






sort :排序
默认的情况下是按照字符排序
-n : 按照数值排序
-u : 不出现重复的行
-r : 逆向排序
-t : 指定分段的符号
-k : 指定的第几个段
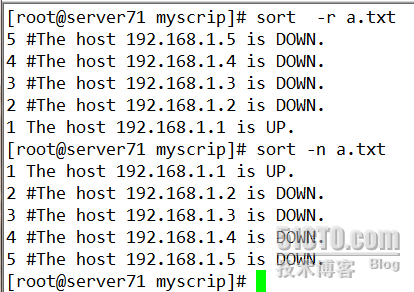
默认的情况下是按照字符排序
-n : 按照数值排序
-u : 不出现重复的行
-r : 逆向排序
-t : 指定分段的符号
-k : 指定的第几个段
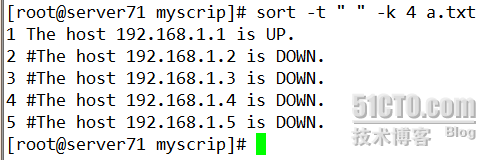
如果我想按照IP地址进行排序,可以使用- t和-k结合起来
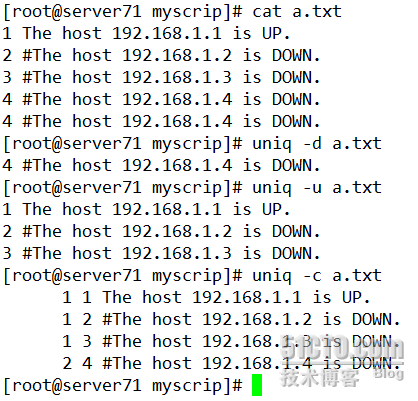
uniq 相当于sort -u
sort | uniq=sort -u
uniq -u 只显示不重复的行
-d 只显示重复的行
-c 显示出现的几次
讲到uniq,就需要重新编辑一下a.txt文件了
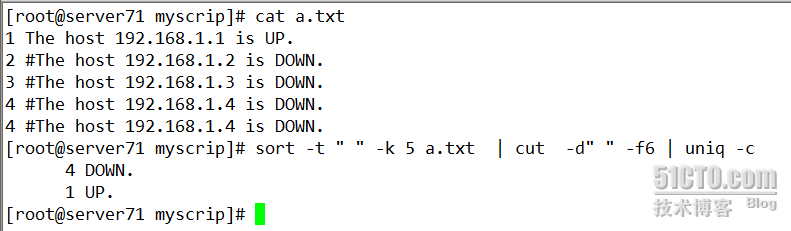
当然也可以显示特定的字符串显示的次数
如图所示:
转载于:https://blog.51cto.com/luoweiro/621992















 585
585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









