







kafka + spark streaming 集群
前提:
spark 安装成功,spark 1.6.0
zookeeper 安装成功
kafka 安装成功
步骤:
在worker1中启动kafka 生产者:
root@worker1:/usr/local/kafka_2.10-0.9.0.1# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test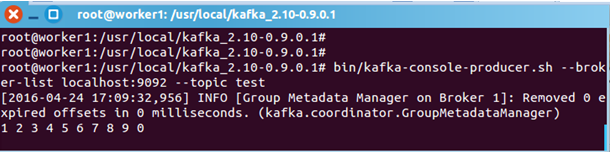
在worker2中启动消费者:
root@worker2:/usr/local/kafka_2.10-0.9.0.1# bin/kafka-console-consumer.sh --zookeeper master:2181 --topic test
生产者生产的消息,消费者可以消费到。说明kafka集群没问题。进入下一步。
在master中启动spark-shell
./spark-shell --master local[2] --packages org.apache.spark:spark-streaming-kafka_2.10:1.6.0笔者用的spark 是 1.6.0 ,读者根据自己版本调整。
shell中的逻辑代码(wordcount):
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Durations, StreamingContext}
val ssc = new StreamingContext(sc, Durations.seconds(5))
// 第二个参数是zk的client host:port
// 第三个参数是groupID
KafkaUtils.createStream(ssc, "master:2181,worker1:2181,worker2:2181", "StreamingWordCountSelfKafkaScala", Map("test" -> 1)).map(_._2).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
ssc.start
生产者再生产消息:

spark streaming的反应:
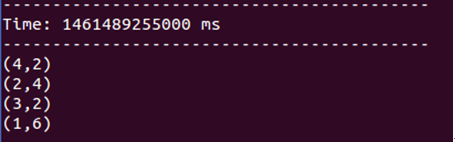
返回worker2查看消费者

可见,groupId不一样,相互之间没有互斥。
上述是使用 createStream 方式链接kafka
还有更高效的方式,请使用createDirectStream
参考:
http://spark.apache.org/docs/latest/streaming-kafka-integration.html















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









