了档案实际内容外,通常含有非常多的属性。比如linux操作系统的档案权限和文件属性。文件系统通常将这两部分的数据分别存放在不同的区块。权限和属性放置在inode中,实际内容放置在data block区块中。还有一个superblock会记录整个文件系统的整体信息。包括inode和block的总量,使用量,剩余量等。
说明如下:
superblock:记录此filesystem的整体信息。包括inode/block的总量,使用量,剩余量以及文件系统的格式与相关信息等。
inode:记录档案的属性。一个档案占用一个inode,同时记录此档案的数据所在的block号码。
block:实际记录内容的档案。若档案太大时,会占用多个block。

2、
五)linux档案与文件系统的压缩和打包
1、linux环境中,压缩文档案的扩展名大多是:
*.Z: compress程序压缩的档案,由于gzip可以兼容,所以该指令已经退出流行了。
*.gz: gzip程序的压缩指令
*.bz2: bzip2程序压缩的档案
*.tar: tar程序打包的数据,且没有经过压缩。
*.tar.gz: tar程序打包的档案,并且经过gzip的压缩。
*.tar.bz2: tar程序打包的档案,并且经过bzip2的压缩
因此常见的压缩指令为gzip和bzip2
2、tar指令可以将很多档案和目录打包成一个档案,单纯的tar只有打包的功能,没有压缩功能,后来GUN计划,将整个tar和压缩功能结合在一起,提供给使用者更方便并且更强大的压缩和打包功能。
3、gzip和zcat指令
gzip可以说是应用度最广的压缩指令。常用语法如下:
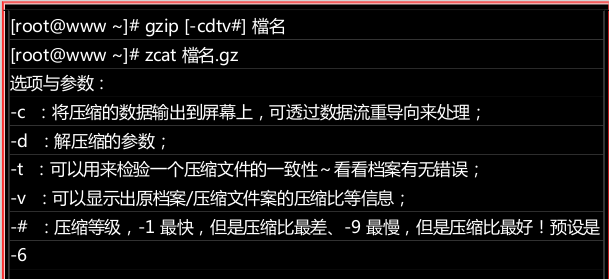
gzip的压缩已经优化过了,虽然gzip提供了1~9的压缩等级,但使用默认的6就非常好用了。
cat可以读取纯文本,zcat则可以读取纯文本被压缩过的压缩文件。
3、bzip和bzcat
bzip2的压缩比gzip还要好,bzip2则是为了取代gzip被提供更佳的压缩比而来的。

同样bzcat可以读取bzip2压缩后的文件。
4、打包指令tar
gzip和bzip2大多仅能针对单一档案来进行压缩,虽然gzip和bzip2也能够针对目录进行压缩,不过这两个指令对目录的压缩指的是将目录内的所有档案分别进行压缩。而不是将目录里的档案打包成一个档案在进行压缩。
tar常用的指令如下:

tar不会主动产生建立档名,需要自己定义,因此最好加上扩展名。[-f filename]需要链接在一起,理论傻瓜选项的顺序是可以变换的。但是[-jvfc filename]事实上会导致档案名为c。所以建议tar指令的时候,将-f filename与其他选项单独出来。
查看档名可以使用tar -jtv -f *.tar.bz2,加上-v这个选项,详细的档案权限和属性都会被列出来。
仅解开单一档案的方法。
tar -jxv -f filename.tar.bz2 待解开的档名
打包某目录,但不含该目录下的偶写档案的做法
可以使用--exclude=...的选项
比如tar -jcv -f filename.tar.bz2 --exclude=... 待压缩的档名。
仅备份比某个时刻还要新的档案。
可以使用--newer-mtime这个选项。
六)linux档案权限与目录配置
1、改变档案文件属性和权限
chgrp:改变档案所属群组
chown:改变档案拥有者
chmod:改变档案的权限,SUID,SGID,SBIT等等的特性
2、















 2098
2098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









