







上一篇文章提到过方法,本文单独拿出来作为一个主题。
架构如下:

这里ansj分词器为了支持动态添加词汇,使用了Redis组件。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
首先要明白动态支持意味着:
1)内存中支持动态增加/删除
2)文件中支持动态增加/删除
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
先解决第2个问题:文件动态支持
从AddTermRedisPubSub 类中知道文件支持是由FileUtils类支持的。
FiltUtils添加如下两个方法:
public static void appendStopWord(String content) {
try {
File file = new File(
AnsjElasticConfigurator.environment.configFile(),
AnsjElasticConfigurator.DEFAULT_STOP_FILE_LIB_PATH);
// "ansj/stopLibrary.dic");
appendFile(content, file);
} catch (IOException e) {
logger.error("read exception", e, new Object[0]);
e.printStackTrace();
}
}
public static void removeStopWord(String content) {
try {
File file = new File(
AnsjElasticConfigurator.environment.configFile(),
AnsjElasticConfigurator.DEFAULT_STOP_FILE_LIB_PATH);
// "ansj/stopLibrary.dic");
removeFile(content, file, false);
} catch (FileNotFoundException e) {
logger.error("file not found $ES_HOME/config/ansj/stopLibrary.dic");
e.printStackTrace();
} catch (IOException e) {
logger.error("read exception", e, new Object[0]);
e.printStackTrace();
}
}测试过程中发现:添加一个停词,会打出一些不必要的日志:
[2014-06-16 11:59:13,847][INFO ][ansj-redis-msg-file ] match is true text iswill
[2014-06-16 11:59:13,847][INFO ][ansj-redis-msg-file ] match is true text iswith
[2014-06-16 11:59:13,847][INFO ][ansj-redis-msg-file ] match is true text iswithin
[2014-06-16 11:59:13,847][INFO ][ansj-redis-msg-file ] match is true text iswithout于是将FileUtils类的removeFile方法的
logger.info("match is {} text is{}",
new Object[] { Boolean.valueOf(match(content, text, head)),
text });
注释掉即可。
AddTermRedisPubSub类添加:
else if ("stop".equals(msg[0])) {
if ("c".equals(msg[1])) {
// add one stopWord into memory
AnsjElasticConfigurator.filter.add(msg[2]);
// add one stopWord into file
FileUtils.appendStopWord(msg[2]);
} else if ("d".equals(msg[1])) {
// remove one stopWord from memory
AnsjElasticConfigurator.filter.remove(msg[2]);
// remove one stopWod from file
FileUtils.removeStopWord(msg[2]);
}
}最后就是stopLibrary.dic的最后一行要添加一个换行符,否则后面添加的单词会跟原先最后一个单词位于同一行。
这样,就完成了动态支持redis添加停词的功能。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
下面介绍ansj如何添加同义词功能!
在Lucene4.6中通过lucene-analyzers-common-4.6.1.jar内的SynonymFilterFactory实现中文同义词非常方便,
只需几行代码和一个同义词词典。
~~~~~~~~~~~~~~~~~~~
首先,修改启动类:AnsjElasticConfigurator
public static SynonymFilterFactory factory = null;
public static String DEFAULT_SYNONYM_FILE_LIB_PATH = "ansj/synonyms.dic";
public static void loadSynonymFilter(Settings settings) {
Version ver = Version.LUCENE_46;
Map<String, String> filterArgs = new HashMap<String, String>();
filterArgs.put("luceneMatchVersion", ver.toString());
File path = new File(environment.configFile(), settings.get("synonyms",
DEFAULT_SYNONYM_FILE_LIB_PATH));
filterArgs.put("synonyms", path.getAbsolutePath());
logger.info("synonyms.dict absolute path: " + path.getAbsolutePath());
filterArgs.put("expand", "true");
factory = new SynonymFilterFactory(filterArgs);
try {
factory.inform(new FilesystemResourceLoader());
} catch (Exception e) {
// Exception happens here!
logger.info("load ansj/synonyms.dic fail,detail is as follows:"
+ e.toString());
}
}
public static void init(Settings indexSettings, Settings settings) {
if (isLoaded()) {
return;
}
environment = new Environment(indexSettings);
initConfigPath(settings);
loadFilter(settings);
loadSynonymFilter(settings);
try {
preheat();
logger.info("ansj preheat done! It can be used now!");
} catch (Exception e) {
logger.error("ansj preheat fail,please check file path.");
}
initRedis(settings);
setLoaded(true);
}
编译成功。
将编译好的2个class文件放入到elasticsearch-analysis-ansj-0.2.jar中,替换相应的文件即可。
紧接着修改:AnsjIndexAnalysis.java
@Override
protected TokenStreamComponents createComponents(String fieldName,
final Reader reader) {
// TODO Auto-generated method stub
Tokenizer tokenizer = new AnsjTokenizer(new IndexAnalysis(
new BufferedReader(reader)), reader, filter, pstemming);
return new TokenStreamComponents(tokenizer,
AnsjElasticConfigurator.factory.create(tokenizer));
}AnsjAnalysis.java
@Override
protected TokenStreamComponents createComponents(String fieldName,
final Reader reader) {
// TODO Auto-generated method stub
Tokenizer tokenizer = new AnsjTokenizer(new ToAnalysis(
new BufferedReader(reader)), reader, filter, pstemming);
// add by smallblack
return new TokenStreamComponents(tokenizer,
AnsjElasticConfigurator.factory.create(tokenizer));
}编译成功后放入ansj_lucene4_plug-1.3.jar,替换相应文件即可。
然后启动es之前务必在ansj下添加synonyms.dic文件。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~但是目前只是静态支持,我们希望动态支持。
先修改FileUtils.java文件
public static void appendSynonymWord(String content) {
try {
File file = new File(
AnsjElasticConfigurator.environment.configFile(),
AnsjElasticConfigurator.DEFAULT_SYNONYM_FILE_LIB_PATH);
// "ansj/stopLibrary.dic");
appendFile(content, file);
} catch (IOException e) {
logger.error("read ansj/synonyms.dic exception", e, new Object[0]);
e.printStackTrace();
}
}
public static void removeSynonymWord(String content) {
try {
File file = new File(
AnsjElasticConfigurator.environment.configFile(),
AnsjElasticConfigurator.DEFAULT_SYNONYM_FILE_LIB_PATH);
// "ansj/stopLibrary.dic");
removeFile(content, file, false);
} catch (FileNotFoundException e) {
logger.error("file not found $ES_HOME/config/ansj/synonyms.dic");
e.printStackTrace();
} catch (IOException e) {
logger.error("read exception", e, new Object[0]);
e.printStackTrace();
}
}然后修改AddTermRedisPubSub.java文件
} else if ("stop".equals(msg[0])) {
if ("c".equals(msg[1])) {
AnsjElasticConfigurator.filter.add(msg[2]);
FileUtils.appendStopWord(msg[2]);
} else if ("d".equals(msg[1])) {
AnsjElasticConfigurator.filter.remove(msg[2]);
FileUtils.removeStopWord(msg[2]);
}
} else if ("syn".equals(msg[0])) {
if ("c".equals(msg[1])) {
FileUtils.appendSynonymWord(msg[2]);
} else if ("d".equals(msg[1])) {
FileUtils.removeSynonymWord(msg[2]);
}
AnsjElasticConfigurator.factory
.inform(new FilesystemResourceLoader());
}编译,加入到elasticsearch-analysis-ansj-0.2.jar.
测试结果:

然后添加同义词

再查看效果:
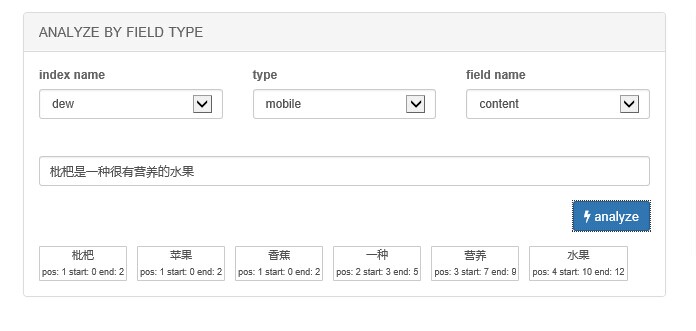
再尝试下同义词的动态删除

再查看分词效果

又回来了。
任务解决!















 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









