






特别说明:
在上一遍文章中有详细的叙述Receiver启动的过程,如果不清楚的朋友,请您查看上一篇博客,这里我们就基于上篇的结论,继续往下说。
博文的目标是:
Spark Streaming在接收数据的全生命周期贯通
组织思路如下:
a) 接收数据的架构模式的设计
b) 然后再具体源码分析
接收数据的架构模式的设计
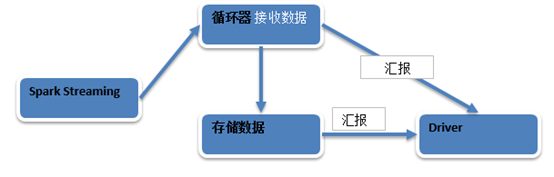
1. 当有Spark Streaming有application的时候Spark Streaming会持续不断的接收数据。
2. 一般Receiver和Driver不在一个进程中的,所以接收到数据之后要不断的汇报给Driver。
3. Spark Streaming要接收数据肯定要使用消息循环器,循环器不断的接收到数据之后,然后将数据存储起来,再将存储完的数据汇报给Driver。
4. Spark Streaming数据接收的过程也是MVC的架构,M是model也就是Receiver.
C是Control也就是存储级别的ReceiverSupervisor。V是界面。
5. ReceiverSupervisor是控制器,Receiver的启动是靠ReceiverTracker启动的,Receiver接收到数据之后是靠ReceiverSupervisor存储数据的。然后Driver就获得元数据也就是界面,通过界面来操作底层的数据,这个元数据就相当于指针。
Spark Streaming接收数据流程如下:
具体源码分析
1. ReceiverTracker通过发送Job的方式,并且每个Job只有一个Task,并且Task中只通过一个ReceiverSupervisor启动一个Receiver.
2. 下图就是Receiver启动的流程图,现在就从ReceiverTracker的start开始今天的旅程。 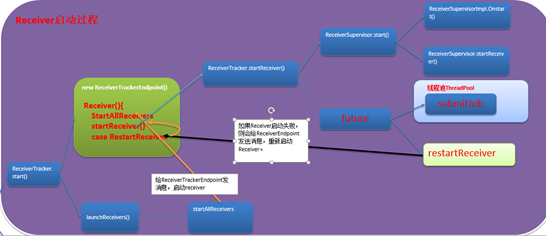
3. Start方法中创建Endpoint实例
/** Start the endpoint and receiver execution thread. */def start(): Unit = synchronized { if (isTrackerStarted) { throw new SparkException("ReceiverTracker already started")
} if (!receiverInputStreams.isEmpty) {
endpoint = ssc.env.rpcEnv.setupEndpoint( "ReceiverTracker", new ReceiverTrackerEndpoint(ssc.env.rpcEnv)) if (!skipReceiverLaunch) launchReceivers()
logInfo("ReceiverTracker started")
trackerState = Started
}
}
4. LaunchReceivers源码如下:
/**
* Get the receivers from the ReceiverInputDStreams, distributes them to the
* worker nodes as a parallel collection, and runs them.
*/
private def launchReceivers(): Unit = {
val receivers = receiverInputStreams.map(nis => {
val rcvr = nis.getReceiver()
rcvr.setReceiverId(nis.id)
rcvr
})
runDummySparkJob()
logInfo("Starting " + receivers.length + " receivers")
//此时的endpoint就是前面实例化的ReceiverTrackerEndpoint
endpoint.send(StartAllReceivers(receivers))
}
5. 从图上可以知道,send发送消息之后,ReceiverTrackerEndpoint的receive就接收到了消息。
override def receive: PartialFunction[Any, Unit] = {
// Local messages
case StartAllReceivers(receivers) =>
val scheduledLocations = schedulingPolicy.scheduleReceivers(receivers, getExecutors) for (receiver <- receivers) {
val executors = scheduledLocations(receiver.streamId)
updateReceiverScheduledExecutors(receiver.streamId, executors)
receiverPreferredLocations(receiver.streamId) = receiver.preferredLocation
startReceiver(receiver, executors)
}
6. startReceiver源码如下:
/**
* Start a receiver along with its scheduled executors
*/private def startReceiver(
receiver: Receiver[_],
scheduledLocations: Seq[TaskLocation]): Unit = { def shouldStartReceiver: Boolean = { // It's okay to start when trackerState is Initialized or Started
!(isTrackerStopping || isTrackerStopped)
} val receiverId = receiver.streamId if (!shouldStartReceiver) {
onReceiverJobFinish(receiverId) return
} val checkpointDirOption = Option(ssc.checkpointDir) val serializableHadoopConf = new SerializableConfiguration(ssc.sparkContext.hadoopConfiguration)// startReceiverFunc就是我们通过RDD启动Job的那个Func
// Function to start the receiver on the worker node//此时虽然是iterator但是就是一个Receiver,因为你如果追溯一下前面StartReceiver被调用的时候是for循环遍历Receivers.
val startReceiverFunc: Iterator[Receiver[_]] => Unit =
(iterator: Iterator[Receiver[_]]) => { if (!iterator.hasNext) { throw new SparkException( "Could not start receiver as object not found.")
} if (TaskContext.get().attemptNumber() == 0) { val receiver = iterator.next()
assert(iterator.hasNext == false)//此时的receiver是根据数据输入来源创建的InputDStream//例如socketInputDStream他有自己的receiver也就是SocketReceiver//此时receiver就相当于一个引用句柄。他只是引用的描述
val supervisor = new ReceiverSupervisorImpl(
receiver, SparkEnv.get, serializableHadoopConf.value, checkpointDirOption)//当startReceiverFunc被调用的时候ReceiverSupervisorImpl的start方法就会运行。
supervisor.start()
supervisor.awaitTermination()
} else { // It's restarted by TaskScheduler, but we want to reschedule it again. So exit it.
}
} // Create the RDD using the scheduledLocations to run the receiver in a Spark job
val receiverRDD: RDD[Receiver[_]] = if (scheduledLocations.isEmpty) {//此时Seq(receiver)中只有一个Receiver
ssc.sc.makeRDD(Seq(receiver), 1)
} else { val preferredLocations = scheduledLocations.map(_.toString).distinct
ssc.sc.makeRDD(Seq(receiver -> preferredLocations))
}//专门为了创建receiver而创建的RDD
receiverRDD.setName(s"Receiver $receiverId")
ssc.sparkContext.setJobDescription(s"Streaming job running receiver $receiverId")
ssc.sparkContext.setCallSite(Option(ssc.getStartSite()).getOrElse(Utils.getCallSite())) val future = ssc.sparkContext.submitJob[Receiver[_], Unit, Unit](
receiverRDD, startReceiverFunc, Seq(0), (_, _) => Unit, ()) // We will keep restarting the receiver job until ReceiverTracker is stopped
future.onComplete { case Success(_) => if (!shouldStartReceiver) {
onReceiverJobFinish(receiverId)
} else {
logInfo(s"Restarting Receiver $receiverId")
self.send(RestartReceiver(receiver))
} case Failure(e) => if (!shouldStartReceiver) {
onReceiverJobFinish(receiverId)
} else {
logError("Receiver has been stopped. Try to restart it.", e)
logInfo(s"Restarting Receiver $receiverId")
self.send(RestartReceiver(receiver))
}
}(submitJobThreadPool)
logInfo(s"Receiver ${receiver.streamId} started")
}
6. startReceiver源码如下:
/**
* Start a receiver along with its scheduled executors
*/private def startReceiver(
receiver: Receiver[_],
scheduledLocations: Seq[TaskLocation]): Unit = { def shouldStartReceiver: Boolean = { // It's okay to start when trackerState is Initialized or Started
!(isTrackerStopping || isTrackerStopped)
} val receiverId = receiver.streamId if (!shouldStartReceiver) {
onReceiverJobFinish(receiverId) return
} val checkpointDirOption = Option(ssc.checkpointDir) val serializableHadoopConf = new SerializableConfiguration(ssc.sparkContext.hadoopConfiguration)// startReceiverFunc就是我们通过RDD启动Job的那个Func
// Function to start the receiver on the worker node//此时虽然是iterator但是就是一个Receiver,因为你如果追溯一下前面StartReceiver被调用的时候是for循环遍历Receivers.
val startReceiverFunc: Iterator[Receiver[_]] => Unit =
(iterator: Iterator[Receiver[_]]) => { if (!iterator.hasNext) { throw new SparkException( "Could not start receiver as object not found.")
} if (TaskContext.get().attemptNumber() == 0) { val receiver = iterator.next()
assert(iterator.hasNext == false)//此时的receiver是根据数据输入来源创建的InputDStream//例如socketInputDStream他有自己的receiver也就是SocketReceiver//此时receiver就相当于一个引用句柄。他只是引用的描述
val supervisor = new ReceiverSupervisorImpl(
receiver, SparkEnv.get, serializableHadoopConf.value, checkpointDirOption)//当startReceiverFunc被调用的时候ReceiverSupervisorImpl的start方法就会运行。
supervisor.start()
supervisor.awaitTermination()
} else { // It's restarted by TaskScheduler, but we want to reschedule it again. So exit it.
}
} // Create the RDD using the scheduledLocations to run the receiver in a Spark job
val receiverRDD: RDD[Receiver[_]] = if (scheduledLocations.isEmpty) {//此时Seq(receiver)中只有一个Receiver
ssc.sc.makeRDD(Seq(receiver), 1)
} else { val preferredLocations = scheduledLocations.map(_.toString).distinct
ssc.sc.makeRDD(Seq(receiver -> preferredLocations))
}//专门为了创建receiver而创建的RDD
receiverRDD.setName(s"Receiver $receiverId")
ssc.sparkContext.setJobDescription(s"Streaming job running receiver $receiverId")
ssc.sparkContext.setCallSite(Option(ssc.getStartSite()).getOrElse(Utils.getCallSite())) val future = ssc.sparkContext.submitJob[Receiver[_], Unit, Unit](
receiverRDD, startReceiverFunc, Seq(0), (_, _) => Unit, ()) // We will keep restarting the receiver job until ReceiverTracker is stopped
future.onComplete { case Success(_) => if (!shouldStartReceiver) {
onReceiverJobFinish(receiverId)
} else {
logInfo(s"Restarting Receiver $receiverId")
self.send(RestartReceiver(receiver))
} case Failure(e) => if (!shouldStartReceiver) {
onReceiverJobFinish(receiverId)
} else {
logError("Receiver has been stopped. Try to restart it.", e)
logInfo(s"Restarting Receiver $receiverId")
self.send(RestartReceiver(receiver))
}
}(submitJobThreadPool)
logInfo(s"Receiver ${receiver.streamId} started")
}
7. 现在就追踪一下receiver参数的传递过程。先找到startReceiver在哪里调用。
override def receive: PartialFunction[Any, Unit] = {
// Local messages
case StartAllReceivers(receivers) =>
val scheduledLocations = schedulingPolicy.scheduleReceivers(receivers, getExecutors) for (receiver <- receivers) {
val executors = scheduledLocations(receiver.streamId)
updateReceiverScheduledExecutors(receiver.streamId, executors)
receiverPreferredLocations(receiver.streamId) = receiver.preferredLocation
startReceiver(receiver, executors)
}
8. 可以看出receiver是StartAllReceivers方法传入的,继续追踪StartAllReceivers。 通过getReceiver就获得了receiver的对象。
/**
* Get the receivers from the ReceiverInputDStreams, distributes them to the
* worker nodes as a parallel collection, and runs them.
*/
private def launchReceivers(): Unit = {
val receivers = receiverInputStreams.map(nis => {
val rcvr = nis.getReceiver()
rcvr.setReceiverId(nis.id)
rcvr
})
runDummySparkJob()
logInfo("Starting " + receivers.length + " receivers")
endpoint.send(StartAllReceivers(receivers))
}
submitJob的时候就提交了作业,在具体的节点上运行Job,此时是通过ReceiverSupervisorImpl完成的。
此时在ReceiverTracker的startReceiver调用的时候完成了两件事:
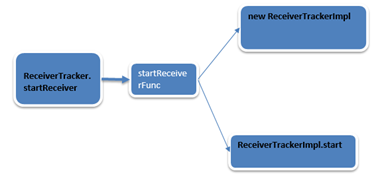
ReceiverTrackerImpl的初始化和start方法的调用。
第一步:ReceiverTrackerImpl的初始化
1. ReceiverSupervisor负责接收receiver接收的数据,之后,ReceiverSupervisor会存储数据,然后汇报给Driver。Receiver是一条一条的接收数据(Kafka是 Key Value的形式)。
/** * Concrete implementation of `org`.`apache`.`spark`.`streaming`.`receiver`.`ReceiverSupervisor` * which provides all the necessary functionality for handling the data received by * the receiver. Specifically, it creates a `org`.`apache`.`spark`.`streaming`.`receiver`.`BlockGenerator` * object that is used to divide the received data stream into blocks of data. */ private[streaming] class ReceiverSupervisorImpl(
2. ReceiverSupervisorImpl初始化源码如下:
/** Remote RpcEndpointRef for the ReceiverTracker *///负责链接ReceiverTracker的消息通信体private val trackerEndpoint = RpcUtils.makeDriverRef("ReceiverTracker", env.conf, env.rpcEnv)/** RpcEndpointRef for receiving messages from the ReceiverTracker in the driver *///endpoint负责在Driver端接收ReceiverTracker发送来的消息。private val endpoint = env.rpcEnv.setupEndpoint( "Receiver-" + streamId + "-" + System.currentTimeMillis(), new ThreadSafeRpcEndpoint { override val rpcEnv: RpcEnv = env.rpcEnv override def receive: PartialFunction[Any, Unit] = { case StopReceiver =>
logInfo("Received stop signal")
ReceiverSupervisorImpl.this.stop("Stopped by driver", None)//每个Batch处理完数据之后,Driver的ReceiverTracker会发消息给ReceiverTrackerImpl要求清理Block信息。
case CleanupOldBlocks(threshTime) =>
logDebug("Received delete old batch signal")
cleanupOldBlocks(threshTime)//限制receiver接收数据的,也就是限流的。这样的话就可以动态的改变receiver//的数据接收速度。
case UpdateRateLimit(eps) =>
logInfo(s"Received a new rate limit: $eps.")
registeredBlockGenerators.foreach { bg =>
bg.updateRate(eps)
}
}
})
cleanupOldBlocks源码如下:
private def cleanupOldBlocks(cleanupThreshTime: Time): Unit = {
logDebug(s"Cleaning up blocks older then $cleanupThreshTime")
receivedBlockHandler.cleanupOldBlocks(cleanupThreshTime.milliseconds)
}
}
3. 从对象中获得限流的速度,这对于实际生产环境非常重要,因为有时间数据请求量非常的多,整个集群又处理不完或者来不及处理,这个时候如果不限流的话,延迟就非常的高。
/**
* Set the rate limit to `newRate`. The new rate will not exceed the maximum rate configured by
* {`spark`.`streaming`.`receiver`.`maxRate`}, even if `newRate` is higher than that.
*
* @param newRate A new rate in events per second. It has no effect if it's 0 or negative.
*/
private[receiver] def updateRate(newRate: Long): Unit = if (newRate > 0) { if (maxRateLimit > 0) {
rateLimiter.setRate(newRate.min(maxRateLimit))
} else {
rateLimiter.setRate(newRate)
}
}
}
至此上面就完成了ReceiverSupervisorImpl的初始化。这里只是简单的提了一些,后面还会详解
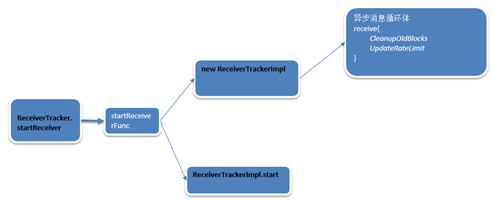
第二步:ReceiverTrackerImpl的start方法被调用。
在ReceiverTrackerImpl的函数中,并没有start方法,这个时候的实现是在其父类start方法中实现的。
4. 在supervisor启动的时候会调用ReceiverSupervisor的start方法
/** Start the supervisor */def start() {
onStart()
startReceiver()
}
5. onstart方法: 此方法必须在receiver.onStart()之前被调用,来确保BlockGenerator被实例化和启动。Receiver在接收数据的时候是通过BlockGenerator转换成Block形式,因为Receiver一条一条的接收数据,需要将此数据合并成Block,RDD的处理单位是Block。
/**
* Called when supervisor is started.
* Note that this must be called before the receiver.onStart() is called to ensure
* things like `BlockGenerator`s are started before the receiver starts sending data.
*/protected def onStart() { }
6. onStart方法具体实现是在RceiverSupervisorImpl方法中实现的。
override protected def onStart() {
registeredBlockGenerators.foreach { _.start() }
}
什么是BlockGenerator?
将接收到的数据以Batch的方式存在,并且以特定的频率存储。
BlockGenerator会启动两条线程:
1. 一条线程会周期性的把Receiver接收到的数据合并成Block。
2. 另一条线程是把接收到的数据使用BlockManager存储。
BlockGenerator继承自RateLimiter,由此可以看出无法限定流熟度,但是可以限定存储的速度,转过来限制流进来的速度。
/**
* Generates batches of objects received by a
* `org`.`apache`.`spark`.`streaming`.`receiver`.`Receiver` and puts them into appropriately
* named blocks at regular intervals. This class starts two threads,
* one to periodically start a new batch and prepare the previous batch of as a block,
* the other to push the blocks into the block manager.
*
* Note: Do not create BlockGenerator instances directly inside receivers. Use
* `ReceiverSupervisor.createBlockGenerator` to create a BlockGenerator and use it.
*/
private[streaming] class BlockGenerator(
listener: BlockGeneratorListener,
receiverId: Int,
conf: SparkConf,
clock: Clock = new SystemClock()
) extends RateLimiter(conf) with Logging {
BlockGenerator是怎么产生的?
7. 在ReceiverSupervisorImpl的createBlockGenerator方法中实现了BlockGenerator的创建。
override def createBlockGenerator(
blockGeneratorListener: BlockGeneratorListener): BlockGenerator = {
// Cleanup BlockGenerators that have already been stopped
registeredBlockGenerators --= registeredBlockGenerators.filter{ _.isStopped() }
//一个streamId指服务于一个BlockGenerator
val newBlockGenerator = new BlockGenerator(blockGeneratorListener, streamId, env.conf)
registeredBlockGenerators += newBlockGenerator
newBlockGenerator
}
8. 回到上面ReceiverTrackerImpl的onStart方法
override protected def onStart() {//启动BlockGenerator的定时器不断的把数据放在内存中的Buffer中然后将多条Buffer合并成Block,此时只是准备去接收Receiver的数据
registeredBlockGenerators.foreach { _.start() }
}
9. BlockGenerator的start方法启动了BlockGenerator的两条线程。
/** Start block generating and pushing threads. */def start(): Unit = synchronized { if (state == Initialized) {
state = Active
blockIntervalTimer.start()
blockPushingThread.start()
logInfo("Started BlockGenerator")
} else { throw new SparkException(
s"Cannot start BlockGenerator as its not in the Initialized state [state = $state]")
}
}
blockIntervalTimer是RecurringTimer实例。
private val blockIntervalTimer = new RecurringTimer(clock, blockIntervalMs, updateCurrentBuffer, "BlockGenerator")
11. blockIntervalTimer的start方法。
/**
* Start at the earliest time it can start based on the period.
*/def start(): Long = {
start(getStartTime())
}
12. 启动线程
/**
* Start at the given start time.
*/def start(startTime: Long): Long = synchronized {
nextTime = startTime
thread.start()
logInfo("Started timer for " + name + " at time " + nextTime)
nextTime
}
13. Tread启动loop.
private val thread = new Thread("RecurringTimer - " + name) {
setDaemon(true) override def run() { loop }
}
14. Loop也就会调用triggerActionForNextInterval()
/**
* Repeatedly call the callback every interval.
*/
private def loop() { try { while (!stopped) {
triggerActionForNextInterval()
}
triggerActionForNextInterval()
} catch { case e: InterruptedException =>
}
}
}
}
15. 此时callback函数就会回调updateCurrentBuffer方法。
private def triggerActionForNextInterval(): Unit = {
clock.waitTillTime(nextTime)
callback(nextTime)
prevTime = nextTime
nextTime += period
logDebug("Callback for " + name + " called at time " + prevTime)
}
16. 在RecurringTimer实例创建的时候,第三个参数传入的就是updateCurrentBuffer方法。
private[streaming]class RecurringTimer(clock: Clock, period: Long, callback: (Long) => Unit, name: String)
extends Logging {
17. 把接收到的数据放入到Buffer缓存中,然后再把Buffer按照一定的大小合并成Block.
/** Change the buffer to which single records are added to. */private def updateCurrentBuffer(time: Long): Unit = { try { var newBlock: Block = null
synchronized { if (currentBuffer.nonEmpty) { val newBlockBuffer = currentBuffer
= new ArrayBuffer[Any] val blockId = StreamBlockId(receiverId, time - blockIntervalMs)
listener.onGenerateBlock(blockId)
newBlock = new Block(blockId, newBlockBuffer)
}
} if (newBlock != null) {//将生成成功的Block放入到队列中
blocksForPushing.put(newBlock) // put is blocking when queue is full
}
} catch { case ie: InterruptedException =>
logInfo("Block updating timer thread was interrupted") case e: Exception =>
reportError("Error in block updating thread", e)
}
}
BlockGenerator的start启动就分析完了,至此准备好接收Receiver数据了。
BlockGenerator的start启动过程如下: 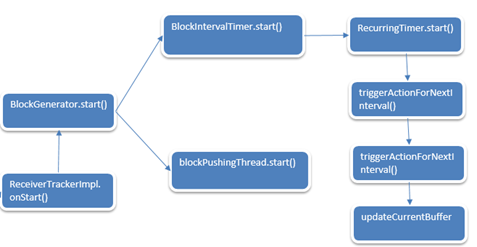
至此ReceiverTrackerImpl的onStart就介绍完了。
18. 回到ReceiverSupervisor的start方法。
/** Start the supervisor */def start() {
onStart()
startReceiver()
}
19. 启动receiver
** Start receiver */def startReceiver(): Unit = synchronized { try { if (onReceiverStart()) {
logInfo("Starting receiver")
receiverState = Started
receiver.onStart()
logInfo("Called receiver onStart")
} else {
// The driver refused us
stop("Registered unsuccessfully because Driver refused to start receiver " + streamId, None)
}
} catch {
case NonFatal(t) =>
stop("Error starting receiver " + streamId, Some(t))
}
}
onReceiverStart方法在ReceiverSupervisorImpl中实现的。
override protected def onReceiverStart(): Boolean = {
val msg = RegisterReceiver(
//此时的endpoint是Receiver的管理者ReceiverSupervisorImpl的消息循环体
streamId, receiver.getClass.getSimpleName, host, executorId, endpoint)
//Driver端的Endpoint,此时的Boolean必须为true的时候才可以正在startReceiver等后续的工作。
//此时的消息就发送给了ReceiverTracker
trackerEndpoint.askWithRetry[Boolean](msg) //此时就将消息发送给Driver
}
Driver端:ReceiverTrackerEndpoint 接收到ReceiveSupervisor发来的消息。
20. 在receiverAndReply中接收的,源码如下:
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
// Remote messages
case RegisterReceiver(streamId, typ, host, executorId, receiverEndpoint) =>
val successful =
registerReceiver(streamId, typ, host, executorId, receiverEndpoint, context.senderAddress)
context.reply(successful)
case AddBlock(receivedBlockInfo) => if (WriteAheadLogUtils.isBatchingEnabled(ssc.conf, isDriver = true)) {
walBatchingThreadPool.execute(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError { if (active) {
context.reply(addBlock(receivedBlockInfo))
} else {
throw new IllegalStateException("ReceiverTracker RpcEndpoint shut down.")
}
}
})
} else {
context.reply(addBlock(receivedBlockInfo))
}
case DeregisterReceiver(streamId, message, error) =>
deregisterReceiver(streamId, message, error)
context.reply(true)
// Local messages
case AllReceiverIds =>
context.reply(receiverTrackingInfos.filter(_._2.state != ReceiverState.INACTIVE).keys.toSeq)
case StopAllReceivers => assert(isTrackerStopping || isTrackerStopped)
stopReceivers()
context.reply(true)
}
21. registerReceiver源码如下:
/** Register a receiver */private def registerReceiver(
streamId: Int,
typ: String,
host: String,
executorId: String,
receiverEndpoint: RpcEndpointRef,
senderAddress: RpcAddress
): Boolean = {//判断streamId是否是元数据信息中的
if (!receiverInputStreamIds.contains(streamId)) { throw new SparkException("Register received for unexpected id " + streamId)
} if (isTrackerStopping || isTrackerStopped) { return false
} val scheduledLocations = receiverTrackingInfos(streamId).scheduledLocations val acceptableExecutors = if (scheduledLocations.nonEmpty) { // This receiver is registering and it's scheduled by
// ReceiverSchedulingPolicy.scheduleReceivers. So use "scheduledLocations" to check it.
scheduledLocations.get
} else { // This receiver is scheduled by "ReceiverSchedulingPolicy.rescheduleReceiver", so calling
// "ReceiverSchedulingPolicy.rescheduleReceiver" again to check it.
scheduleReceiver(streamId)
} def isAcceptable: Boolean = acceptableExecutors.exists { case loc: ExecutorCacheTaskLocation => loc.executorId == executorId case loc: TaskLocation => loc.host == host
} if (!isAcceptable) { // Refuse it since it's scheduled to a wrong executor
false
} else { val name = s"${typ}-${streamId}"
val receiverTrackingInfo = ReceiverTrackingInfo(
streamId,
ReceiverState.ACTIVE,
scheduledLocations = None,
runningExecutor = Some(ExecutorCacheTaskLocation(host, executorId)),
name = Some(name),
endpoint = Some(receiverEndpoint))
receiverTrackingInfos.put(streamId, receiverTrackingInfo)
listenerBus.post(StreamingListenerReceiverStarted(receiverTrackingInfo.toReceiverInfo))
logInfo("Registered receiver for stream " + streamId + " from " + senderAddress) true
}
}
22. 在Receiver的onstart方法必须初始化所有的资源内容,包括线程,buffer等来准备接收数据,并且必须是非阻塞的。
** * This method is called by the system when the receiver is started. This function * must initialize all resources (threads, buffers, etc.) necessary for receiving data. * This function must be non-blocking, so receiving the data must occur on a different * thread. Received data can be stored with Spark by calling `store(data)`. * * If there are errors in threads started here, then following options can be done * (i) `reportError(...)` can be called to report the error to the driver. * The receiving of data will continue uninterrupted. * (ii) `stop(...)` can be called to stop receiving data. This will call `onStop()` to * clear up all resources allocated (threads, buffers, etc.) during `onStart()`. * (iii) `restart(...)` can be called to restart the receiver. This will call `onStop()` * immediately, and then `onStart()` after a delay. */ def onStart()
23. 例如SocketReceiver这里具体socketReceiver.启动线程接收数据。
def onStart() { // Start the thread that receives data over a connection
new Thread("Socket Receiver") {
setDaemon(true) override def run() { receive() }
}.start()
}
24. 在接收数据的时候不断的存储。
/** Create a socket connection and receive data until receiver is stopped */
def receive() { var socket: Socket = null
try {
logInfo("Connecting to " + host + ":" + port)
socket = new Socket(host, port)
logInfo("Connected to " + host + ":" + port) val iterator = bytesToObjects(socket.getInputStream()) while(!isStopped && iterator.hasNext) {
store(iterator.next)
} if (!isStopped()) {
restart("Socket data stream had no more data")
} else {
logInfo("Stopped receiving")
}
} catch { case e: java.net.ConnectException =>
restart("Error connecting to " + host + ":" + port, e) case NonFatal(e) =>
logWarning("Error receiving data", e)
restart("Error receiving data", e)
} finally { if (socket != null) {
socket.close()
logInfo("Closed socket to " + host + ":" + port)
}
}
}
}
25. 使用ReceiverSupervisorImpl去存储数据。
/**
* Store a single item of received data to Spark's memory.
* These single items will be aggregated together into data blocks before
* being pushed into Spark's memory.
*/def store(dataItem: T) {
supervisor.pushSingle(dataItem)
}
26. 最终调用的是BlockGenerator的addData方法去存储数据。
/**
* Push a single data item into the buffer.
*/def addData(data: Any): Unit = { if (state == Active) {
waitToPush() synchronized { if (state == Active) {// currentBuffer不断的存储数据。
currentBuffer += data
} else { throw new SparkException( "Cannot add data as BlockGenerator has not been started or has been stopped")
}
}
} else { throw new SparkException( "Cannot add data as BlockGenerator has not been started or has been stopped")
}
}
27. currentBuffer是一个ArrayBuffer.
@volatile private var currentBuffer = new ArrayBuffer[Any]
自此,就知道了Spark Streaming使用Receiver接收数据,但是这些数据何时转换成Block?
转换成Block是由BlockGenerator完成的。
1. 在BlockGenerator的start方法中使用定时器把数据不断的生成Block
/** Start block generating and pushing threads. */def start(): Unit = synchronized { if (state == Initialized) {
state = Active
blockIntervalTimer.start()
blockPushingThread.start()
logInfo("Started BlockGenerator")
} else { throw new SparkException(
s"Cannot start BlockGenerator as its not in the Initialized state [state = $state]")
}
}
2. blockIntervalTimer赋值源码如下:
private val blockIntervalTimer = new RecurringTimer(clock, blockIntervalMs, updateCurrentBuffer, "BlockGenerator")
3. 更新Buffer
/** Change the buffer to which single records are added to. */private def updateCurrentBuffer(time: Long): Unit = { try { var newBlock: Block = null
synchronized { if (currentBuffer.nonEmpty) { val newBlockBuffer = currentBuffer
currentBuffer = new ArrayBuffer[Any] val blockId = StreamBlockId(receiverId, time - blockIntervalMs)
listener.onGenerateBlock(blockId)//产生Block
newBlock = new Block(blockId, newBlockBuffer)
}
} if (newBlock != null) {//如果生成Block成功的话,就将Block放入到队列中。
blocksForPushing.put(newBlock) // put is blocking when queue is full
}
} catch { case ie: InterruptedException =>
logInfo("Block updating timer thread was interrupted") case e: Exception =>
reportError("Error in block updating thread", e)
}
}
4. blocksForPushing源码如下:
private val blocksForPushing = new ArrayBlockingQueue[Block](blockQueueSize)
5. Spark默认规定每200ms产生一个Block。
private val blockIntervalMs = conf.getTimeAsMs("spark.streaming.blockInterval", "200ms")
队列中的数据如何写入到磁盘中?
6. 在BlockGenerator的start方法中,通过blockPushThread将Block写入到磁盘中。
/** Start block generating and pushing threads. */def start(): Unit = synchronized { if (state == Initialized) {
state = Active
blockIntervalTimer.start()
blockPushingThread.start()
logInfo("Started BlockGenerator")
} else { throw new SparkException(
s"Cannot start BlockGenerator as its not in the Initialized state [state = $state]")
}
}
7. blockPushThread启动的时候不断的调用keepPushingBlocks
private val blockPushingThread = new Thread() { override def run() { keepPushingBlocks() } }
8. 不断的从队列中取出Block数据,然后通过BlockManager存储。
/** Keep pushing blocks to the BlockManager. */private def keepPushingBlocks() {
logInfo("Started block pushing thread") def areBlocksBeingGenerated: Boolean = synchronized {
state != StoppedGeneratingBlocks
} try { // While blocks are being generated, keep polling for to-be-pushed blocks and push them.
while (areBlocksBeingGenerated) {//每个10ms从队列查看下队列是否有数据,是一个定时器
Option(blocksForPushing.poll(10, TimeUnit.MILLISECONDS)) match { case Some(block) => pushBlock(block) case None =>
}
} // At this point, state is StoppedGeneratingBlock. So drain the queue of to-be-pushed blocks.
logInfo("Pushing out the last " + blocksForPushing.size() + " blocks") while (!blocksForPushing.isEmpty) { val block = blocksForPushing.take()
logDebug(s"Pushing block $block")
pushBlock(block)
logInfo("Blocks left to push " + blocksForPushing.size())
}
logInfo("Stopped block pushing thread")
} catch { case ie: InterruptedException =>
logInfo("Block pushing thread was interrupted") case e: Exception =>
reportError("Error in block pushing thread", e)
}
}
9. pushBlock源码如下:
private def pushBlock(block: Block) {//此时listener是BlockGeneratorListener
listener.onPushBlock(block.id, block.buffer) logInfo("Pushed block " + block.id)
}
}
10. 此时的listener是在BlockGenerator构造的时候传入的。
private[streaming] class BlockGenerator(
listener: BlockGeneratorListener,
receiverId: Int,
conf: SparkConf,
clock: Clock = new SystemClock()
) extends RateLimiter(conf) with Logging {12345671234567
11. 在ReceiverSupervisorImpl中我们前面调用的就是onPushBlock.
/** Divides received data records into data blocks for pushing in BlockManager. */private val defaultBlockGeneratorListener = new BlockGeneratorListener { def onAddData(data: Any, metadata: Any): Unit = { } def onGenerateBlock(blockId: StreamBlockId): Unit = { } def onError(message: String, throwable: Throwable) {
reportError(message, throwable)
} def onPushBlock(blockId: StreamBlockId, arrayBuffer: ArrayBuffer[_]) {
pushArrayBuffer(arrayBuffer, None, Some(blockId))
}
}
12. pushArrayBuffer源码如下:
/** Store an ArrayBuffer of received data as a data block into Spark's memory. */def pushArrayBuffer(
arrayBuffer: ArrayBuffer[_],
metadataOption: Option[Any],
blockIdOption: Option[StreamBlockId]
) {
pushAndReportBlock(ArrayBufferBlock(arrayBuffer), metadataOption, blockIdOption)
}
13. pushAndReportBlock源码如下:
/** Store block and report it to driver */def pushAndReportBlock(
receivedBlock: ReceivedBlock,
metadataOption: Option[Any],
blockIdOption: Option[StreamBlockId]
) { val blockId = blockIdOption.getOrElse(nextBlockId) val time = System.currentTimeMillis val blockStoreResult = receivedBlockHandler.storeBlock(blockId, receivedBlock)
logDebug(s"Pushed block $blockId in ${(System.currentTimeMillis - time)} ms") val numRecords = blockStoreResult.numRecords val blockInfo = ReceivedBlockInfo(streamId, numRecords, metadataOption, blockStoreResult)//把存储后的元数据信息告诉Driver.
trackerEndpoint.askWithRetry[Boolean](AddBlock(blockInfo))
logDebug(s"Reported block $blockId")
}
14. ReceivedBlockHandler中ReceivedBlockHandler负责存储receiver接收的数据Block.
/** Trait that represents a class that handles the storage of blocks received by receiver */private[streaming] trait ReceivedBlockHandler {
/** Store a received block with the given block id and return related metadata */
def storeBlock(blockId: StreamBlockId, receivedBlock: ReceivedBlock): ReceivedBlockStoreResult /** Cleanup old blocks older than the given threshold time */
def cleanupOldBlocks(threshTime: Long)
}
15. store存储的时候分为两种
/**
* Implementation of a `org`.`apache`.`spark`.`streaming`.`receiver`.`ReceivedBlockHandler` which
* stores the received blocks into a block manager with the specified storage level.
*/private[streaming] class BlockManagerBasedBlockHandler(
blockManager: BlockManager, storageLevel: StorageLevel)
extends ReceivedBlockHandler with Logging { def storeBlock(blockId: StreamBlockId, block: ReceivedBlock): ReceivedBlockStoreResult = { var numRecords = None: Option[Long] val putResult: Seq[(BlockId, BlockStatus)] = block match { case ArrayBufferBlock(arrayBuffer) =>
numRecords = Some(arrayBuffer.size.toLong)
blockManager.putIterator(blockId, arrayBuffer.iterator, storageLevel,
tellMaster = true) case IteratorBlock(iterator) => val countIterator = new CountingIterator(iterator) val putResult = blockManager.putIterator(blockId, countIterator, storageLevel,
tellMaster = true)
numRecords = countIterator.count
putResult case ByteBufferBlock(byteBuffer) =>
blockManager.putBytes(blockId, byteBuffer, storageLevel, tellMaster = true) case o => throw new SparkException(
s"Could not store $blockId to block manager, unexpected block type ${o.getClass.getName}")
} if (!putResult.map { _._1 }.contains(blockId)) { throw new SparkException(
s"Could not store $blockId to block manager with storage level $storageLevel")
}
BlockManagerBasedStoreResult(blockId, numRecords)
}
ReceiverSupervisor的startReceiver启动全过程流程如下:
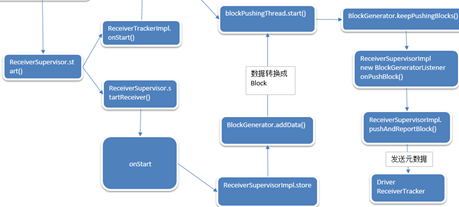
Spark Streaming的流数据不断接收数据总体流程如下:
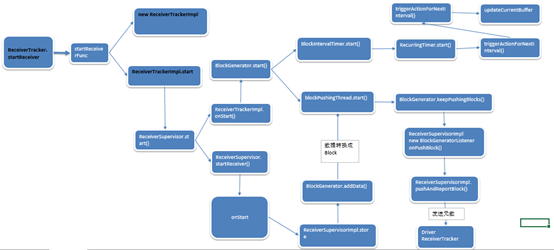
备注:
1、DT大数据梦工厂微信公众号DT_Spark
2、IMF晚8点大数据实战YY直播频道号:68917580
3、新浪微博: http://www.weibo.com/ilovepains
本文转自http://blog.csdn.net/snail_gesture/article/details/51479015
转载于:https://blog.51cto.com/love205088/1784658















 1443
1443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









