






背景
某天,在我的代码里写了如下这么一行注释,让我吃惊是注释里面的代码被执行了。
代码如下:
@Testpublic void testUnicode() { String a = "Hello"; //
a="world"; System.out.println(a); //
a="hello world!"; System.out.println(a);}猜一猜,最后执行的结果是什么?
worldhello world!是的,没看错,那二行看似“注释掉的代码”,被执行了!
原因是 Unicode 解码发生在任何词汇解码之前。而 是一个换行符,因此对注释进行了终止导致换行符后面的注释代码被执行了,上面的代码等效于下面的代码:
@Testpublic void testUnicode() { String a = "Hello"; // a="world"; System.out.println(a); // a="hello world!"; System.out.println(a);}什么是 Unicode 逃逸?
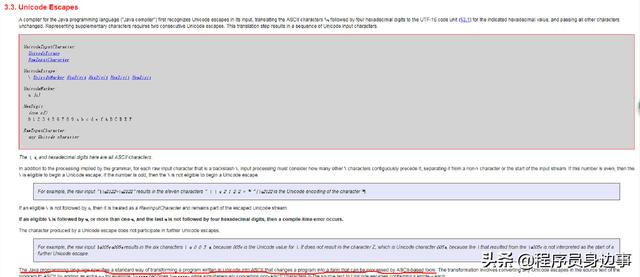
我去 oracle 官网查看了一下 Java 语言规范(JLS 3)相关的解释,大意如下:Unicode 转义用于表示仅包含 ASCII 字符的 Unicode 符号。当您需要插入无法在源文件的字符集中表示的字符时,它将派上用场。JLS 3.3节的相关说明,Unicode 转义包含一个反斜杠字符(),后跟一个或多个'u'字符和四个十六进制数字。

因此,例子中的 将被视为换行符。
下图为官方 JLS 文档。
这种机制的好处在于它可以在 ASCII 和任何其他编码之间来回切换,并且不需要你弄清楚注释的开始和结束位置!
分析求证
为了证实是不是我们分析的那样,我用了 Java 自带的工具 native2ascii 来将具有任何支持的字符编码的文件转换为具有 ASCII 或 Unicode 转义的文件。
执行如下命令便一目了然了。

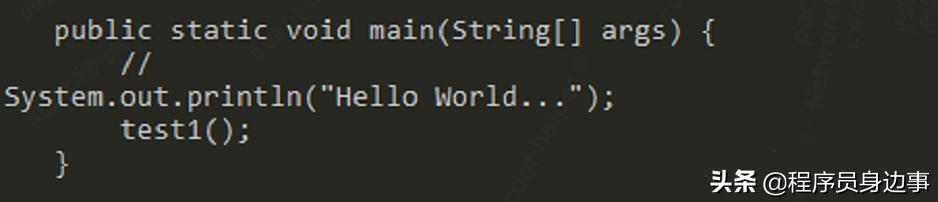
我可以发现转换后的代码被换行了!
其实,我也可以通过查看 class 字节码来发现其中的端倪。
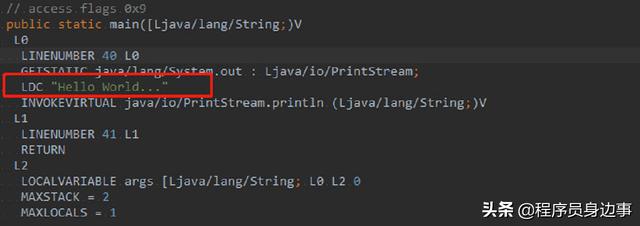
看来跟我们之前分析的一样。
总结
这个骚操作也保证了 Java 核心思想 —— 平台一致性。
虽然这个方式处理机制看似优雅,但是,它却带来了副作用(干扰语义),尤其是在评论中,我们一定要注意!
好了,留个思考题给各位同学,新建一个 Hi.java 文件,将下面的 Unicode 码拷贝到文件,看看执行结果会是什么呢?
public class Hi{public saic void mai(Sig[] ags){Sysem.ou.pil( "Hello wold");}}













 1465
1465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









