







2.安装rsync
我们的Ubuntu 12.10版本默认安装了rsync,我们可以通过以下命令来安装或者更新rsync

3.安装hadoop,家林把下载下来的最新稳定版本的hadoop保存在电脑本地的以下位置:
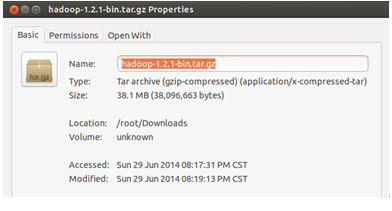
创建/usr/local/hadoop目录并把下载下来的Hadoop解压/usr/local/hadoop中:


4.在hadoop-env.sh配置Java安装信息.
进入/usr/local/Hadoop/Hadoop-1.2.1/conf
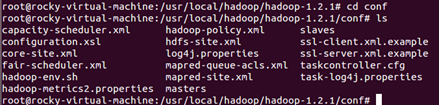
打开hadoop-env.sh:

按下回车即可进入该配置文件:
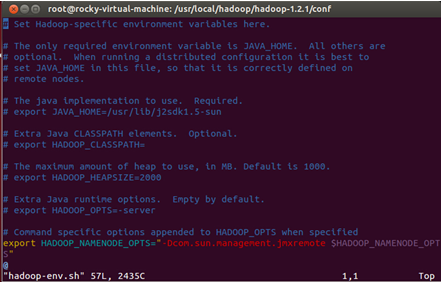
在前面我们安装Java的时候把Java安装在了“/usr/lib/java/jdk1.7.0_60”,此时我们在hadoop-env.sh配置文件加入如下配置信息

保存退出.
使用source命令使hadoop-env.sh配置信息生效:

此时Hadoop的单机模式配置成功!
为了方便我们在开机启动后也可以立即使用Hadoop的bin目录下的相关命令,可以把bin目录配置到“~/.bashrc”文件中,此时开启启动后系统自动读取“~/.bashrc”文件的内容,我就就可以随时使用Hadoop的命令了:

修改后的文件内容:

保存退出,使用下面的命令使配置生效:

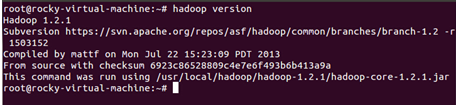
5.验证Hadoop的版本信息,使用“hadoop version”命令即可:
6.运行Hadoop自带的WordCount例子:
首先在hadoop的目录下创建一个input目录并把conf下的所有文件copy到该目录下,需要如下命令即可:

使用hadoop命令运行自带的wordcount程序并把结果输出到output中:

运行过程如下:

一直运行知道完成(因为运行过程有些长,中间省略了一些运行过程,只截取了开始和结束部分):
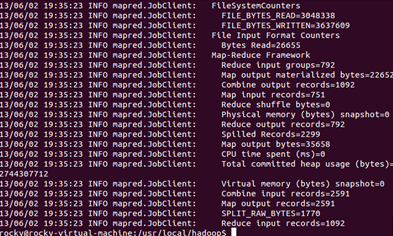
查看运行结果:

该命令执行后即显示出Wordcount运行input中若干个文件中单词统计结果,如下所示(直截取了其中一部分):
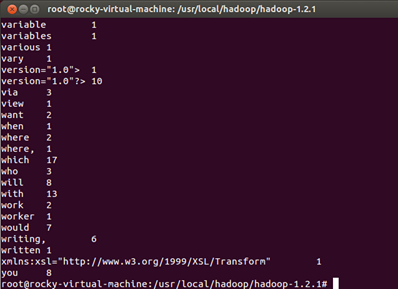
至此,单机模式的构建、配置和运行测试彻底成功!















 549
549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









