






本节书摘来自华章出版社《深入浅出DPDK》一书中的第2章,第2.6节Cache一致性,作者朱河清,梁存铭,胡雪焜,曹水 等,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
2.6 Cache一致性
我们知道,Cache是按照Cache Line作为基本单位来组织内容的,其大小是32(较早的ARM、1990年~2000年早期的x86和PowerPC)、64(较新的ARM和x86)或128(较新的Power ISA机器)字节。当我们定义了一个数据结构或者分配了一段数据缓冲区之后,在内存中就有一个地址和其相对应,然后程序就可以对它进行读写。对于读,首先是从内存加载到Cache,最后送到处理器内部的寄存器;对于写,则是从寄存器送到Cache,最后通过内部总线写回到内存。这两个过程其实引出了两个问题:
1)该数据结构或者数据缓冲区的起始地址是Cache Line对齐的吗?如果不是,即使该数据区域的大小小于Cache Line,那么也需要占用两个Cache entry;并且,假设第一个Cache Line前半部属于另外一个数据结构并且另外一个处理器核正在处理它,那么当两个核都修改了该Cache Line从而写回各自的一级Cache,准备送到内存时,如何同步数据?毕竟每个核都只修改了该Cache Line的一部分。
2)假设该数据结构或者数据缓冲区的起始地址是Cache Line对齐的,但是有多个核同时对该段内存进行读写,当同时对内存进行写回操作时,如何解决冲突?
接下来,我们先回答第一个问题,然后再回答第二个问题。
2.6.1 Cache Line对齐
对于第一个问题,其实有多种方法来解决。比如,用解决第二个问题的方法去解决它,从本质来讲,第一个问题和第二个问题都是因为多个核同时操作一个Cache Line进行写操作造成的。
另外一个简单的方法就是定义该数据结构或者数据缓冲区时就申明对齐,DPDK对很多结构体定义的时候就是如此操作的。见下例:
struct rte_ring_debug_stats {
uint64_t enq_success_bulk;
uint64_t enq_success_objs;
uint64_t enq_quota_bulk;
uint64_t enq_quota_objs;
uint64_t enq_fail_bulk;
uint64_t enq_fail_objs;
uint64_t deq_success_bulk;
uint64_t deq_success_objs;
uint64_t deq_fail_bulk;
uint64_t deq_fail_objs;
} __rte_cache_aligned;
__rte_cache_aligned的定义如下所示:
#define RTE_CACHE_LINE_SIZE 64
#define __rte_cache_aligned
__attribute__((__aligned__(RTE_CACHE_LINE_SIZE)))
其实现在编译器很多时候也比较智能,会在编译的时候尽量做到Cache Line对齐。
2.6.2 Cache一致性问题的由来
上文提到的第二个问题,即多个处理器对某个内存块同时读写,会引起冲突的问题,这也被称为Cache一致性问题。
Cache一致性问题出现的原因是在一个多处理器系统中,每个处理器核心都有独占的Cache系统(比如我们之前提到的一级Cache和二级Cache),而多个处理器核心都能够独立地执行计算机指令,从而有可能同时对某个内存块进行读写操作,并且由于我们之前提到的回写和直写的Cache策略,导致一个内存块同时可能有多个备份,有的已经写回到内存中,有的在不同的处理器核心的一级、二级Cache中。由于Cache缓存的原因,我们不知道数据写入的时序性,因而也不知道哪个备份是最新的。还有另外一个一种可能,假设有两个线程A和B共享一个变量,当线程A处理完一个数据之后,通过这个变量通知线程B,然后线程B对这个数据接着进行处理,如果两个线程运行在不同的处理器核心上,那么运行线程B的处理器就会不停地检查这个变量,而这个变量存储在本地的Cache中,因此就会发现这个值总也不会发生变化。
其实,关于一致性问题的阐述,我们附加了很多限制条件,比如多核,独占Cache,Cache写策略。如果当中有一个或者多个条件不成立时可能就不会引发一致性的问题了。
1)假设只是单核处理器,那么只有一个处理器会对内存进行读写,Cache也是只有一份,因而不会出现一致性的问题。
2)假设是多核处理器系统,但是Cache是所有处理器共享的,那么当一个处理器对内存进行修改并且缓存在Cache中时,其他处理器都能看到这个变化,因而也不会产生一致性的问题。
3)假设是多核处理器系统,每个核心也有独占的Cache,但是Cache只会采用直写,那么当一个处理器对内存进行修改之后,Cache会马上将数据写入到内存中,也不会有问题吗?考虑之前我们介绍的一个例子,线程A把结果写回到内存中,但是线程B只会从独占的Cache中读取这个变量(因为没人通知它内存的数据产生了变化),因此在这种条件下还是会有Cache一致性的问题。
因而,Cache一致性问题的根源是因为存在多个处理器独占的Cache,而不是多个处理器。如果多个处理器共享Cache,也就是说只有一级Cache,所有处理器都共享它,在每个指令周期内,只有一个处理器核心能够通过这个Cache做内存读写操作,那么就不会存在Cache一致性问题。
讲到这里,似乎我们找到了一劳永逸解决Cache一致性问题的办法,只要所有的处理器共享Cache,那么就不会有任何问题。但是,这种解决办法的问题就是太慢了。首先,既然是共享的Cache,势必容量不能小,那么就是说访问速度相比之前提到的一级、二级Cache,速度肯定几倍或者十倍以上;其次,每个处理器每个时钟周期内只有一个处理器才能访问Cache,那么处理器把时间都花在排队上了,这样效率太低了。
因而,我们还是需要针对出现的Cache一致性问题,找出一个解决办法。
2.6.3 一致性协议
解决Cache一致性问题的机制有两种:基于目录的协议(Directory-based protocol)和总线窥探协议(Bus snooping protocol)。其实还有另外一个Snarfing协议,在此不作讨论。
基于目录协议的系统中,需要缓存在Cache的内存块被统一存储在一个目录表中,目录表统一管理所有的数据,协调一致性问题。该目录表类似于一个仲裁者,当处理器需要把一个数据从内存中加载到自己独占的Cache中时,需要向目录表提出申请;当一个内存块被某个处理器改变之后,目录表负责改变其状态,更新其他处理器的Cache中的备份,或者使其他处理器的Cache的备份无效。
总线窥探协议是在1983年被首先提出来,这个协议提出了一个窥探(snooping)的动作,即对于被处理器独占的Cache中的缓存的内容,该处理器负责监听总线,如果该内容被本处理器改变,则需要通过总线广播;反之,如果该内容状态被其他处理器改变,本处理器的Cache从总线收到了通知,则需要相应改变本地备份的状态。
可以看出,这两类协议的主要区别在于基于目录的协议采用全局统一管理不同Cache的状态,而总线窥探协议则使用类似于分布式的系统,每个处理器负责管理自己的Cache的状态,通过共享的总线,同步不同Cache备份的状态。
通过之前的描述可以发现,在上面两种协议中,每个Cache Block都必须有自己的一个状态字段。而维护Cache一致性问题的关键在于维护每个Cache Block的状态域。Cache控制器通常使用一个状态机来维护这些状态域。
基于目录的协议的延迟性较大,但是在拥有很多个处理器的系统中,它有更好的可扩展性。而总线窥探协议适用于具有广播能力的总线结构,允许每个处理器能够监听其他处理器对内存的访问,适合小规模的多核系统。
接下来,我们将主要介绍总线窥探协议。最经典的总线窥探协议Write-Once由C.V. Ravishankar和James R. Goodman于1983年提出,继而被x86、ARM和Power等架构广泛采用,衍生出著名的MESI协议,或者称为Illinois Protocol。之所以有这个名字,是因为该协议是由伊利诺伊州立大学研发出来的。
2.6.4 MESI协议
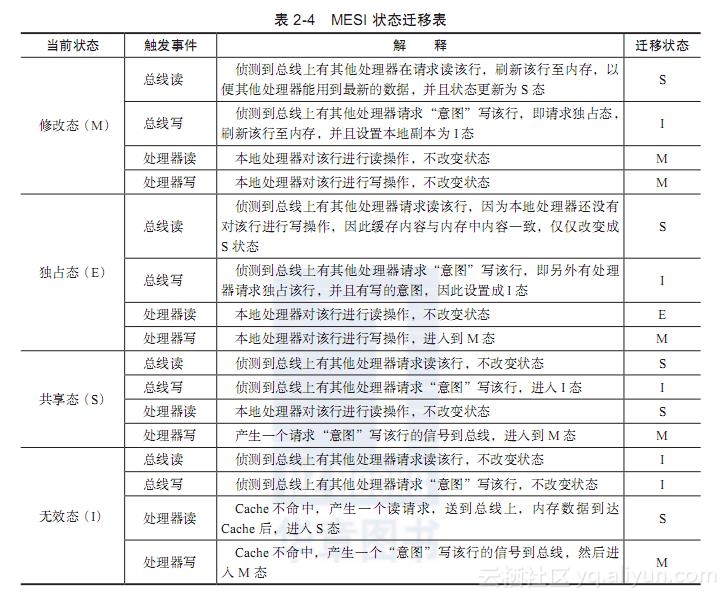
MESI协议是Cache line四种状态的首字母的缩写,分别是修改(Modified)态、独占(Exclusive)态、共享(Shared)态和失效(Invalid)态。Cache中缓存的每个Cache Line都必须是这四种状态中的一种。详见[Ref2-2]。
- 修改态,如果该Cache Line在多个Cache中都有备份,那么只有一个备份能处于这种状态,并且“dirty”标志位被置上。拥有修改态Cache Line的Cache需要在某个合适的时候把该Cache Line写回到内存中。但是在写回之前,任何处理器对该Cache Line在内存中相对应的内存块都不能进行读操作。Cache Line被写回到内存中之后,其状态就由修改态变为共享态。
- 独占态,和修改状态一样,如果该Cache Line在多个Cache中都有备份,那么只有一个备份能处于这种状态,但是“dirty”标志位没有置上,因为它是和主内存内容保持一致的一份拷贝。如果产生一个读请求,它就可以在任何时候变成共享态。相应地,如果产生了一个写请求,它就可以在任何时候变成修改态。
- 共享态,意味着该Cache Line可能在多个Cache中都有备份,并且是相同的状态,它是和内存内容保持一致的一份拷贝,而且可以在任何时候都变成其他三种状态。
- 失效态,该Cache Line要么已经不在Cache中,要么它的内容已经过时。一旦某个Cache Line被标记为失效,那它就被当作从来没被加载到Cache中。
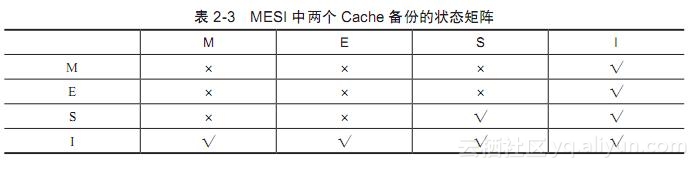
对于某个内存块,当其在两个(或多个)Cache中都保留了一个备份时,只有部分状态是允许的。如表2-3所示,横轴和竖轴分别表示了两个Cache中某个Cache Line的状态,两个Cache Line都映射到相同的内存块。如果一个Cache Line设置成M态或者E态,那么另外一个Cache Line只能设置成I态;如果一个Cache Line设置成S态,那么另外一个Cache Line可以设置成S态或者I态;如果一个Cache Line设置成I态,那么另外一个Cache Line可以设置成任何状态。
那么,究竟怎样的操作才会引起Cache Line的状态迁移,从而保持Cache的一致性呢?以下所示表2-4是根据不同读写操作触发的状态迁移表。
2.6.5 DPDK如何保证Cache一致性
从上面的介绍我们知道,Cache一致性这个问题的最根本原因是处理器内部不止一个核,当两个或多个核访问内存中同一个Cache行的内容时,就会因为多个Cache同时缓存了该内容引起同步的问题。
DPDK与生俱来就是为了网络平台的高性能和高吞吐,并且总是需要部署在多核的环境下。因此,DPDK必须提出好的解决方案,避免由于不必要的Cache一致性开销而造成额外的性能损失。
其实,DPDK的解决方案很简单,首先就是避免多个核访问同一个内存地址或者数据结构。这样,每个核尽量都避免与其他核共享数据,从而减少因为错误的数据共享(cache line false sharing)导致的Cache一致性的开销。
以下是两个DPDK为了避免Cache一致性的例子。
例子1:数据结构定义。DPDK的应用程序很多情况下都需要多个核同时来处理事务,因而,对于某些数据结构,我们给每个核都单独定义一份,这样每个核都只访问属于自己核的备份。如下例所示:
struct lcore_conf {
uint16_t n_rx_queue;
struct lcore_rx_queue rx_queue_list[MAX_RX_QUEUE_PER_LCORE];
uint16_t tx_queue_id[RTE_MAX_ETHPORTS];
struct mbuf_table tx_mbufs[RTE_MAX_ETHPORTS];
lookup_struct_t * ipv4_lookup_struct;
lookup_struct_t * ipv6_lookup_struct;
} __rte_cache_aligned; //Cache行对齐
struct lcore_conf lcore[RTE_MAX_LCORE] __rte_cache_aligned;
以上的数据结构“struct lcore_conf”总是以Cache行对齐,这样就不会出现该数据结构横跨两个Cache行的问题。而定义的数组“lcore[RTE_MAX_LCORE]”中RTE_MAX_LCORE指一个系统中最大核的数量。DPDK中对每个核都进行编号,这样核n就只需要访问lcore[n],核m只需要访问lcore[m],这样就避免了多个核访问同一个结构体。
例子2:对网络端口的访问。在网络平台中,少不了访问网络设备,比如网卡。多核情况下,有可能多个核访问同一个网卡的接收队列/发送队列,也就是在内存中的一段内存结构。这样,也会引起Cache一致性的问题。那么DPDK是如何解决这个问题的呢?
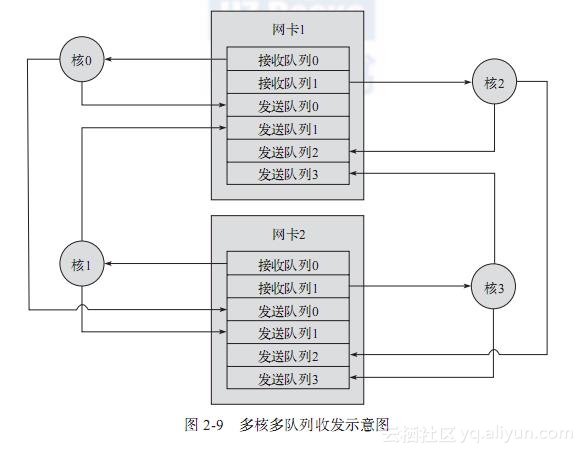
需要指出的是,网卡设备一般都具有多队列的能力,也就是说,一个网卡有多个接收队列和多个访问队列,其他章节会很详细讲到,本节不再赘述。
DPDK中,如果有多个核可能需要同时访问同一个网卡,那么DPDK就会为每个核都准备一个单独的接收队列/发送队列。这样,就避免了竞争,也避免了Cache一致性问题。
图2-9是四个核可能同时访问两个网络端口的图示。其中,网卡1和网卡2都有两个接收队列和四个发送队列;核0到核3每个都有自己的一个接收队列和一个发送队列。核0从网卡1的接收队列0接收数据,可以发送到网卡1的发送队列0或者网卡2的发送队列0;同理,核3从网卡2的接收队列1接收数据,可以发送到网卡1的发送队列3或者网卡2的发送队列3。















 260
260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









