






学习Python也有一段时间了,各种理论知识大体上也算略知一二了,今天就进入实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫。
第一步:分析网站的请求过程
我们在查看拉勾网上的招聘信息的时候,搜索Python,或者是PHP等等的岗位信息,其实是向服务器发出相应请求,由服务器动态的响应请求,将我们所需要的内容通过浏览器解析,呈现在我们的面前。

可以看到我们发出的请求当中,FormData中的kd参数,就代表着向服务器请求关键词为Python的招聘信息。
分析比较复杂的页面请求与响应信息,推荐使用Fiddler,对于分析网站来说绝对是一大杀器。不过比较简单的响应请求用浏览器自带的开发者工具就可以,比如像火狐的FireBug等等,只要轻轻一按F12,所有的请求的信息都会事无巨细的展现在你面前。
经由分析网站的请求与响应过程可知,拉勾网的招聘信息都是由XHR动态传递的。

我们发现,以POST方式发出的请求有两个,分别是companyAjax.json和positionAjax.json,它们分别控制当前显示的页面和页面中包含的招聘信息。
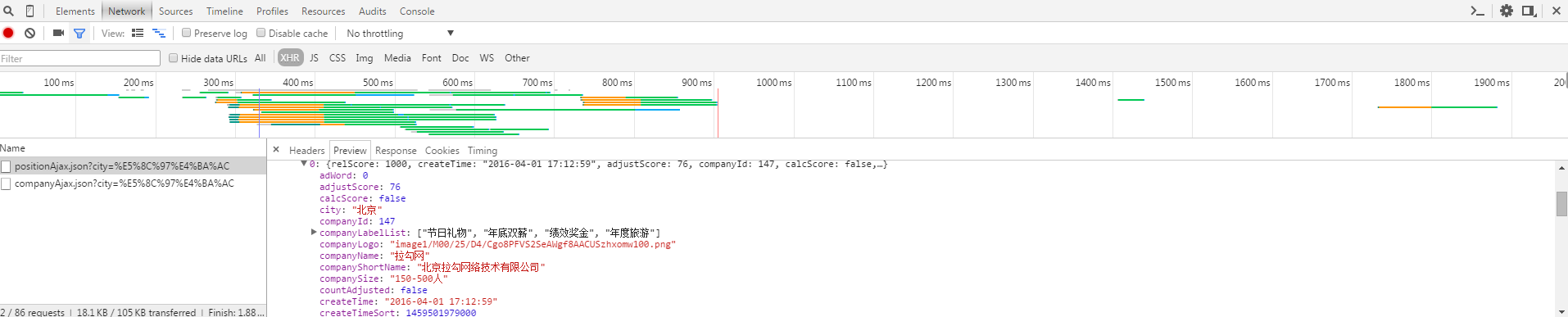
可以看到,我们所需要的信息包含在positionAjax.json的Content->result当中,其中还包含了一些其他参数信息,包括总页面数(totalPageCount),总招聘登记数(totalCount)等相关信息。
第二步:发送请求,获取页面
知道我们所要抓取的信息在哪里是最为首要的,知道信息位置之后,接下来我们就要考虑如何通过Python来模拟浏览器,获取这些我们所需要的信息。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
def read_page(url, page_num, keyword): |
其中比较关键的步骤在于如何仿照浏览器的Post方式,来包装我们自己的请求。
request包含的参数包括所要抓取的网页url,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
包装完毕之后,就可以像浏览器一样访问拉勾网,并获得页面数据了。
第三步:各取所需,获取数据
获得页面信息之后,我们就可以开始爬虫数据中最主要的步骤:抓取数据。
抓取数据的方式有很多,像正则表达式re,lxml的etree,json,以及bs4的BeautifulSoup都是python3抓取数据的适用方法。大家可以根据实际情况,使用其中一个,又或多个结合使用。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
def read_tag(page, tag): |
第四步:将所抓取的信息存储到excel中
获得原始数据之后,为了进一步的整理与分析,我们有结构有组织的将抓取到的数据存储到excel中,方便进行数据的可视化处理。
这里我用了两个不同的框架,分别是老牌的xlwt.Workbook、以及xlsxwriter。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
def save_excel(fin_result, tag_name, file_name): book.save_excel(r'C:\Users\Administrator\Desktop\%s.xls'%file_name) |
到从为止,一个抓取拉勾网招聘信息的小爬虫就诞生了。
附上源码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
|
#! -*-coding:utf-8 -*- max_page_num = 30 tag_pos = 'A%s' % i |














 1692
1692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









