







MapReduce v1


MRv1 Question?
How to decide how many splits in total?
What's the split information format?
MapReduce v2 (YARN)
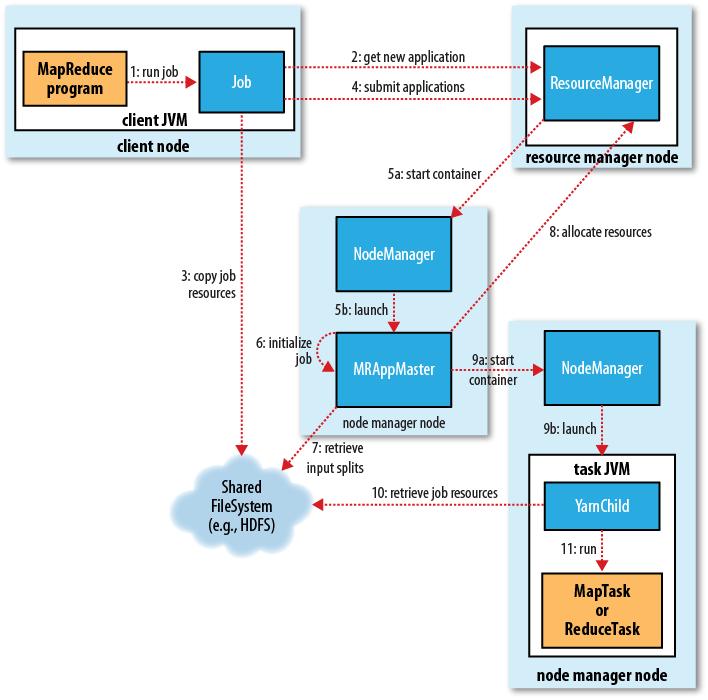
MapReduce on YARN
The client, which submits the MapReduce job.
The YARN resource manager, which coordinates the allocation of compute resources on the cluster.
The MapReduce application master, which coordinates the tasks running the MapReduce job. The application master and the MapReduce tasks run in containers that are scheduled by the resource manager and managed by the node managers.
The distributed filesystem (normally HDFS, covered in Chapter 3), which is used for sharing job files between the other entities.
Job submission
MapReduce 2 has an implementation of ClientProtocol that is activated when mapre duce.framework.name is set to yarn.
if the Job is small (<10 mappers,only 1 reducer, and an input size that is less than the size of one HDFS block), the application master may choose to run the tasks in the same JVM as itself. This happens when it judges the overhead of allocating and running tasks in new containers outweighs the gain to be had in running them in parallel, compared to running them sequentially on one node. (This is different from MapReduce 1, where small jobs are never run on a single tasktracker.) Such a job is said to be uberized, or run as an uber task.
That must be a multiple of the minimum allocation.Default memory allocations are scheduler-specific, and for the capacity scheduler, the default minimum is 1024 MB. The task is executed by a Java application whose main class is YarnChild.however, YARN does not support JVM reuse, so each task runs in a new JVM.
Every five seconds the client checks whether the job has completed by calling the waitForCompletion()
Failure
ZooKeeper-based store in the works that will support reliable recovery from resource manager failures.
Scheduler
MapReduce in Hadoop comes with a choice of schedulers. The default in MapReduce 1 is the original FIFO queue-based scheduler, and there are also multiuser schedulers called the Fair Scheduler (Jobs are placed in pools, and by default, each user gets her own pool) and the Capacity Scheduler (within each queue, jobs are scheduled using FIFO scheduling (with priorities).
Shuffle and Sort
->The Map Side:
Map->Buffer->Partitions->Sort>Compress->Spill toDisk->Combine->copy to reducers
Each map task has a circular memory buffer that it writes the output to. The buffer is 100 MB by default.Whenthe contents of the buffer reaches a certain threshold size (io.sort.spill.percent,which has the default 0.80, or 80%), a background thread will start to spill the contents to disk. Map outputs will continue to be written to the buffer while the spill takes place,but if the buffer fills up during this time, the map will block until the spill is complete.
Combinner
Before it writes to disk, the thread first divides the data into partitions corresponding to the reducers that they will ultimately be sent to. Within each partition, the background thread performs an in-memory sort by key, and if there is a combiner function, it is run on the output of the sort. Running the combiner function makes for a more compact map output, so there is less data to write to local disk and to transfer to the reducer.
Map Sort Phase
Each time the memory buffer reaches the spill threshold, a new spill file is created, so after the map task has written its last output record, there could be several spill files. Before the task is finished, the spill files are merged into a single partitioned and sorted output file. The configuration property io.sort.factor controls the maximum number of streams to merge at once; the default is 10.
It is often a good idea to compress the map output,By default, the output is not compressed, but it is easy to enable this by setting mapred.compress.map.output to true.
The output file’s partitions are made available to the reducers over HTTP. The maximum number of worker threads used to serve the file partitions is controlled by the tasktracker.http.threads property; this setting is per tasktracker, not per map task slot. The default of 40 may need to be increased for large clusters running large jobs. In MapReduce 2, this property is not applicable because the maximum number of threads used is set automatically based on the number of processors on the machine. (MapReduce 2 uses Netty, which by default allows up to twice as many threads as there are processors.)
->The Reduce Side:
Uncompress ->Merge->Memory/Spill to disk->Reduce Phase
Reduce Copy Phase
The reduce task has a small number of copier threads so that it can fetch map outputs in parallel. The default is five threads, but this number can be changed by setting the mapred.reduce.parallel.copies property.
If a combiner is specified,it will be run during the merge to reduce the amount of data written to disk.
Reduce Merge Phase
if there were 50 map outputs and the merge factor was 10 (the default, controlled by the io.sort.factor property, just like in the map’s merge), 210 | Chapter 6: How MapReduce Works there would be five rounds. Each round would merge 10 files into one, so at the end there would be five intermediate files.
Configuration Tuning
Map-side tuning properties
Reduce-side tuning properties
Task Execution
Speculative Execution
a speculative task is launched only after all the tasks for a job have been launched, and then only for tasks that have been running for some time (at least a minute) and have failed to make as much progress, on average, as the other tasks from the job. Speculative execution is an optimization, and not a feature to make jobs run more reliably.
Speculative execution is turned on by default.
mapred.map.tasks.speculative.execution
mapred.reduce.tasks.speculative.execution
yarn.app.mapreduce.am.job.speculator.class
yarn.app.mapreduce.am.job.task.estimator.class.
Output Committers
The default is FileOutputCommitter, which is appropriate for file-based MapReduce.You can customize an existing OutputCommitter or even write a new implementation if you need to do special setup or cleanup for jobs or tasks.
The OutputCommitter API is as follows (in both old and new MapReduce APIs):
public abstract class OutputCommitter {
public abstract void setupJob(JobContext jobContext) throws IOException;
public void commitJob(JobContext jobContext) throws IOException { }
public void abortJob(JobContext jobContext, JobStatus.State state) throws IOException { }
public abstract void setupTask(TaskAttemptContext taskContext) throws IOException;
public abstract boolean needsTaskCommit(TaskAttemptContext taskContext) throws IOException;
public abstract void commitTask(TaskAttemptContext taskContext) throws IOException;
public abstract void abortTask(TaskAttemptContext taskContext) throws IOException;
}Task side-effect files
One way to do this is to have a map-only job, where each map is given a set of images to convert (perhaps using NLineInputFormat}
job.setNumReduceTasks(0);
Task JVM Reuse
JVM reuse is not currently supported in MapReduce 2. There is however, the concept of an "über" task which is similar in nature but the config has gotten only more complex/fine-grained.
Skipping Bad Records
If you are using TextInputFormat (“TextInputFormat” on page 246), you can set a maximum expected line length to safeguard against corrupted files. Corruption in a file can manifest itself as a very long line, which can cause out-of-memory errors and then task failure. By setting mapred.linerecordreader.maxlength to a value in bytes that fits in memory (and is comfortably greater than the length of lines in your input data), the record reader will skip the (long) corrupt lines without the task failing.
skipping mode is turned on for a task only after it has failed twice.
1. Task fails.
2. Task fails.
3. Skipping mode is enabled. Task fails, but the failed record is stored by the tasktracker.
4. Skipping mode is still enabled. Task succeeds by skipping the bad record that failed
in the previous attempt.
Skipping mode is off by default;
Bad records that have been detected by Hadoop are saved as sequence files in the job’s output directory under the _logs/skip subdirectory. These can be inspected for diagnostic purposes after the job has completed (using hadoop fs -text, for example).
Skipping mode is not supported in the new MapReduce API.















 211
211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









