







上一篇博客分享了hive的简介和初体验,本节博主将继续分享一些hive的操作的基础知识。
DDL操作
(1)创建表
#建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
说明:
1、CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
2、EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
3、LIKE 允许用户复制现有的表结构,但是不复制数据。
4、ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive通过 SerDe 确定表的具体的列的数据。
5、STORED AS
SEQUENCEFILE|TEXTFILE|RCFILE
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
6、CLUSTERED BY
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是 针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
#具体实例
#1.创建内部表mytable
create table if not exists mytable (sid int ,sname string)
row format delimited fields terminated by '\005' stored as textfile;
#2.创建外部表pageview
create external table if not exists pageview(pageid int,page_url string comment 'The page URL')
row format delimited fields terminated by ','
location '/class03';
create external table if not exists pageview(pageid int,page_url string comment 'The page URL')
row format delimited fields terminated by ','
location 'hdfs://192.168.29.144:9000/class03';
#3.创建分区表invites
create table student_p(sno int,sname string,sex string,sage int,sdept string)
partitioned by(part string)
row format delimited fields terminated by ',' stored as textfile;
#4.创建带桶的表student
create table student(id int ,age int ,name string)
partitioned by(stat_date string)
clustered by(id) sorted by(age) into 2 buckets
row format delimited fields terminated by ',';(2)修改表
#(1)增加/删除分区
#语法结构
#新增分区
ALTER TABLE table_name ADD [IF NOT EXISTS] partition_spec [ LOCATION 'location1' ] partition_spec [ LOCATION 'location2' ] ...
partition_spec:
: PARTITION (partition_col = partition_col_value, partition_col = partiton_col_value, ...)
#删除分区
ALTER TABLE table_name DROP partition_spec, partition_spec,...
#具体实例
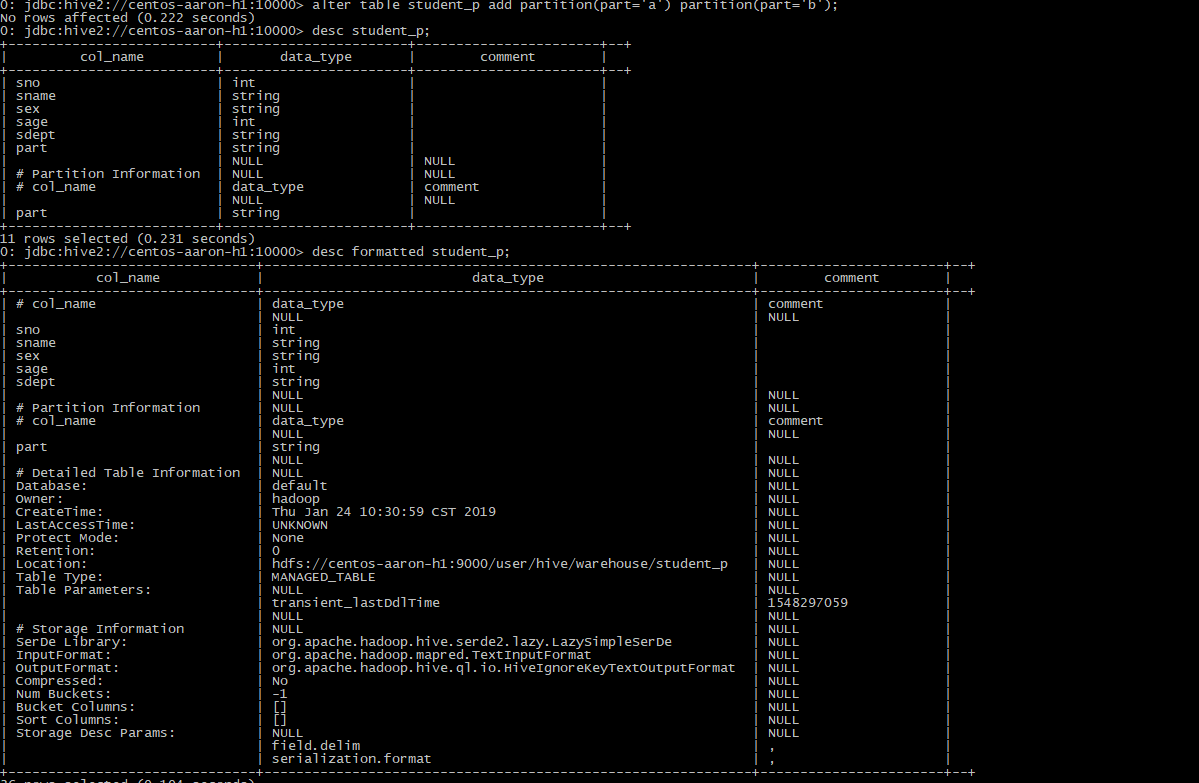
alter table student_p add partition(part='a') partition(part='b');
alter table student_p drop partition(part='a'),partition(part='b');
#查看表student_p的分区情况
show partitions student_p;
#(2)重命名表
#语法结构
ALTER TABLE table_name RENAME TO new_table_name
#具体实例
alter table student_p rename to student_p_1;
#(3)增加/更新列
#语法结构
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
#注:ADD是代表新增一字段,字段位置在所有列后面(partition列前),REPLACE则是表示替换表中所有字段
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
#具体实例
alter table student add columns (name1 string);
alter table student replace columns (id int,age int,name string);
#查询表信息
desc student;
(3)删除表
#删除表数据和结构
drop table student;
#清空表数据
truncate table student;(4)显示命令
#显示表
show tables
#显示数据库
show databases
#显示分区
show partitions t_name
#显示函数
show functions
#显示表的扩展信息
desc extended t_name;
#格式化显示表的信息
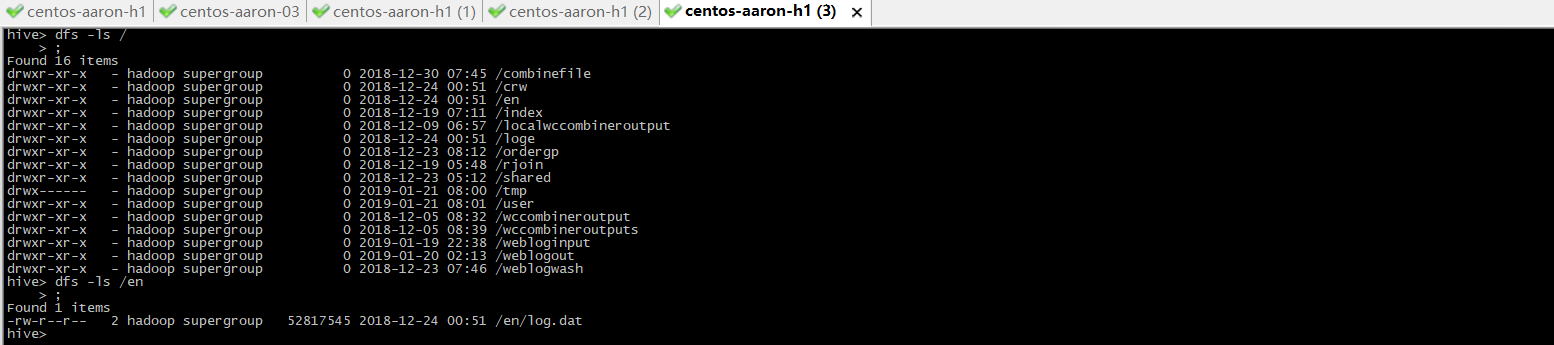
desc formatted table_name;特此说明:使用./hive命令行是支持dfs命令的,如图:
#支持命令不限,格式如下
dfs -ls /
dfs -cat /en/part-r-00001
DML操作
(1)Load导入(或加载)数据到hive
#语法结构
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO
TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
说明:
1、Load 操作只是单纯的复制/移动操作,将数据文件移动到 Hive 表对应的位置。
2、filepath:
相对路径,例如:project/data1
绝对路径,例如:/user/hive/project/data1
包含模式的完整 URI,列如:
hdfs://namenode:9000/user/hive/project/data1
3、LOCAL关键字
如果指定了 LOCAL, load 命令会去查找本地文件系统中的 filepath。
如果没有指定 LOCAL 关键字,则根据inpath中的uri[如果指定了 LOCAL,那么:
load 命令会去查找本地文件系统中的 filepath。如果发现是相对路径,则路径会被解释为相对于当前用户的当前路径。
load 命令会将 filepath中的文件复制到目标文件系统中。目标文件系统由表的位置属性决定。被复制的数据文件移动到表的数据对应的位置。
如果没有指定 LOCAL 关键字,如果 filepath 指向的是一个完整的 URI,hive 会直接使用这个 URI。 否则:如果没有指定 schema 或者 authority,Hive 会使用在 hadoop 配置文件中定义的 schema 和 authority,fs.default.name 指定了 Namenode 的 URI。
如果路径不是绝对的,Hive 相对于/user/进行解释。
Hive 会将 filepath 中指定的文件内容移动到 table (或者 partition)所指定的路径中。]查找文件
4、OVERWRITE 关键字
如果使用了 OVERWRITE 关键字,则目标表(或者分区)中的内容会被删除,然后再将 filepath 指向的文件/目录中的内容添加到表/分区中。
如果目标表(分区)已经有一个文件,并且文件名和 filepath 中的文件名冲突,那么现有的文件会被新文件所替代。 #具体实例:
#1、相对路径,放在beeline启动目录
load data local inpath 'student_p.txt' overwrite into table student_p partition (part='2019-01-26');
#2、绝对路径
load data local inpath '/home/hadoop/student_p.txt' overwrite into table student_p partition (part='2019-01-26');
#3、加载包含模式数据
load data inpath 'hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p/part=2019-01-26/student_p.txt' overwrite into table student_p partition (part='2019-01-27');
#查询分区表数据
select * from student_p where part='2019-01-27'(2)Insert
#将查询结果插入Hive表
#语法结构
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement
Multiple inserts:
FROM from_statement
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1
[INSERT OVERWRITE TABLE tablename2 [PARTITION ...] select_statement2] ...
Dynamic partition inserts:
INSERT OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement#具体实例
1、基本模式插入。
INSERT OVERWRITE TABLE student_p PARTITION (part='2019-01-24') select sno,sname,sex,sage,sdept FROM student_p where part='2019-01-27';
2、多插入模式
FROM student_p
INSERT OVERWRITE TABLE student_p PARTITION (part='2019-01-25')
select sno,sname,sex,sage,sdept where part='2019-01-27'
INSERT OVERWRITE TABLE student_p PARTITION (part='2019-01-26')
select sno,sname,sex,sage,sdept where part='2019-01-27'
3、自动分区模式
INSERT OVERWRITE TABLE student_p1 PARTITION (part)
select sno,sname,sex,sage,sdept,part FROM student_p where part='2019-01-25'
#注意插入动态分区需要先设置一下参数
set hive.exec.dynamic.partition.mode=nonstrict;
#设置变量,设置分桶为true, 设置reduce数量是分桶的数量个数
set hive.enforce.bucketing = true;
set mapreduce.job.reduces=4;
#打开会往创建的分桶表插入数据(插入数据需要是已分桶, 且排序的)
#可以使用distribute by(sno) sort by(sno asc) 或是排序和分桶的字段相同的时候使用Cluster by(字段)
#注意使用cluster by 就等同于分桶+排序(sort)
insert into table stu_buck
select sno,sname,sex,sage,sdept from student distribute by(sno) sort by(sno asc);
insert into table stu_buck
select sno,sname,sex,sage,sdept from student Cluster by(sno);#导出表数据
#语法结构
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 SELECT ... FROM ...
multiple inserts:
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1
[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ...#具体实例
1、导出文件到本地
INSERT OVERWRITE LOCAL DIRECTORY '/home/hadoop/student_download.txt' SELECT * from student_p;
说明:
数据写入到文件系统时进行文本序列化,且每列用^A来区分,\n为换行符。用more命令查看时不容易看出分割符,可以使用: sed -e 's/\x01/|/g' /home/hadoop/student_download.txt来查看。
2、导出数据到HDFS
INSERT OVERWRITE DIRECTORY 'hdfs://centos-aaron-h1:9000/hs22' SELECT * from student_p;
(3)SELECT
#基本的Select操作
#语法结构
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY| ORDER BY col_list]
]
[LIMIT number]
#注:
1、order by 会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
2、sort by不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1,则sort by只保证每个reducer的输出有序,不保证全局有序。
3、distribute by根据distribute by指定的内容将数据分到同一个reducer。
4、Cluster by 除了具有Distribute by的功能外,还会对该字段进行排序。因此,当sort by字段为分桶字段时,常常认为cluster by = distribute by + sort by#具体实例
1、获取年龄大的3个学生。
select sno,sname,sage from student_p where part='2019-01-27' order by sage desc limit 3;
2、查询学生信息按年龄,降序排序
set mapred.reduce.tasks=4
select sno,sname,sage from student_p sort by sage desc;
--------------效果比较,不排序
select sno,sname,sage from student_p distribute by sage;
3、按学生名称汇总学生年龄
select sname,sum(sage) from student_p group by sname;
hive远程客户端执行效果图
最后寄语,以上是博主本次文章的全部内容,如果大家觉得博主的文章还不错,请点赞;如果您对博主其它服务器大数据技术或者博主本人感兴趣,请关注博主博客,并且欢迎随时跟博主沟通交流。
以下是所有操作效果图:
INFO : Partition default.student_p{part=2019-01-26} stats: [numFiles=1, numRows=0, totalSize=436, rawDataSize=0]
No rows affected (4.237 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> select * from student_p;
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
| student_p.sno | student_p.sname | student_p.sex | student_p.sage | student_p.sdept | student_p.part |
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
| 1 | xiaowang | 男 | 18 | 教育部 | 2019-01-26 |
| 2 | xiaohei | 女 | 11 | 小学生 | 2019-01-26 |
| 3 | 大王 | 男 | 55 | 妖精 | 2019-01-26 |
| 4 | 黑子 | 女 | 22 | 美女 | 2019-01-26 |
| 11 | xiaodong | 男 | 12 | 教育部 | 2019-01-26 |
| 21 | xiaohei | 女 | 13 | 小学生 | 2019-01-26 |
| 31 | 大王吧 | 男 | 51 | 妖精 | 2019-01-26 |
| 41 | 黑子生 | 女 | 12 | 美女 | 2019-01-26 |
| 16 | xiaowangs | 男 | 38 | 教育部 | 2019-01-26 |
| 71 | xiaoheis | 女 | 31 | 小学生 | 2019-01-26 |
| 33 | 大王s | 男 | 35 | 妖精 | 2019-01-26 |
| 43 | 黑子s | 女 | 32 | 美女 | 2019-01-26 |
| 13 | xiaodongs | 男 | 32 | 教育部 | 2019-01-26 |
| 38 | xiaoheis | 女 | 33 | 小学生 | 2019-01-26 |
| 61 | 大王吧s | 男 | 31 | 妖精 | 2019-01-26 |
| 71 | 黑子生s | 女 | 32 | 美女 | 2019-01-26 |
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
16 rows selected (0.133 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> load data local inpath 'student_p.txt' overwrite into table student_p partition (part='2019-01-26');
Error: Error while compiling statement: FAILED: SemanticException Line 1:24 Invalid path ''student_p.txt'': No files matching path file:/home/hadoop/apps/apache-hive-1.2.2-bin/bin/student_p.txt (state=42000,code=40000)
0: jdbc:hive2://centos-aaron-h1:10000> load data local inpath '../../student_p.txt' overwrite into table student_p partition (part='2019-01-26');
Error: Error while compiling statement: FAILED: SemanticException Line 1:24 Invalid path ''../../student_p.txt'': No files matching path file:/home/hadoop/apps/student_p.txt (state=42000,code=40000)
0: jdbc:hive2://centos-aaron-h1:10000> load data local inpath '/../../student_p.txt' overwrite into table student_p partition (part='2019-01-26');
Error: Error while compiling statement: FAILED: SemanticException Line 1:24 Invalid path ''/../../student_p.txt'': No files matching path file:/../../student_p.txt (state=42000,code=40000)
0: jdbc:hive2://centos-aaron-h1:10000> load data local inpath 'student_p.txt' overwrite into table student_p partition (part='2019-01-26');
INFO : Loading data to table default.student_p partition (part=2019-01-26) from file:/home/hadoop/apps/apache-hive-1.2.2-bin/bin/student_p.txt
INFO : Partition default.student_p{part=2019-01-26} stats: [numFiles=1, numRows=0, totalSize=436, rawDataSize=0]
No rows affected (2.965 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> load data inpath 'hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p/part=2019-01-26/student_p.txt' overwrite into table student_p partition (part='2019-01-27');
INFO : Loading data to table default.student_p partition (part=2019-01-27) from hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p/part=2019-01-26/student_p.txt
INFO : Partition default.student_p{part=2019-01-27} stats: [numFiles=1, numRows=0, totalSize=436, rawDataSize=0]
No rows affected (5.227 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> select * from student_p;
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
| student_p.sno | student_p.sname | student_p.sex | student_p.sage | student_p.sdept | student_p.part |
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
| 1 | xiaowang | 男 | 18 | 教育部 | 2019-01-27 |
| 2 | xiaohei | 女 | 11 | 小学生 | 2019-01-27 |
| 3 | 大王 | 男 | 55 | 妖精 | 2019-01-27 |
| 4 | 黑子 | 女 | 22 | 美女 | 2019-01-27 |
| 11 | xiaodong | 男 | 12 | 教育部 | 2019-01-27 |
| 21 | xiaohei | 女 | 13 | 小学生 | 2019-01-27 |
| 31 | 大王吧 | 男 | 51 | 妖精 | 2019-01-27 |
| 41 | 黑子生 | 女 | 12 | 美女 | 2019-01-27 |
| 16 | xiaowangs | 男 | 38 | 教育部 | 2019-01-27 |
| 71 | xiaoheis | 女 | 31 | 小学生 | 2019-01-27 |
| 33 | 大王s | 男 | 35 | 妖精 | 2019-01-27 |
| 43 | 黑子s | 女 | 32 | 美女 | 2019-01-27 |
| 13 | xiaodongs | 男 | 32 | 教育部 | 2019-01-27 |
| 38 | xiaoheis | 女 | 33 | 小学生 | 2019-01-27 |
| 61 | 大王吧s | 男 | 31 | 妖精 | 2019-01-27 |
| 71 | 黑子生s | 女 | 32 | 美女 | 2019-01-27 |
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
16 rows selected (0.123 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> select * from student_p where part='2019-01-27'
0: jdbc:hive2://centos-aaron-h1:10000> select * from student_p partition part='2019-01-27'
0: jdbc:hive2://centos-aaron-h1:10000> select * from student_p partition part='2019-01-27';
Error: Error while compiling statement: FAILED: ParseException line 2:0 missing EOF at 'select' near ''2019-01-27'' (state=42000,code=40000)
0: jdbc:hive2://centos-aaron-h1:10000> select * from student_p where part='2019-01-27';
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
| student_p.sno | student_p.sname | student_p.sex | student_p.sage | student_p.sdept | student_p.part |
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
| 1 | xiaowang | 男 | 18 | 教育部 | 2019-01-27 |
| 2 | xiaohei | 女 | 11 | 小学生 | 2019-01-27 |
| 3 | 大王 | 男 | 55 | 妖精 | 2019-01-27 |
| 4 | 黑子 | 女 | 22 | 美女 | 2019-01-27 |
| 11 | xiaodong | 男 | 12 | 教育部 | 2019-01-27 |
| 21 | xiaohei | 女 | 13 | 小学生 | 2019-01-27 |
| 31 | 大王吧 | 男 | 51 | 妖精 | 2019-01-27 |
| 41 | 黑子生 | 女 | 12 | 美女 | 2019-01-27 |
| 16 | xiaowangs | 男 | 38 | 教育部 | 2019-01-27 |
| 71 | xiaoheis | 女 | 31 | 小学生 | 2019-01-27 |
| 33 | 大王s | 男 | 35 | 妖精 | 2019-01-27 |
| 43 | 黑子s | 女 | 32 | 美女 | 2019-01-27 |
| 13 | xiaodongs | 男 | 32 | 教育部 | 2019-01-27 |
| 38 | xiaoheis | 女 | 33 | 小学生 | 2019-01-27 |
| 61 | 大王吧s | 男 | 31 | 妖精 | 2019-01-27 |
| 71 | 黑子生s | 女 | 32 | 美女 | 2019-01-27 |
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
16 rows selected (2.655 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> select * from student_p partition part='2019-01-27';
Error: Error while compiling statement: FAILED: ParseException line 1:25 cannot recognize input near 'student_p' 'partition' 'part' in from source (state=42000,code=40000)
0: jdbc:hive2://centos-aaron-h1:10000> select * from student_p where part='2019-01-27'
0: jdbc:hive2://centos-aaron-h1:10000> ;
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
| student_p.sno | student_p.sname | student_p.sex | student_p.sage | student_p.sdept | student_p.part |
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
| 1 | xiaowang | 男 | 18 | 教育部 | 2019-01-27 |
| 2 | xiaohei | 女 | 11 | 小学生 | 2019-01-27 |
| 3 | 大王 | 男 | 55 | 妖精 | 2019-01-27 |
| 4 | 黑子 | 女 | 22 | 美女 | 2019-01-27 |
| 11 | xiaodong | 男 | 12 | 教育部 | 2019-01-27 |
| 21 | xiaohei | 女 | 13 | 小学生 | 2019-01-27 |
| 31 | 大王吧 | 男 | 51 | 妖精 | 2019-01-27 |
| 41 | 黑子生 | 女 | 12 | 美女 | 2019-01-27 |
| 16 | xiaowangs | 男 | 38 | 教育部 | 2019-01-27 |
| 71 | xiaoheis | 女 | 31 | 小学生 | 2019-01-27 |
| 33 | 大王s | 男 | 35 | 妖精 | 2019-01-27 |
| 43 | 黑子s | 女 | 32 | 美女 | 2019-01-27 |
| 13 | xiaodongs | 男 | 32 | 教育部 | 2019-01-27 |
| 38 | xiaoheis | 女 | 33 | 小学生 | 2019-01-27 |
| 61 | 大王吧s | 男 | 31 | 妖精 | 2019-01-27 |
| 71 | 黑子生s | 女 | 32 | 美女 | 2019-01-27 |
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
16 rows selected (0.117 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> INSERT OVERWRITE TABLE student_p PARTITION (part='2019-01-24') select * FROM student_p where part='2019-01-26';
Error: Error while compiling statement: FAILED: SemanticException [Error 10044]: Line 1:23 Cannot insert into target table because column number/types are different ''2019-01-24'': Table insclause-0 has 5 columns, but query has 6 columns. (state=42000,code=10044)
0: jdbc:hive2://centos-aaron-h1:10000> INSERT OVERWRITE TABLE student_p PARTITION (part=2019-01-24) select * FROM student_p where part='2019-01-26';
Error: Error while compiling statement: FAILED: ParseException line 1:53 mismatched input '-' expecting ) near '2019' in destination specification (state=42000,code=40000)
0: jdbc:hive2://centos-aaron-h1:10000> INSERT OVERWRITE TABLE student_p PARTITION (part='2019-01-24') select * FROM student_p where part='2019-01-26';
Error: Error while compiling statement: FAILED: SemanticException [Error 10044]: Line 1:23 Cannot insert into target table because column number/types are different ''2019-01-24'': Table insclause-0 has 5 columns, but query has 6 columns. (state=42000,code=10044)
0: jdbc:hive2://centos-aaron-h1:10000> INSERT OVERWRITE TABLE student_p PARTITION (part='2019-01-24') select sno,sname.sex,sage,sdept FROM student_p where part='2019-01-26';
Error: Error while compiling statement: FAILED: SemanticException [Error 10042]: Line 1:74 . Operator is only supported on struct or list of struct types 'sex' (state=42000,code=10042)
0: jdbc:hive2://centos-aaron-h1:10000> INSERT OVERWRITE TABLE student_p PARTITION (part='2019-01-24') select sno,sname,sex,sage,sdept FROM student_p where part='2019-01-26';
INFO : Number of reduce tasks is set to 0 since there's no reduce operator
INFO : number of splits:1
INFO : Submitting tokens for job: job_1548292483386_0002
INFO : The url to track the job: http://centos-aaron-h1:8088/proxy/application_1548292483386_0002/
INFO : Starting Job = job_1548292483386_0002, Tracking URL = http://centos-aaron-h1:8088/proxy/application_1548292483386_0002/
INFO : Kill Command = /home/hadoop/apps/hadoop-2.9.1/bin/hadoop job -kill job_1548292483386_0002
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
INFO : 2019-01-25 03:10:27,371 Stage-1 map = 0%, reduce = 0%
INFO : 2019-01-25 03:11:13,554 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.93 sec
INFO : MapReduce Total cumulative CPU time: 1 seconds 930 msec
INFO : Ended Job = job_1548292483386_0002
INFO : Stage-4 is selected by condition resolver.
INFO : Stage-3 is filtered out by condition resolver.
INFO : Stage-5 is filtered out by condition resolver.
INFO : Moving data to: hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p/part=2019-01-24/.hive-staging_hive_2019-01-25_03-09-32_867_8637806880187945248-2/-ext-10000 from hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p/part=2019-01-24/.hive-staging_hive_2019-01-25_03-09-32_867_8637806880187945248-2/-ext-10002
INFO : Loading data to table default.student_p partition (part=2019-01-24) from hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p/part=2019-01-24/.hive-staging_hive_2019-01-25_03-09-32_867_8637806880187945248-2/-ext-10000
INFO : Partition default.student_p{part=2019-01-24} stats: [numFiles=1, numRows=0, totalSize=0, rawDataSize=0]
No rows affected (104.238 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> select * from student_p where part=‘2019-01-24’
0: jdbc:hive2://centos-aaron-h1:10000> ;
0: jdbc:hive2://centos-aaron-h1:10000> select * from student_p where part=‘2019-01-24’;
Error: Error while compiling statement: FAILED: ParseException line 1:35 character '‘' not supported here
line 1:46 character '’' not supported here
line 2:0 character ';' not supported here (state=42000,code=40000)
0: jdbc:hive2://centos-aaron-h1:10000> select * from student_p where part=‘2019-01-24’
0: jdbc:hive2://centos-aaron-h1:10000> ;
0: jdbc:hive2://centos-aaron-h1:10000> select * from student_p where part='2019-01-24'
0: jdbc:hive2://centos-aaron-h1:10000> ;
Error: Error while compiling statement: FAILED: ParseException line 1:35 character '‘' not supported here
line 1:46 character '’' not supported here
line 2:0 character ';' not supported here (state=42000,code=40000)
0: jdbc:hive2://centos-aaron-h1:10000> select * from student_p where part='2019-01-27';
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
| student_p.sno | student_p.sname | student_p.sex | student_p.sage | student_p.sdept | student_p.part |
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
| 1 | xiaowang | 男 | 18 | 教育部 | 2019-01-27 |
| 2 | xiaohei | 女 | 11 | 小学生 | 2019-01-27 |
| 3 | 大王 | 男 | 55 | 妖精 | 2019-01-27 |
| 4 | 黑子 | 女 | 22 | 美女 | 2019-01-27 |
| 11 | xiaodong | 男 | 12 | 教育部 | 2019-01-27 |
| 21 | xiaohei | 女 | 13 | 小学生 | 2019-01-27 |
| 31 | 大王吧 | 男 | 51 | 妖精 | 2019-01-27 |
| 41 | 黑子生 | 女 | 12 | 美女 | 2019-01-27 |
| 16 | xiaowangs | 男 | 38 | 教育部 | 2019-01-27 |
| 71 | xiaoheis | 女 | 31 | 小学生 | 2019-01-27 |
| 33 | 大王s | 男 | 35 | 妖精 | 2019-01-27 |
| 43 | 黑子s | 女 | 32 | 美女 | 2019-01-27 |
| 13 | xiaodongs | 男 | 32 | 教育部 | 2019-01-27 |
| 38 | xiaoheis | 女 | 33 | 小学生 | 2019-01-27 |
| 61 | 大王吧s | 男 | 31 | 妖精 | 2019-01-27 |
| 71 | 黑子生s | 女 | 32 | 美女 | 2019-01-27 |
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
16 rows selected (0.123 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> select * from student_p where part='2019-01-24';
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
| student_p.sno | student_p.sname | student_p.sex | student_p.sage | student_p.sdept | student_p.part |
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
+----------------+------------------+----------------+-----------------+------------------+-----------------+--+
No rows selected (0.106 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> INSERT OVERWRITE TABLE student_p PARTITION (part='2019-01-24') select sno,sname,sex,sage,sdept FROM student_p where part='2019-01-27';
INFO : Number of reduce tasks is set to 0 since there's no reduce operator
INFO : number of splits:1
INFO : Submitting tokens for job: job_1548292483386_0003
INFO : The url to track the job: http://centos-aaron-h1:8088/proxy/application_1548292483386_0003/
INFO : Starting Job = job_1548292483386_0003, Tracking URL = http://centos-aaron-h1:8088/proxy/application_1548292483386_0003/
INFO : Kill Command = /home/hadoop/apps/hadoop-2.9.1/bin/hadoop job -kill job_1548292483386_0003
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
INFO : 2019-01-25 03:16:41,867 Stage-1 map = 0%, reduce = 0%
INFO : 2019-01-25 03:16:55,323 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.97 sec
INFO : MapReduce Total cumulative CPU time: 970 msec
INFO : Ended Job = job_1548292483386_0003
INFO : Stage-4 is selected by condition resolver.
INFO : Stage-3 is filtered out by condition resolver.
INFO : Stage-5 is filtered out by condition resolver.
INFO : Moving data to: hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p/part=2019-01-24/.hive-staging_hive_2019-01-25_03-15-51_454_5937947928228224376-2/-ext-10000 from hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p/part=2019-01-24/.hive-staging_hive_2019-01-25_03-15-51_454_5937947928228224376-2/-ext-10002
INFO : Loading data to table default.student_p partition (part=2019-01-24) from hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p/part=2019-01-24/.hive-staging_hive_2019-01-25_03-15-51_454_5937947928228224376-2/-ext-10000
INFO : Partition default.student_p{part=2019-01-24} stats: [numFiles=1, numRows=16, totalSize=436, rawDataSize=420]
No rows affected (68.672 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> FROM student_p
0: jdbc:hive2://centos-aaron-h1:10000> INSERT OVERWRITE TABLE student_p PARTITION (part='2019-01-25')
0: jdbc:hive2://centos-aaron-h1:10000> select sno,sname,sex,sage,sdept where part='2019-01-27'
0: jdbc:hive2://centos-aaron-h1:10000> INSERT OVERWRITE TABLE student_p PARTITION (part='2019-01-26')
0: jdbc:hive2://centos-aaron-h1:10000> select sno,sname,sex,sage,sdept where part='2019-01-27';
INFO : Number of reduce tasks is set to 0 since there's no reduce operator
INFO : number of splits:1
INFO : Submitting tokens for job: job_1548292483386_0004
INFO : The url to track the job: http://centos-aaron-h1:8088/proxy/application_1548292483386_0004/
INFO : Starting Job = job_1548292483386_0004, Tracking URL = http://centos-aaron-h1:8088/proxy/application_1548292483386_0004/
INFO : Kill Command = /home/hadoop/apps/hadoop-2.9.1/bin/hadoop job -kill job_1548292483386_0004
INFO : Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 0
INFO : 2019-01-25 03:20:03,088 Stage-2 map = 0%, reduce = 0%
INFO : 2019-01-25 03:20:17,568 Stage-2 map = 100%, reduce = 0%, Cumulative CPU 0.86 sec
INFO : MapReduce Total cumulative CPU time: 860 msec
INFO : Ended Job = job_1548292483386_0004
INFO : Stage-5 is selected by condition resolver.
INFO : Stage-4 is filtered out by condition resolver.
INFO : Stage-6 is filtered out by condition resolver.
INFO : Stage-11 is selected by condition resolver.
INFO : Stage-10 is filtered out by condition resolver.
INFO : Stage-12 is filtered out by condition resolver.
INFO : Moving data to: hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p/part=2019-01-25/.hive-staging_hive_2019-01-25_03-19-45_569_112997067840560733-2/-ext-10000 from hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p/part=2019-01-25/.hive-staging_hive_2019-01-25_03-19-45_569_112997067840560733-2/-ext-10004
INFO : Moving data to: hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p/part=2019-01-26/.hive-staging_hive_2019-01-25_03-19-45_569_112997067840560733-2/-ext-10002 from hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p/part=2019-01-26/.hive-staging_hive_2019-01-25_03-19-45_569_112997067840560733-2/-ext-10005
INFO : Loading data to table default.student_p partition (part=2019-01-25) from hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p/part=2019-01-25/.hive-staging_hive_2019-01-25_03-19-45_569_112997067840560733-2/-ext-10000
INFO : Loading data to table default.student_p partition (part=2019-01-26) from hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p/part=2019-01-26/.hive-staging_hive_2019-01-25_03-19-45_569_112997067840560733-2/-ext-10002
INFO : Partition default.student_p{part=2019-01-25} stats: [numFiles=1, numRows=0, totalSize=436, rawDataSize=0]
INFO : Partition default.student_p{part=2019-01-26} stats: [numFiles=1, numRows=0, totalSize=436, rawDataSize=0]
No rows affected (35.095 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> create table student_p(sno int,sname string,sex string,sage int,sdept string)
0: jdbc:hive2://centos-aaron-h1:10000> partitioned by(part string)
0: jdbc:hive2://centos-aaron-h1:10000> select sno,sname,sex,sage,sdept where part='2019-01-27';[hadoop@centos-aaron-h1 bin]$ ./beeline -u jdbc:hive2://centos-aaron-h1:10000 -n hadoop
Connecting to jdbc:hive2://centos-aaron-h1:10000
Connected to: Apache Hive (version 1.2.2)
Driver: Hive JDBC (version 1.2.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 1.2.2 by Apache Hive
0: jdbc:hive2://centos-aaron-h1:10000> create table student_p1(sno int,sname string,sex string,sage int,sdept string)
0: jdbc:hive2://centos-aaron-h1:10000> partitioned by(part string)
0: jdbc:hive2://centos-aaron-h1:10000> row format delimited fields terminated by ',' stored as textfile;
No rows affected (3.826 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> INSERT OVERWRITE TABLE student_p1 PARTITION (part)
0: jdbc:hive2://centos-aaron-h1:10000> select sno,sname,sex,sage,sdept FROM student_p where part='2019-01-25';
Error: Error while compiling statement: FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict (state=42000,code=10096)
0: jdbc:hive2://centos-aaron-h1:10000> INSERT OVERWRITE TABLE student_p1 PARTITION (part)
0: jdbc:hive2://centos-aaron-h1:10000> select sno,sname,sex,sage,sdept,part FROM student_p where part='2019-01-25';
Error: Error while compiling statement: FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict (state=42000,code=10096)
0: jdbc:hive2://centos-aaron-h1:10000> set hive.exec.dynamic.partition.mode=nonstrict;
No rows affected (0.007 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> set hive.exec.dynamic.partition.mode=nonstrict;
No rows affected (0.001 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> INSERT OVERWRITE TABLE student_p1 PARTITION (part)
0: jdbc:hive2://centos-aaron-h1:10000> select sno,sname,sex,sage,sdept,part FROM student_p where part='2019-01-25';
INFO : Number of reduce tasks is set to 0 since there's no reduce operator
INFO : number of splits:1
INFO : Submitting tokens for job: job_1548292483386_0005
INFO : The url to track the job: http://centos-aaron-h1:8088/proxy/application_1548292483386_0005/
INFO : Starting Job = job_1548292483386_0005, Tracking URL = http://centos-aaron-h1:8088/proxy/application_1548292483386_0005/
INFO : Kill Command = /home/hadoop/apps/hadoop-2.9.1/bin/hadoop job -kill job_1548292483386_0005
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
INFO : 2019-01-25 03:31:04,951 Stage-1 map = 0%, reduce = 0%
INFO : 2019-01-25 03:31:13,101 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.85 sec
INFO : MapReduce Total cumulative CPU time: 850 msec
INFO : Ended Job = job_1548292483386_0005
INFO : Stage-4 is selected by condition resolver.
INFO : Stage-3 is filtered out by condition resolver.
INFO : Stage-5 is filtered out by condition resolver.
INFO : Moving data to: hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p1/.hive-staging_hive_2019-01-25_03-30-48_749_1916185387576728820-6/-ext-10000 from hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p1/.hive-staging_hive_2019-01-25_03-30-48_749_1916185387576728820-6/-ext-10002
INFO : Loading data to table default.student_p1 partition (part=null) from hdfs://centos-aaron-h1:9000/user/hive/warehouse/student_p1/.hive-staging_hive_2019-01-25_03-30-48_749_1916185387576728820-6/-ext-10000
INFO : Time taken for load dynamic partitions : 7270
INFO : Loading partition {part=2019-01-25}
INFO : Time taken for adding to write entity : 1
INFO : Partition default.student_p1{part=2019-01-25} stats: [numFiles=1, numRows=16, totalSize=436, rawDataSize=420]
No rows affected (33.148 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> INSERT OVERWRITE LOCAL DIRECTORY '/home/hadoop/student_download.txt' SELECT * from student_p;
INFO : Number of reduce tasks is set to 0 since there's no reduce operator
INFO : number of splits:1
INFO : Submitting tokens for job: job_1548292483386_0006
INFO : The url to track the job: http://centos-aaron-h1:8088/proxy/application_1548292483386_0006/
INFO : Starting Job = job_1548292483386_0006, Tracking URL = http://centos-aaron-h1:8088/proxy/application_1548292483386_0006/
INFO : Kill Command = /home/hadoop/apps/hadoop-2.9.1/bin/hadoop job -kill job_1548292483386_0006
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
INFO : 2019-01-25 03:39:38,322 Stage-1 map = 0%, reduce = 0%
INFO : 2019-01-25 03:39:59,388 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.78 sec
INFO : MapReduce Total cumulative CPU time: 4 seconds 780 msec
INFO : Ended Job = job_1548292483386_0006
INFO : Copying data to local directory /home/hadoop/student_download.txt from hdfs://centos-aaron-h1:9000/tmp/hive/hadoop/f9f86ec8-bbb2-4d63-b363-37f778911547/hive_2019-01-25_03-39-16_377_3873619375400733880-6/-mr-10000
INFO : Copying data to local directory /home/hadoop/student_download.txt from hdfs://centos-aaron-h1:9000/tmp/hive/hadoop/f9f86ec8-bbb2-4d63-b363-37f778911547/hive_2019-01-25_03-39-16_377_3873619375400733880-6/-mr-10000
No rows affected (45.227 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> cat /home/hadoop/student_download.txt
0: jdbc:hive2://centos-aaron-h1:10000> INSERT OVERWRITE DIRECTORY 'hdfs://centos-aaron-h1:9000/user/hive/warehouse/mystudent' SELECT * from student_p;
Error: Error while compiling statement: FAILED: ParseException line 1:0 cannot recognize input near 'cat' '/' 'home' (state=42000,code=40000)
0: jdbc:hive2://centos-aaron-h1:10000> INSERT OVERWRITE DIRECTORY 'hdfs://centos-aaron-h1:9000/he22' SELECT * from student_p;
INFO : Number of reduce tasks is set to 0 since there's no reduce operator
INFO : number of splits:1
INFO : Submitting tokens for job: job_1548292483386_0007
INFO : The url to track the job: http://centos-aaron-h1:8088/proxy/application_1548292483386_0007/
INFO : Starting Job = job_1548292483386_0007, Tracking URL = http://centos-aaron-h1:8088/proxy/application_1548292483386_0007/
INFO : Kill Command = /home/hadoop/apps/hadoop-2.9.1/bin/hadoop job -kill job_1548292483386_0007
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
INFO : 2019-01-25 03:48:29,273 Stage-1 map = 0%, reduce = 0%
INFO : 2019-01-25 03:48:55,659 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.2 sec
INFO : MapReduce Total cumulative CPU time: 1 seconds 200 msec
INFO : Ended Job = job_1548292483386_0007
INFO : Stage-3 is selected by condition resolver.
INFO : Stage-2 is filtered out by condition resolver.
INFO : Stage-4 is filtered out by condition resolver.
INFO : Moving data to: hdfs://centos-aaron-h1:9000/he22/.hive-staging_hive_2019-01-25_03-47-48_324_5948342718393546268-6/-ext-10000 from hdfs://centos-aaron-h1:9000/he22/.hive-staging_hive_2019-01-25_03-47-48_324_5948342718393546268-6/-ext-10002
INFO : Moving data to: hdfs://centos-aaron-h1:9000/he22 from hdfs://centos-aaron-h1:9000/he22/.hive-staging_hive_2019-01-25_03-47-48_324_5948342718393546268-6/-ext-10000
No rows affected (69.542 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> select sno,sname,sage from student_p where part='2019-01-27' order by sage desc limit 3;
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1548292483386_0008
INFO : The url to track the job: http://centos-aaron-h1:8088/proxy/application_1548292483386_0008/
INFO : Starting Job = job_1548292483386_0008, Tracking URL = http://centos-aaron-h1:8088/proxy/application_1548292483386_0008/
INFO : Kill Command = /home/hadoop/apps/hadoop-2.9.1/bin/hadoop job -kill job_1548292483386_0008
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2019-01-25 03:58:03,698 Stage-1 map = 0%, reduce = 0%
INFO : 2019-01-25 03:58:16,202 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.88 sec
INFO : 2019-01-25 03:58:35,159 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.82 sec
INFO : MapReduce Total cumulative CPU time: 3 seconds 820 msec
INFO : Ended Job = job_1548292483386_0008
+------+------------+-------+--+
| sno | sname | sage |
+------+------------+-------+--+
| 3 | 大王 | 55 |
| 31 | 大王吧 | 51 |
| 16 | xiaowangs | 38 |
+------+------------+-------+--+
3 rows selected (50.028 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> select sno,sname,sage from student_p sort by sage desc;
INFO : Number of reduce tasks not specified. Estimated from input data size: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1548292483386_0009
INFO : The url to track the job: http://centos-aaron-h1:8088/proxy/application_1548292483386_0009/
INFO : Starting Job = job_1548292483386_0009, Tracking URL = http://centos-aaron-h1:8088/proxy/application_1548292483386_0009/
INFO : Kill Command = /home/hadoop/apps/hadoop-2.9.1/bin/hadoop job -kill job_1548292483386_0009
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2019-01-25 04:03:03,156 Stage-1 map = 0%, reduce = 0%
INFO : 2019-01-25 04:03:18,739 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 6.18 sec
INFO : 2019-01-25 04:03:37,540 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 7.33 sec
INFO : MapReduce Total cumulative CPU time: 7 seconds 330 msec
INFO : Ended Job = job_1548292483386_0009
+------+------------+-------+--+
| sno | sname | sage |
+------+------------+-------+--+
| 3 | 大王 | 55 |
| 3 | 大王 | 55 |
| 3 | 大王 | 55 |
| 3 | 大王 | 55 |
| 31 | 大王吧 | 51 |
| 31 | 大王吧 | 51 |
| 31 | 大王吧 | 51 |
| 31 | 大王吧 | 51 |
| 16 | xiaowangs | 38 |
| 16 | xiaowangs | 38 |
| 16 | xiaowangs | 38 |
| 16 | xiaowangs | 38 |
| 33 | 大王s | 35 |
| 33 | 大王s | 35 |
| 33 | 大王s | 35 |
| 33 | 大王s | 35 |
| 38 | xiaoheis | 33 |
| 38 | xiaoheis | 33 |
| 38 | xiaoheis | 33 |
| 38 | xiaoheis | 33 |
| 71 | 黑子生s | 32 |
| 13 | xiaodongs | 32 |
| 43 | 黑子s | 32 |
| 71 | 黑子生s | 32 |
| 13 | xiaodongs | 32 |
| 43 | 黑子s | 32 |
| 71 | 黑子生s | 32 |
| 13 | xiaodongs | 32 |
| 43 | 黑子s | 32 |
| 71 | 黑子生s | 32 |
| 13 | xiaodongs | 32 |
| 43 | 黑子s | 32 |
| 71 | xiaoheis | 31 |
| 61 | 大王吧s | 31 |
| 71 | xiaoheis | 31 |
| 61 | 大王吧s | 31 |
| 71 | xiaoheis | 31 |
| 71 | xiaoheis | 31 |
| 61 | 大王吧s | 31 |
| 61 | 大王吧s | 31 |
| 4 | 黑子 | 22 |
| 4 | 黑子 | 22 |
| 4 | 黑子 | 22 |
| 4 | 黑子 | 22 |
| 1 | xiaowang | 18 |
| 1 | xiaowang | 18 |
| 1 | xiaowang | 18 |
| 1 | xiaowang | 18 |
| 21 | xiaohei | 13 |
| 21 | xiaohei | 13 |
| 21 | xiaohei | 13 |
| 21 | xiaohei | 13 |
| 11 | xiaodong | 12 |
| 11 | xiaodong | 12 |
| 41 | 黑子生 | 12 |
| 41 | 黑子生 | 12 |
| 41 | 黑子生 | 12 |
| 11 | xiaodong | 12 |
| 11 | xiaodong | 12 |
| 41 | 黑子生 | 12 |
| 2 | xiaohei | 11 |
| 2 | xiaohei | 11 |
| 2 | xiaohei | 11 |
| 2 | xiaohei | 11 |
+------+------------+-------+--+
64 rows selected (58.251 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> select sno,sname,sage from student_p distribute by sage desc;
Error: Error while compiling statement: FAILED: ParseException line 1:56 extraneous input 'desc' expecting EOF near '<EOF>' (state=42000,code=40000)
0: jdbc:hive2://centos-aaron-h1:10000> select sno,sname,sage from student_p distribute by sage ;
0: jdbc:hive2://centos-aaron-h1:10000> select sno,sname,sage from student_p distribute by sage ;
Error: Error while compiling statement: FAILED: ParseException line 1:56 character ';' not supported here (state=42000,code=40000)
0: jdbc:hive2://centos-aaron-h1:10000> select sno,sname,sage from student_p distribute by sage;
INFO : Number of reduce tasks not specified. Estimated from input data size: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1548292483386_0010
INFO : The url to track the job: http://centos-aaron-h1:8088/proxy/application_1548292483386_0010/
INFO : Starting Job = job_1548292483386_0010, Tracking URL = http://centos-aaron-h1:8088/proxy/application_1548292483386_0010/
INFO : Kill Command = /home/hadoop/apps/hadoop-2.9.1/bin/hadoop job -kill job_1548292483386_0010
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2019-01-25 04:07:37,735 Stage-1 map = 0%, reduce = 0%
INFO : 2019-01-25 04:07:49,308 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.08 sec
INFO : 2019-01-25 04:07:56,511 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.04 sec
INFO : MapReduce Total cumulative CPU time: 4 seconds 40 msec
INFO : Ended Job = job_1548292483386_0010
+------+------------+-------+--+
| sno | sname | sage |
+------+------------+-------+--+
| 71 | 黑子生s | 32 |
| 61 | 大王吧s | 31 |
| 38 | xiaoheis | 33 |
| 13 | xiaodongs | 32 |
| 43 | 黑子s | 32 |
| 33 | 大王s | 35 |
| 71 | xiaoheis | 31 |
| 16 | xiaowangs | 38 |
| 41 | 黑子生 | 12 |
| 31 | 大王吧 | 51 |
| 21 | xiaohei | 13 |
| 11 | xiaodong | 12 |
| 4 | 黑子 | 22 |
| 3 | 大王 | 55 |
| 2 | xiaohei | 11 |
| 1 | xiaowang | 18 |
| 71 | 黑子生s | 32 |
| 61 | 大王吧s | 31 |
| 38 | xiaoheis | 33 |
| 13 | xiaodongs | 32 |
| 43 | 黑子s | 32 |
| 33 | 大王s | 35 |
| 71 | xiaoheis | 31 |
| 16 | xiaowangs | 38 |
| 41 | 黑子生 | 12 |
| 31 | 大王吧 | 51 |
| 21 | xiaohei | 13 |
| 11 | xiaodong | 12 |
| 4 | 黑子 | 22 |
| 3 | 大王 | 55 |
| 2 | xiaohei | 11 |
| 1 | xiaowang | 18 |
| 71 | 黑子生s | 32 |
| 61 | 大王吧s | 31 |
| 38 | xiaoheis | 33 |
| 13 | xiaodongs | 32 |
| 43 | 黑子s | 32 |
| 33 | 大王s | 35 |
| 71 | xiaoheis | 31 |
| 16 | xiaowangs | 38 |
| 41 | 黑子生 | 12 |
| 31 | 大王吧 | 51 |
| 21 | xiaohei | 13 |
| 11 | xiaodong | 12 |
| 4 | 黑子 | 22 |
| 3 | 大王 | 55 |
| 2 | xiaohei | 11 |
| 1 | xiaowang | 18 |
| 71 | 黑子生s | 32 |
| 61 | 大王吧s | 31 |
| 38 | xiaoheis | 33 |
| 13 | xiaodongs | 32 |
| 43 | 黑子s | 32 |
| 33 | 大王s | 35 |
| 71 | xiaoheis | 31 |
| 16 | xiaowangs | 38 |
| 41 | 黑子生 | 12 |
| 31 | 大王吧 | 51 |
| 21 | xiaohei | 13 |
| 11 | xiaodong | 12 |
| 4 | 黑子 | 22 |
| 3 | 大王 | 55 |
| 2 | xiaohei | 11 |
| 1 | xiaowang | 18 |
+------+------------+-------+--+
64 rows selected (34.781 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> select sname,sum(sage) from student_p group by sage;
Error: Error while compiling statement: FAILED: SemanticException [Error 10025]: Line 1:7 Expression not in GROUP BY key 'sname' (state=42000,code=10025)
0: jdbc:hive2://centos-aaron-h1:10000> select sname,sum(sage) from student_p group by sname;
INFO : Number of reduce tasks not specified. Estimated from input data size: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1548292483386_0011
INFO : The url to track the job: http://centos-aaron-h1:8088/proxy/application_1548292483386_0011/
INFO : Starting Job = job_1548292483386_0011, Tracking URL = http://centos-aaron-h1:8088/proxy/application_1548292483386_0011/
INFO : Kill Command = /home/hadoop/apps/hadoop-2.9.1/bin/hadoop job -kill job_1548292483386_0011
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2019-01-25 04:10:01,662 Stage-1 map = 0%, reduce = 0%
INFO : 2019-01-25 04:10:13,029 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.91 sec
INFO : 2019-01-25 04:10:19,227 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.88 sec
INFO : MapReduce Total cumulative CPU time: 4 seconds 880 msec
INFO : Ended Job = job_1548292483386_0011
+------------+------+--+
| sname | _c1 |
+------------+------+--+
| xiaodong | 48 |
| xiaodongs | 128 |
| xiaohei | 96 |
| xiaoheis | 256 |
| xiaowang | 72 |
| xiaowangs | 152 |
| 大王 | 220 |
| 大王s | 140 |
| 大王吧 | 204 |
| 大王吧s | 124 |
| 黑子 | 88 |
| 黑子s | 128 |
| 黑子生 | 48 |
| 黑子生s | 128 |
+------------+------+--+
14 rows selected (35.073 seconds)
0: jdbc:hive2://centos-aaron-h1:10000> [hadoop@centos-aaron-h1 bin]$















 2870
2870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









