







文中安装hadoop环境为Linux centos6.5 64位,一共4个节点,资源分布如下:
NameNode(NN): node1,node2
DataNode(DN): node2,node3,node4
ZooKeeper(ZK): node1,node2,node3
ZooKeeperFailoverController(ZKFC): node1,node2
JournalNode(JN): node2,node3,node4
ResourceManager(RM): node1
DataManager(DM): node2,node3,node4
| NN | DN | ZK | ZKFC | JN | RM | DM | |
| node01 | √ | √ | √ | √ | |||
| node02 | √ | √ | √ | √ | √ | √ | |
| node03 | √ | √ | √ | √ | |||
| node04 | √ | √ | √ |
1、系统环境准备:4台Linux 系统电脑(虚拟机)。
配置java环境变量,可参考:http://my.oschina.net/u/574036/blog/719977
4台设备设置ssh免密码登录(可选,若不设置则不能统一启动hadoop环境),可参考:http://my.oschina.net/u/574036/blog/730485
2、下载hadoop-2.7.2、zookeeper-3.4.8。
hadoop:http://apache.fayea.com/hadoop/common/
zookeeper:http://apache.fayea.com/zookeeper/
3、解压安装zookeeper,可参考: https://my.oschina.net/u/574036/blog/731167
4、解压安装hadoop(注意:hadoop-2.x 和hadoop-1.x文件目录有所不同):
(1)在第一个节点(node01)上解压hadoop到安装目录
# tar -zxvf hadoop-2.7.2.tar.gz -C ../hadoop-home/
![]()
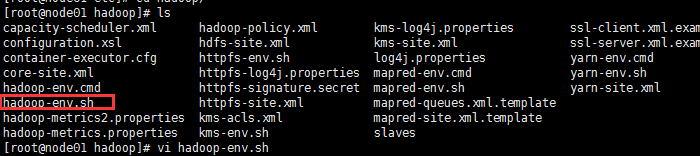
(2)修改hadoop 中java环境变量配置(hadoop-env.sh)
其中默认java环境变量为:export JAVA_HOME=${JAVA_HOME},
将其注释掉,改成:export JAVA_HOME=/home/java/jdk1.7.0_80
hadoop环境变量设置(可选)
#set hadoop environment
export HADOOP_HOME=/home/hadoop/hadoop-home/hadoop-2.8.0/
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
# vi hadoop-env.sh

(3)配置HA ,修改hdfs-site.xml配置文件,
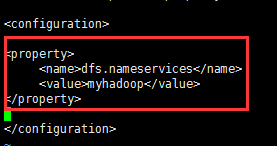
a.配置命名服务,名字为 myhadoop:
<property>
<name>dfs.nameservices</name>
<value>myhadoop</value>
</property>
b.配置所有namenode的名字,注意服务名和前面配置的命名服务一致,前面是myhadoop,
nn1、nn2为namenode名称:
<property>
<name>dfs.ha.namenodes.myhadoop</name>
<value>nn1,nn2</value>
</property>

c.配置namenode 的rpc协议端口,其中node01、node02 为namenode所在服务器名称,也可以配置为ip:
<property>
<name>dfs.namenode.rpc-address.myhadoop.nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.myhadoop.nn2</name>
<value>node02:8020</value>
</property>

d.配置namenode 的http协议端口,其中node01、node02 为namenode所在服务器名称,也可以配置为ip:
<property>
<name>dfs.namenode.http-address.myhadoop.nn1</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.myhadoop.nn2</name>
<value>node02:50070</value>
</property>

e.配置JournalNode url地址
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node02:8485;node03:8485;node04:8485/myhadoop</value>
</property>

f.配置提供客户端使用类(使用该类找到active namenode)
<property>
<name>dfs.client.failover.proxy.provider.myhadoop</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>

g.配置ssh fencing (/home/hadoop/.ssh/id_rsa 为前面配置ssh免密码登录是生成的私钥文件 )
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>

h.配置JournalNode 工作目录
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/hadoop-home/journalnode/data</value>
</property>

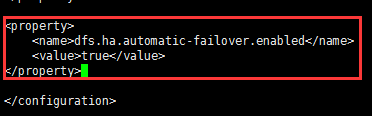
i.配置自动切换(可选,最好配置上)
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
j.配置zookeeper集群,在core-site.xml文件中配置。
(4)配置core-site.xml
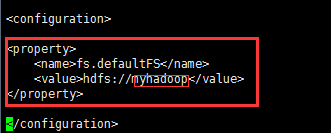
a.配置namenode入口,myhadoop为上一步配置的命名服务
<property>
<name>fs.defaultFS</name>
<value>hdfs://myhadoop</value>
</property>
b.配置zookeeper集群,定义zookeeper服务在哪些节点机器存在
<property>
<name>ha.zookeeper.quorum</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
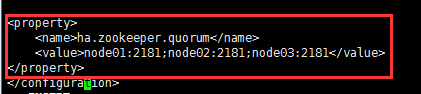
c.配置hadoop临时目录
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-home/temp</value>
</property>

5.按以上步骤将hadoop安装部署到其他节点上,我这里直接拷贝
scp -r ./* hadoop@node02:/home/hadoop/hadoop-home/
![]()
6.mapreduce配置
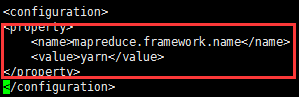
a.修改mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--
DataNode需要访问 MapReduce JobHistory Server时配置,默认值:0.0.0.0:10020
启动historyserver:sbin/mr-jobhistory-daemon.sh start historyserver
-->
<property>
<name>mapreduce.jobhistory.adress</name>
<value>127.0.0.1:10020</value>
</property>
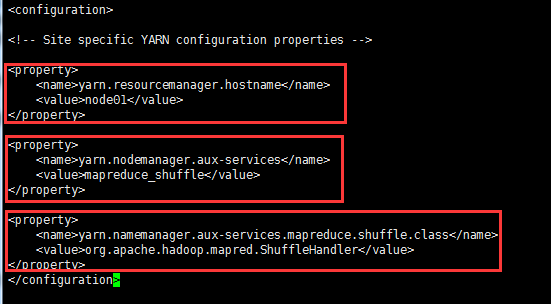
b.修改yarn-site.xml,配置resourcemanager 所在机器
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.namemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
7.slaves
node02
node03
node04
8.测试运行(注意启动顺序)
(1)启动zookeeper(在node01、node02、03 )
(2)启动journalnode(sbin目录下)
./hadoop-daemon.sh start journalnode
![]()
(3)格式化namenode(bin目录下)
a.在其中一个namenode节点上执行格式化命令
./hdfs namenode -format
![]()
b.启动已经格式化namenode的节点的 namenode(sbin目录下)
./hadoop-daemon.sh start namenode
![]()
c.复制格式化namenode节点生成的元数据,在未格式化的节点执行(bin目录下)
./hdfs namenode -bootstrapStandby
![]()
(执行该命令有可能不成功,可以直接拷贝
sudo scp -r temp/* hadoop@hadoop02:/home/hadoop/hadoop-home/temp/)
(停止hdfs stop-dfs.sh)
(启动hdfs start-dfs.sh)
d.初始化zkfc
在一个namenode节点上执行(bin目录下):
bin/hdfs zkfc -formatZK
e.全部启动
sbin/start-dfs.sh
启动成功后,访问namenode :http://node01:50070 http://node02:50070
f.上传文件:
创建目录bin/hdfs dfs -mkdir -p /home/hadoop/hadoop-files
上传文件bin/hdfs dfs -put /home/hadoop/Downloads/jdk-7u80-linux-x64.tar.gz /home/hadoop/hadoop-files
删除文件:bin/hdfs dfs -rm -r /home/hadoop/test-files/jdk-8u131-linux-x64.tar.gz
g.运行/停止全部
sbin/start-all.sh
sbin/stop-all.sh
查看resourcemanager:
http://node01:8088
到此,hadoop安装配置基本完成。















 227
227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









