







先来说说具体原因,具体原因就是provider端没有进行backlog设置,导致用的jdk默认配置50个,客户端超过百台,所以每次进行灰度发布后,客户端出现大量超时
这里dubbo的灰度发布我会单独写一篇文章在讲一下,这里暂且忽略
下面说下公司的应用场景
客户端以我们团队的为例,共有400台的客户端,服务端以用户团队为例,共有110多台
由于公司有个监控团队,会进行代码错误行统计,如果user每周进行二次发布,每次发布每台机器导致出现的链接超时报警统计为1条,则有400*110,就是44000,这样必定帮上有名了,这样导致团队压力巨大
那就想要进行线下模拟,先来说下异常出现的场景
服务端进行灰度发布,每次选择10台左右的数量,先进行服务端的下线,停服务,启动,上线
上线后,会通过zookeeper通知到客户端,这里会导致瞬间的链接压力
模拟
最初运维团队提供了大约50台测试机器,每台机器起两到三个进程,按照线上流程进行模拟,为出现异常
再次感谢运维团队,后来让运维团队提供了百台机器做测试机器,部署线上的服务,进行测试,问题重现
错误如下
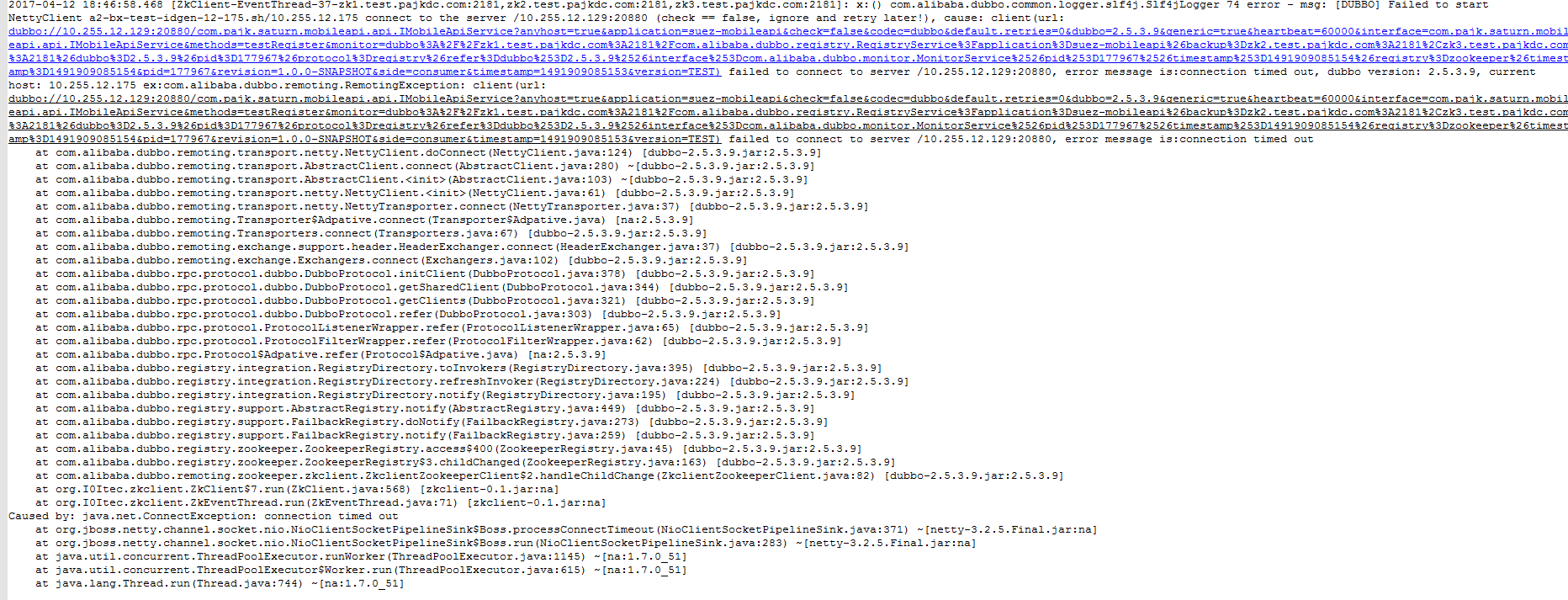
并进行抓包

增加dubbo层nettyHandler中日志输出

增加netty层NioServerSocketPipelineSink中获取连接处的日志输出
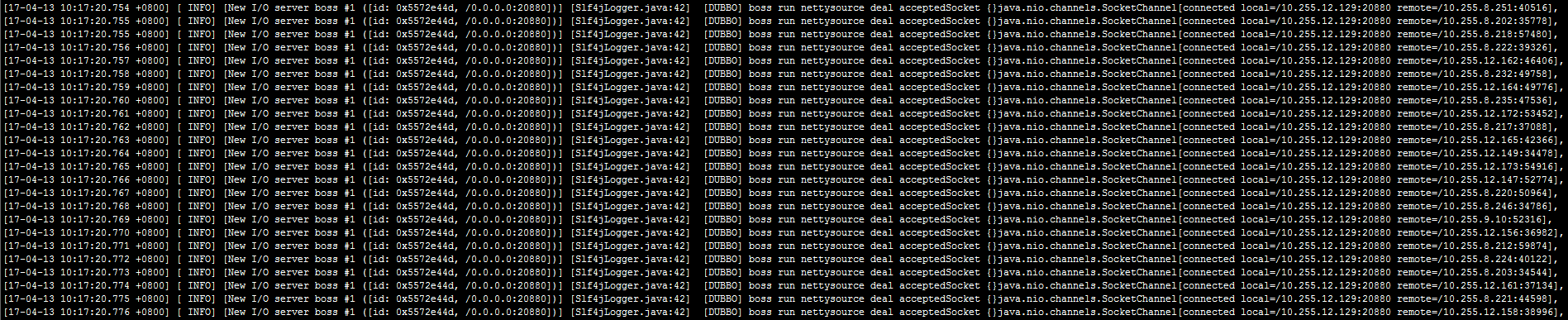
netty层日志未见任何异常,dubbo层有断开连接的异常,最初怀疑是netty层boss线程处理不过来,但是分析抓包日志后,发现客户端发出syn包后,服务端没有给出及时响应,客户端必须要在次重发syn包
服务端的日志也同样说明了这个现象
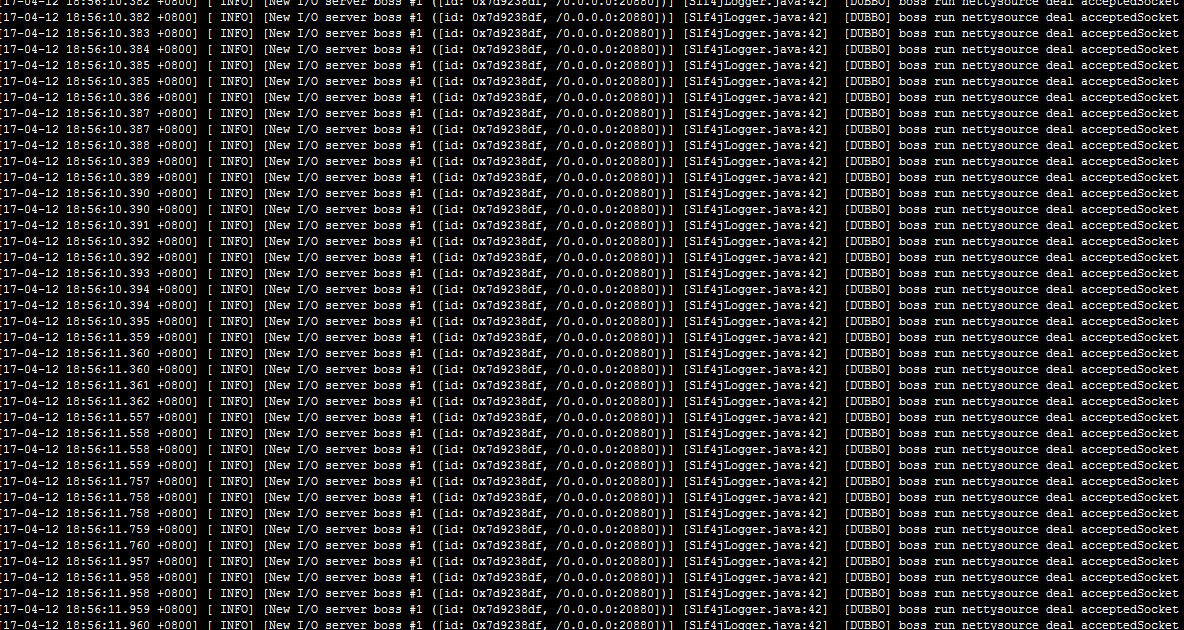
基本断定是backlog太小了,导致服务端三次握手的队列太小了,开始进行系统层面的参数调优
cat /proc/sys/net/core/netdev_max_backlog
cat /proc/sys/net/core/somaxconn
cat /proc/sys/net/ipv4/tcp_max_syn_backlog
未起作用,同事说会不会是代码层面进行了配置,于是又去翻netty的源码,发现
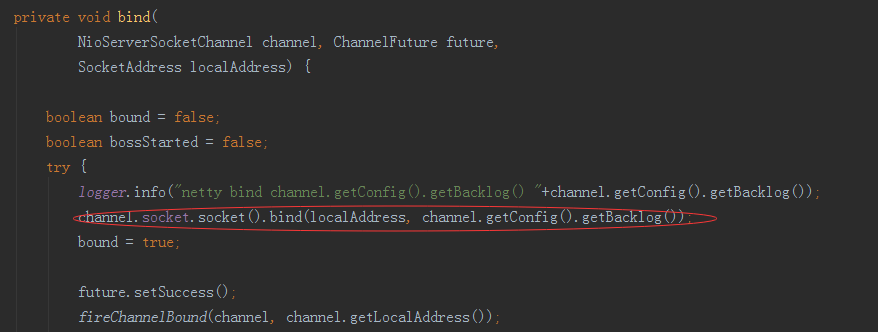
这里未设置时是0,于是取jdk的默认配置为50个,修改该参数值,问题得以解决
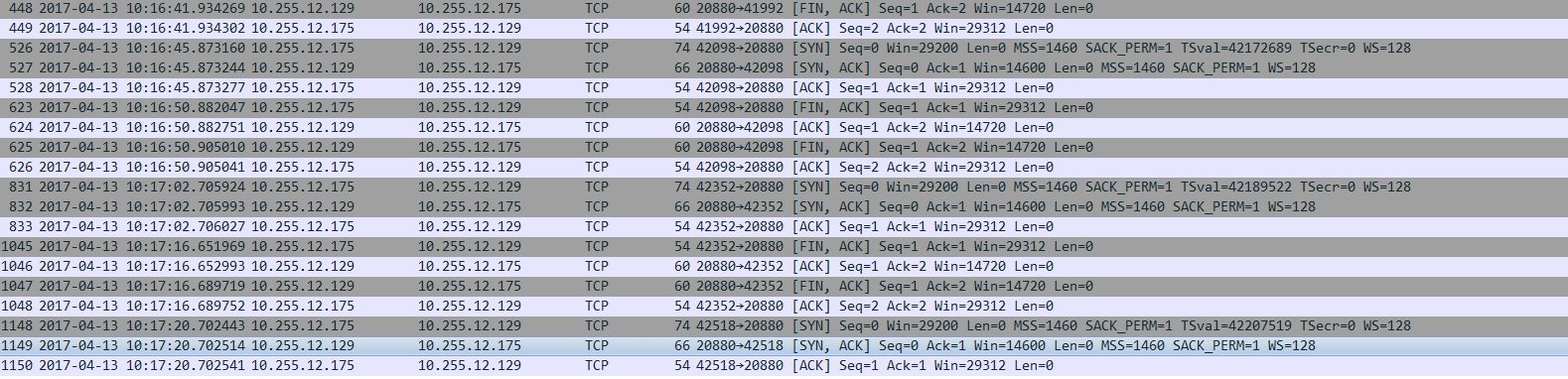
正常的TCP链接















 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









