







背景
近年来,人工智能与数据科学领域发展迅速,传统项目在演化中也越来越复杂了,如何管理大量的机器学习项目成为一个难题。
在真正的机器学习项目中,我们需要在模型之外花费大量的时间。比如:
- 跟踪实验效果
机器学习算法有可配置的超参通常都是十几个到几十个不等,如何跟踪这些参数、代码以及数据在每个实验中的表现目前业界也没有一个统一的解决方案,更多都是根据某个实验进行单独的开发。
- 部署ML模型
部署ML模型通常都需要将模型文件和线上环境Service/Spark Job/SDK(Java/Scala/C++)对接,而大部分数据科学家通常都不太熟悉这些工程开发语言。因此,将模型迁移到不同平台是具有挑战性的,它意味着数据科学家还需要考虑线上部署的性能问题,目前业界也缺少比较通用的模型部署工具。
目前,在大厂内部已经孵化出这样的一些机器学习平台,比如 Uber 的 Michelangelo、Google 的 TFX,但是他们都与大厂的基础架构深度耦合,所以也没有在开源社区流行起来。
在这样的背景下, mlflow 框架横空出世,它的出现旨在将效果追踪、模型调参、模型训练、模型代码、模型发布等模块集中一处,提升数据科学工作流的管理效率。

简介
mlflow 将数据科学工作流分为3个部分:
- 模型追踪:支持记录和查询实验周围的数据,如评估指标和参数
- 项目管理:如何将模型封装在 pipeline 中,以便与可重复执行
- 模型发布:管理模型部署并提供 RestFul API

模型追踪:
mlflow tracking 提供了一个入口,用于将机器学习的参数、代码版本、代码路径、评估指标等统一管理,输出到系统中可视化管理。通常我们模型会迭代很多次,这样每次输出的结果就可以集中对比效果的好坏。
比如:
library(mlflow)
# 记录超参
my_int <- mlflow_param("my_int", 1, "integer")
my_num <- mlflow_param("my_num", 1.0, "numeric")
# 记录指标
mlflow_log_metric("accuracy", 0.45)
# 记录输出文件(模型、feature importance图)等
mlflow_log_atrifact("roc.png")
mlflow_log_artifact("model.pkl")项目管理

mlflow project 提供了打包可重用数据科学代码的标准格式,项目通过本地文件/git管理代码,通过 yaml 文件来描述。
name: FinanceR Project
conda_env: conda.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: double, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"codna 将提供统一的虚拟环境服务,通过 mlflow run 可以任意执行项目的 pipeline
mlflow run example/project -P num_dimensions=5
mlflow run git@github.com:xxx/xxx.git -P num_dimensions=5下面举一个官网的具体例子:
举例
初始化
devtools::install_github("mlflow/mlflow", subdir = "mlflow/R/mlflow")
mlflow::mlflow_install()模型参数
# Sample R code showing logging model parameters
library(mlflow)
# Define parameters
my_int <- mlflow_param("my_int", 1, "integer")
my_num <- mlflow_param("my_num", 1.0, "numeric")
my_str <- mlflow_param("my_str", "a", "string")
# Log parameters
mlflow_log_param("param_int", my_int)
mlflow_log_param("param_num", my_num)
mlflow_log_param("param_str", my_str)模型训练
# Sample R code training a linear model
library(mlflow)
# Read parameters
column <- mlflow_log_param("column", 1)
# Log total rows
mlflow_log_metric("rows", nrow(iris))
# Train model
model <- lm(Sepal.Width ~ iris[[column]], iris)
# Log models intercept
mlflow_log_metric("intercept", model$coefficients[["(Intercept)"]])线上实验
library(mlflow)
# Create and activate the “R-Test” experiment
mlflow_create_experiment("R-Test")
mlflow_active_run()启动界面
mlflow_ui()默认需要在浏览器中访问 localhost:5000

添加注释
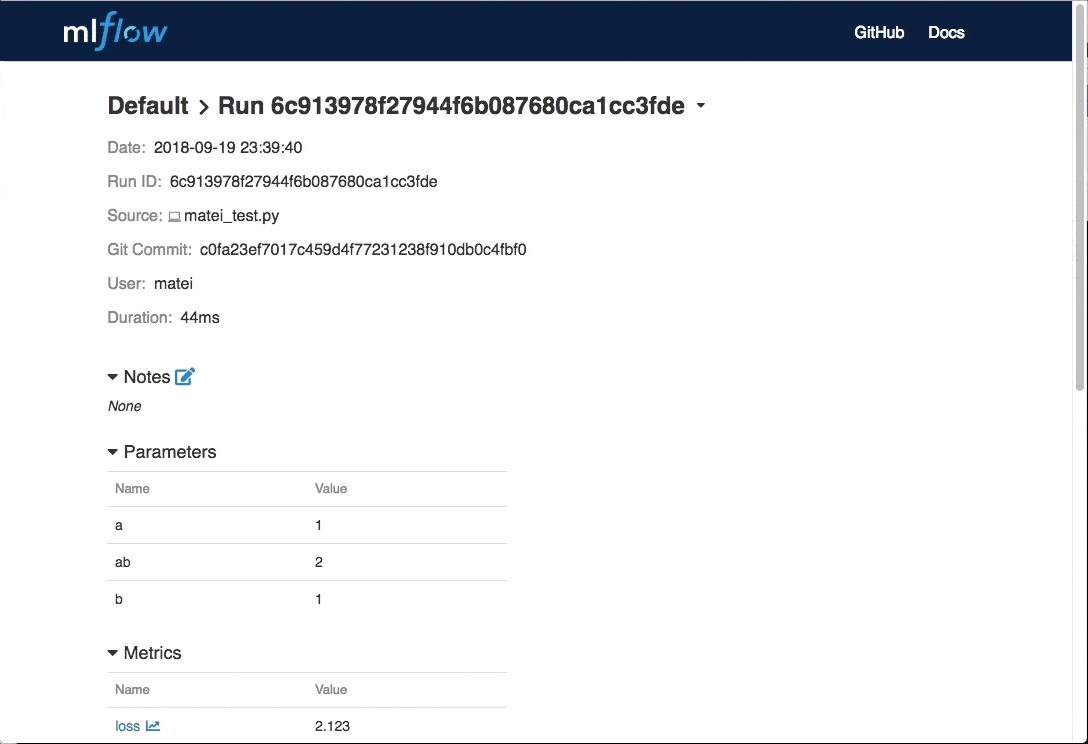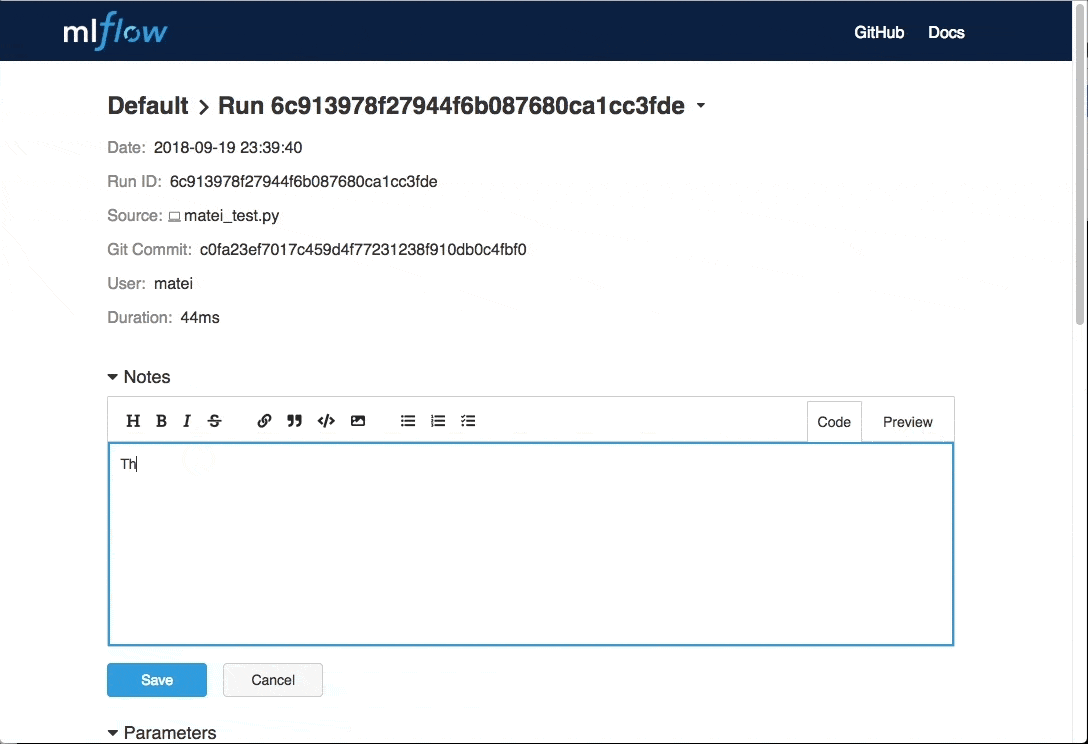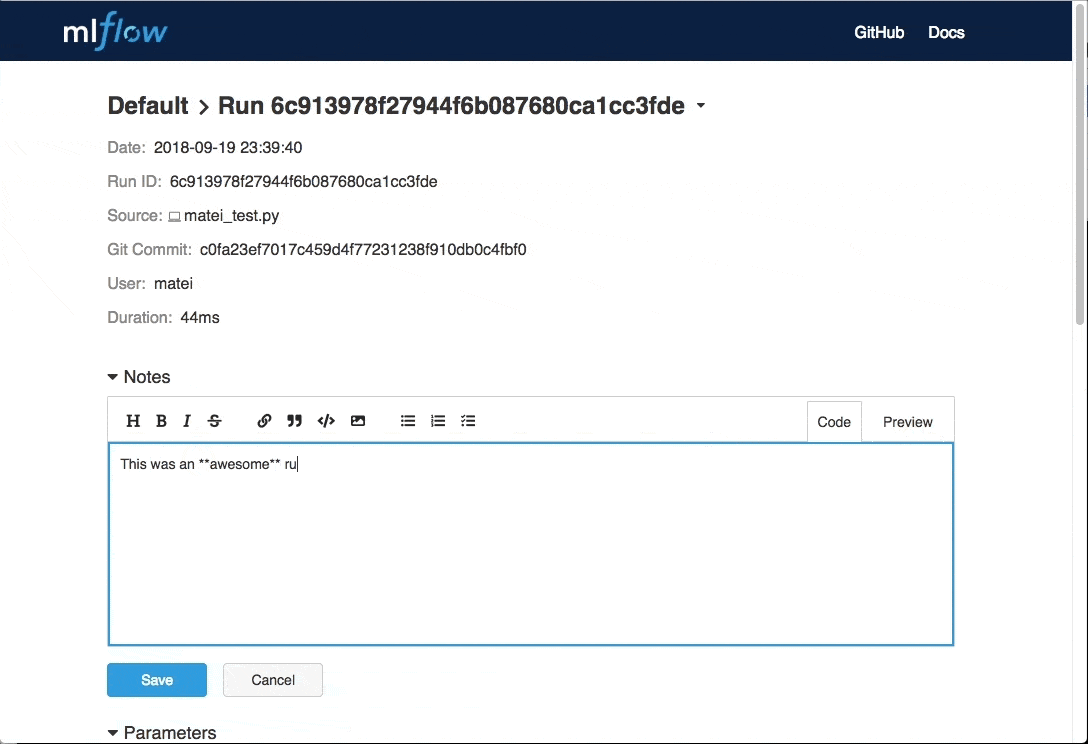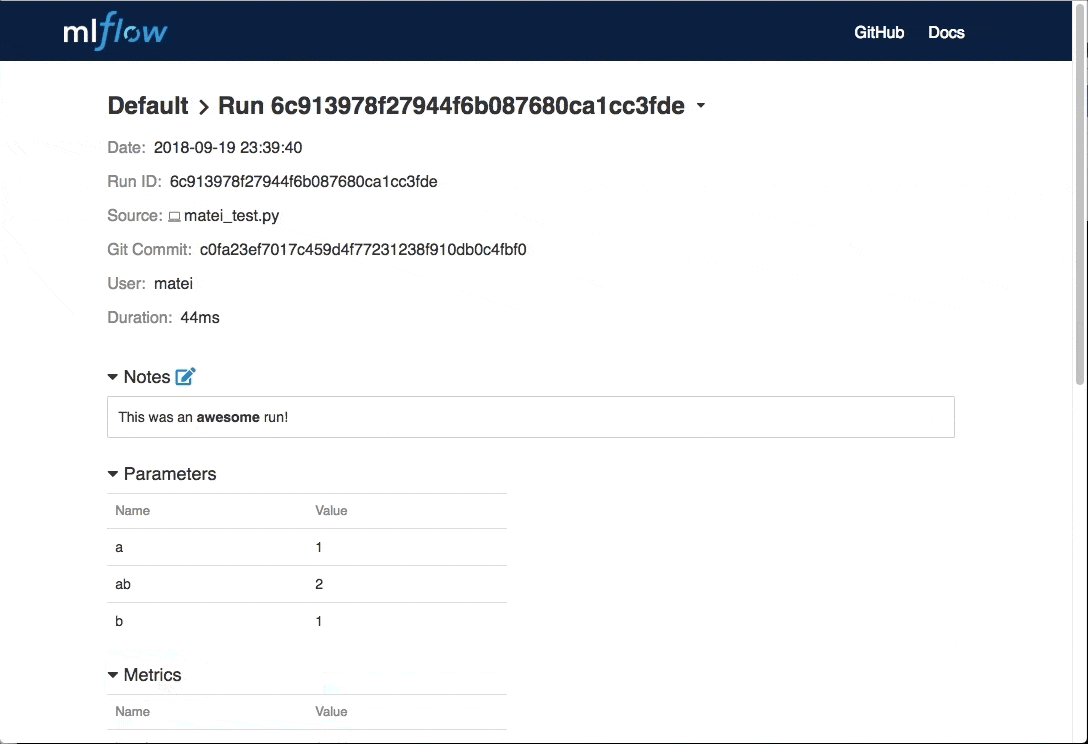
超参调优

超参调优支持3种模式:
- Random: 完全随机探索策略
- Gpyopt: 基于高斯过程的探索策略
- Hyperopt: 基于数据库的分布式探索方法
mlflow run -e random --experiment-id <hyperparam_experiment_id> -P \
training_experiment_id=<individual_runs_experiment_id> examples/r_wine --entry-point train.R其中 train.R 为
library(mlflow)
# read parameters
column <- mlflow_log_param("column", 1)
# log total rows
mlflow_log_metric("rows", nrow(iris))
# train model
model <- lm(
Sepal.Width ~ x,
data.frame(Sepal.Width = iris$Sepal.Width, x = iris[,column])
)
# log models intercept
mlflow_log_metric("intercept", model$coefficients[["(Intercept)"]])
# save model
mlflow_save_model(
crate(~ stats::predict(model, .x), model)
)模型部署
mlflow rfunc serve model
模型推断
mlflow_rfunc_predict("model", data = data.frame(x = c(0.3, 0.2)))## Warning in mlflow_snapshot_warning(): Running without restoring the
## packages snapshot may not reload the model correctly. Consider running
## 'mlflow_restore_snapshot()' or setting the 'restore' parameter to 'TRUE'.
## 3.400381396714573.40656987651099
## 1 2
## 3.400381 3.406570或者在命令行中调用
mlflow rfunc predict model data.json总结
mlflow 的出现极大方便了炼丹师傅们的工作,提供了堪比 michelangelo 的用户体验,并且全面支持 sklearn、spark、pytorch、tensorflow、mxnet、mlr、xgboost、keras 等主流算法框架。更多 mlflow 的详细资料可以参见官方文档。
参考资料
- MLflow v0.7.0 Features New R API by RStudio
- mlflow-r-interface-for-mlflow
- mlflow hyperparam
- https://www.slideshare.net/da...
- Uber michelangelo
作为分享主义者(sharism),本人所有互联网发布的图文均遵从CC版权,转载请保留作者信息并注明作者 Harry Zhu 的 FinanceR专栏: https://segmentfault.com/blog...,如果涉及源代码请注明GitHub地址: https://github.com/harryprince。微信号: harryzhustudio
商业使用请联系作者。















 1349
1349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









