








目录
一、背景
MongoDB 提供了非常强大的性能分析及监控的命令,诸如 mongostat、mongotop 可以让我们对数据库的运行态性能了如指掌。
然而,这次我们在性能环境上就遇到一个非常棘手的问题:
某服务接口在 1-5分钟内偶现超时导致业务失败!
在接口调用上返回超时属于前端的判断,通常是设置的一个阈值(比如 3s)。
由于问题是偶现,且没办法发现有明显的规律,很难直接判断出原因。
而平台在做了微服务拆分之后,问题定位的难度加大了不少,且当前的调用链功能也不够完善。
二、问题定界
业务诊断
在一番分析后,梳理出接口调用的关系图如下:
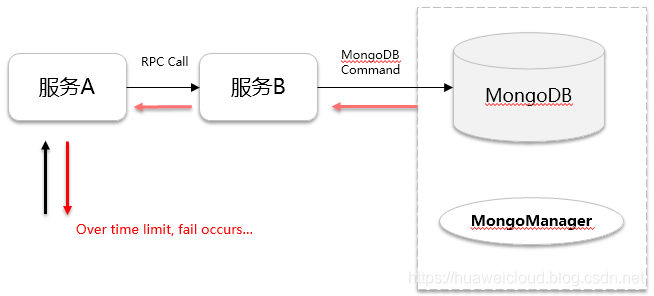
其中,服务A 通过 RPC调用服务B的接口,而服务B 又通过 MongoDB 进行数据读写。
MongoManager 是 用于管理 MongoDB 的一个代理服务,主要是实现一些数据备份、监控的任务。
在采集了一些数据之后,我们基本把问题范围锁定到了 MongoDB 数据库上面,这些手段包括:
通过对服务A、服务B的接口监控进行观测
通过wiredshark 抓包,分析 DB读写上的响应包时延
通过CommandListener,将1s 以上的慢操作指标进行输出
从接口监控及 wiredshark 抓包结果中确认到,DB 操作的响应时间都出现了偶现的超长(3s以上)。
而通过 CommandListener 将慢操作输出统计后,得到的图表如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1168
1168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









