






运营反馈某个功能速度很慢,查了一下,定位到如下 SQL:
select id from user
where name like ‘%foobar%’
order by created_at limit 10;
业务需要,LIKE 的时候必须使用模糊查询,我当然知道这会导致全表扫描,不过速度确实太慢了,直观感受,全表扫描不至于这么慢!
我使用的数据库是 PostgreSQL,不过它和 MySQL 差不多,也可以 EXPLAIN:
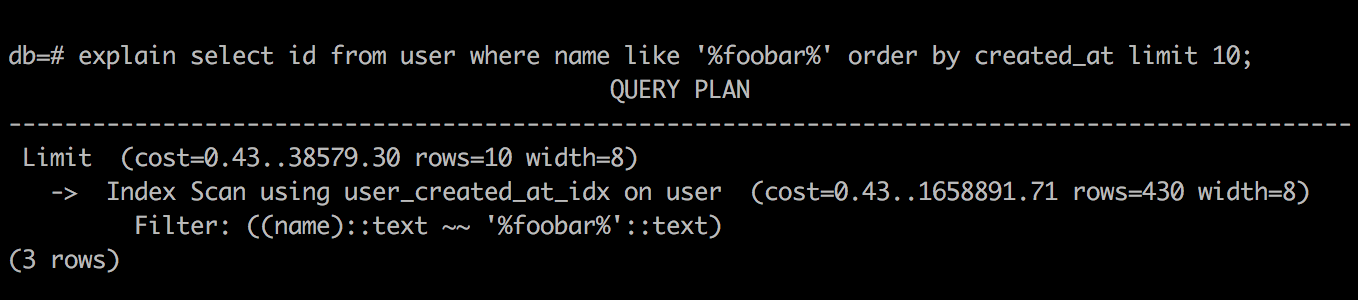
SQL With LIMIT
如上所示:先按照 created_at 索引排序,再 filter 符合条件的数据,最后 limit 返回结果,看上去很完美,不过为什么慢呢?出于经验主义,我去掉了 limit 再执行:
select id from user
where name like ‘%foobar%’
order by created_at;
果不其然,速度快了好几倍,再看看对应的 EXPLAIN:
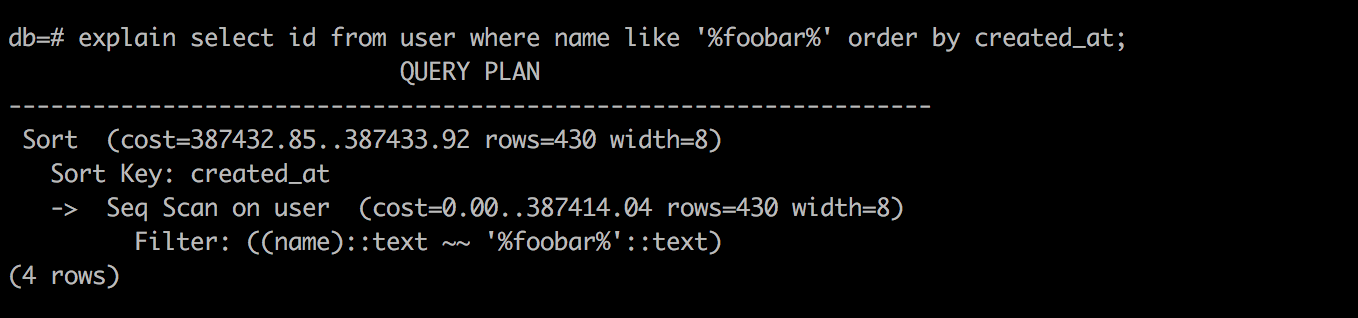
SQL Without LIMIT
如上所示:去掉 limit 后,根本就没用上索引,直接全表扫描,不过反而更快。
为什么呢?要想搞清楚缘由,你需要理解本例中 SQL 查询的处理流程:当使用 limit 时,因为只是返回几条数据,所以优化器觉得采用一个满足 order by 的索引比较划算;当不使用 limit 时,因为要返回所有满足条件的数据,所以优化器觉得不如直接全表扫描。不过就算知道这些还是不足以解释为什么在本例中全表扫描反而快,实际上这是因为当使用索引的时候,除非使用了 covering index,否则一旦索引定位到数据地址后,这里会有一个「回表」的操作,形象一点来说,就是返回原始表中对应行的数据,以便引擎进行再次过滤(比如本例中的 like 运算),一旦回表操作过于频繁,那么性能无疑将急剧下降,全表扫描没有这个问题,因为它就没用索引,所以不存在所谓「回表」操作。
我应该解释清楚了吧,另外,前面提到了 covering index,有兴趣的自己查吧。















 393
393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









