






一、安装三台CentOS 7。
二、虚拟机网络设置。
1.关闭防火墙,输入命令:systemctl stop firewalld
2.设置静态ip
(1)确定网关Gateway IP

(2)分别为修改三台虚拟机/etc/sysconfig/network-scripts路径下,相应的 ifcfg-ens33文件
在终端输入:vi /etc/sysconfig/network-scripts
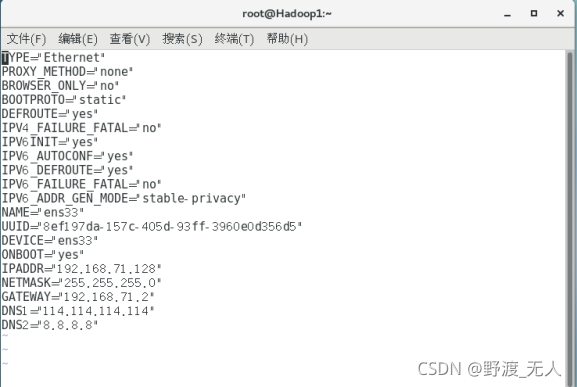
将BOOTPROTO=dhcp改为BOOTPROTO=static
并在最下面加入以下内容
IPADDR=192.168.71.128(Hadoop1)/192.168.71.129(Hadoop2)/192.168.71.130(Hadoop3) //IP
NETMASK=255.255.255.0
GATEWAY=192.168.71.2 //网关
DNS1=8.8.8.8
DNS2=114.114.114.114
(3)输入命令 systemctl restart network.service 重启网络服务;输入ifconfig即可查看刚刚配置的ip。

(4)修改三台主机名称
vi /etc/hostname
Hadoop1
vi /etc/hostname
Hadoop2
vi /etc/hostname
Hadoop3
3.配置三台主机的/etc/hosts文件,在终端输入 vi /etc/hosts,添加如图所示
内容

三.hadoop和jdk的安装
1.将hadoop-2.7.2.tar移到/opt/module目录下解压
tar –xvf hadoop-3.2.1.tar
2.将jdk-8u144-linux-x64.tar.gz移到/opt/module目录下解压
tar -zxvf jdk-8u144-linux-x64.tar.gz
3.配置环境变量,vi /etc/profile,加入如图所示环境变量

4.然后运行source /etc/profile 使文件生效
输入 java -version
javac -version
hadoop
进行测试,结果如下图

四.配置ssh免密登录
1.安装openssh-server;
yum install -y openssl openssh-server
2.修改配置文件/etc/ssh/sshd_config
vi /etc/ssh/sshd_config

3.启动ssh的服务
systemctl start sshd.service
4.设置开机自动启动ssh服务
systemctl enable sshd.service
5.设置文件夹~/.ssh的访问权限
cd ~
chmod 700 .ssh
6.设置免密登录
cd ~/.ssh/
ssh-keygen -t rsa
cat id_rsa.pub >> authorized_keys
chmod 600 ./authorized_keys
7.把三台的公钥放在一起即可完成免密验证
ssh-copy-id root@Hadoop2
ssh-copy-id root@Hadoop3
8.实验验证
ssh Hadoop2

五.配置时间服务器
对Hadoop执行1-5步操作
1.安装ntp
yum –y install ntp
2.修改配置文件 vi /etc/ntp.conf
添加:
restrict 192.168.71.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0
fudge 127.127.1.0 stratum 10
注释掉:
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst

3.修改/etc/sysconfig/ntpd文件,让硬件时间与系统时间一起同步,添加内容
SYNC_HWCLOCK=yes
echo "SYNC_HWCLOCK=yes" >> /etc/sysconfig/ntpd
4.重启ntpd服务
systemctl restart ntpd
5.设置ntpd为开机启动
systemctl enable ntpd
对Hadoop2、Hadoop3执行6
6.创建例行性命令,10分钟与时间服务器同步一次
创建/etc/cron.d/ntpupdate.cron文件,并写入:
*/10 * * * * root /usr/sbin/ntpdate Hadoop1
echo'*/10* * * * root/usr/sbin/ntpdate Hadoop1'>/etc/cron.d/ ntpupdate.cron
六.修改Hadoop配置文件,并下发至集群中的节点
1.安装rsync
2.在/usr/local/bin目录下创建xsync脚本

3.配置core-site.xml文件并下发至集群中的节点 xsync core-site.xml

4.配置hdfs-site.xml文件并下发至集群中的节点 xsync hdfs-site.xml

5.配置yarn-site.xml文件并下发至集群中的节点 xsync yarn-site.xml

6.配置mapred-site.xml文件并下发至集群中的节点 xsync mapred-site.xml

7.配置hadoop-env.sh文件、yarn-env.sh文件、mapred-env.sh文件的
JAVA_HOME:
JAVA_HOME=/opt/module/jdk1.8.0_144
xsync hadoop-env.sh
xsync yarn-env.sh
xsync mapred-env.sh
七、集群启动并测试集群
1.格式化NameNode(注:第一次启动时格式化,以后无需再进行)
bin/hdfs namenode -format
重新格式化步骤:
(1)停止所有节点上的NameNode和DataNode进程
(2)删除所有节点的data和logs文件夹(hadoop.tmp.dir)
(3)格式化NameNode
2.配置salves
vi salves
加入数据节点
Hadoop1
Hadoop2
Hadoop3
复制到集群的全部节点 xsync salves
3.启动集群
(1)启动HDFS
Hadoop1执行 sbin/start-dfs.sh
每个节点都启动NameNode
sbin/hadoop-daemon.sh start namenode
每个节点都启动DataNode
sbin/hadoop-daemon.sh start datanode
(2)启动YARN
Hadoop2(指定的ResourceManager)执行 sbin/start-yarn.sh
每个节点都启动ResourceManager
sbin/yarn-daemon.sh start resourcemanager
每个节点都启动NodeManager
sbin/yarn-daemon.sh start nodemanager
4.启动历史服务器(Hadoop1)
sbin/mr-jobhistory-daemon.sh start historyserver
5.测试
(1)jps

Hadoop1

Hadoop2

Hadoop3
(2)Web UI
使用ip+端口可以在浏览器访问 hadoop页面















 5130
5130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









