







自己业余时间的一个扩展,考虑的方面不是特别全。有不妥之处还望指正。
import urllib
import urllib2
import thread
import re
class image:
def forwith(self):
aa = "561f1596c91ec6653b46a4b5,58de30eabd9238345d210574,5625d95014dfb21d8b20417f"
number = 1
for texts in aa.split(","):
print number
self.save(texts,number)
number += 1
def save(self,code,number):
request = urllib2.Request("https://www.wish.com/c/"+code)
try:
response = urllib2.urlopen(request)
content = response.read().decode('utf-8')
image = re.compile('<meta property="og:image" content="(.*?)" />', re.S)
images = re.findall(image, content)
if images is None:
print code
elif len(images) < 1:
print code
else:
print images[0]
u = urllib.urlopen(images[0])
data = u.read()
f = open(code + '.jpg', 'wb')
f.write(data)
f.close()
except urllib2.URLError, e:
print code
image1 = image()
image1.forwith()
结果
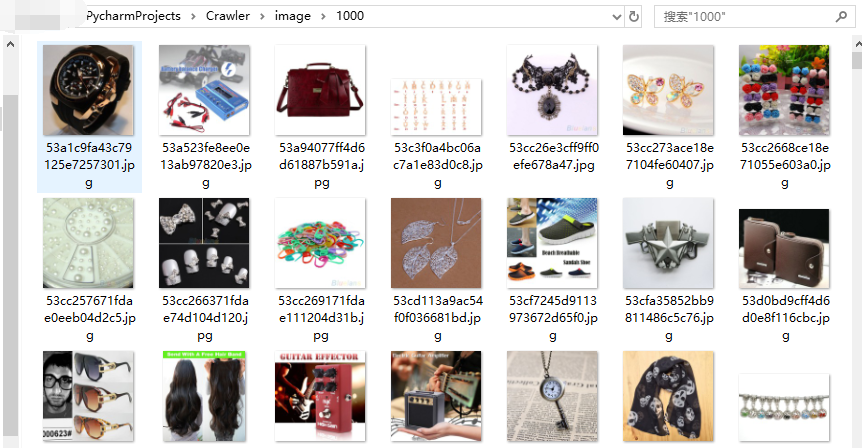















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









