







flume:收集数据的工具,可以自己是一个集群,可以在后台运行
flume数据流转图:
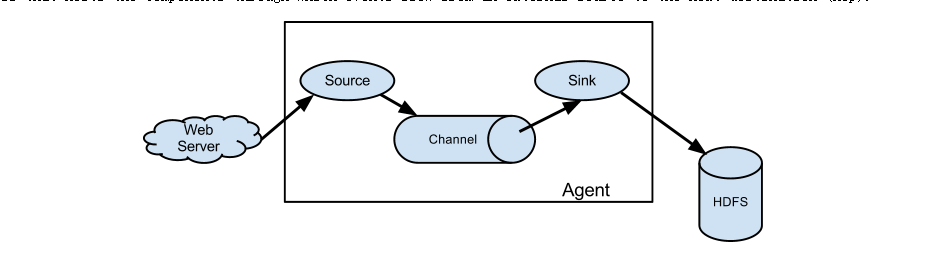
flume分为三部分:
1、source:数据的来源
2、channel
3、sink:数据写到去哪里
source分为两大类,1、主动的source、2、被动的source。
主动的source:由flume主动去取数据
被动的source:由别人传给flume,被动的source是服务端,服务端需要绑定一个端口。
flume安装的先决条件:
1、jdk 1.6及以上
2、内存
3、磁盘空间
4、目录权限
1、解压 flume安装包
2、编辑一个agent 配置文件
vim test1
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = node14
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
$ /usr/flume-1.6.0/bin/flume-ng agent --conf conf --conf-file test1 --name a1 -Dflume.root.logger=INFO,console
注: conf:为flume的配置文件的目录, test1是agent配置文件目录 a1 就是agent配置文件中的a1 console是控制台的意思
在另外一台机器上输入 telnet node14 44444 然后随便输入,就会在node11控制台上显示内容了。
Avro source: Avro是一种数据交换格式(Avro是一种基于字节的交换格式,json是一种基于字符的交换格式)
什么样的协议是Avro协议,一定不是http协议,http是一种字符协议,RPC协议就是发送字节数据的,rmi协议:远程方法调用(webservice)
rmi是基于java的,rpc是跨平台的 ,rpc:远程过程调用协议
exec source:执行命令的source,主动的source
JMS source:java消息服务(第三方支付会用到)
Spooling Directory Source: 是一个主动的source,由flume监控一个目录,如果目录中有文件,就去读取
Kakfa source:
NetCat source:基于tcp协议的一个被动的source
sink
hdfs sink:把数据写到hdfs中
hive sink:
logger sink:
Avro sink:用于两个句群服务的
File Roll Sink : 会根据文件大小和文件时间来写文件的,不是写到一个文件中去的
null sink:写到数据黑洞中
hbasesink:
kakfa sink:
vim test2 (这是一个Spooling Directory Source 和File Roll Sink 的配置文件 )
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type =spooldir
a1.sources.r1.spoolDir=/opt/flume/
# Describe the sink
a1.sinks.k1.type =file_roll
a1.sinks.k1.sink.directory=/opt/sink
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
vim test3(这是一个Spooling Directory Source 和hdfs Sink 的配置文件 )
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type =spooldir
a1.sources.r1.spoolDir=/opt/flume/
# Describe the sink
a1.sinks.k1.type =hdfs
a1.sinks.k1.hdfs.path=hdfs://liuhaijing/flume/data
a1.sinks.k1.hdfs.rollInterval=0 ##间隔多长时间生成一个文件,禁用必须写0
a1.sinks.k1.hdfs.rollSize=10240000 ##根据大小生成文件
a1.sinks.k1.hdfs.rollCount=0 ##数量,禁用必须写0
a1.sinks.k1.hdfs.idleTimeout=3 ##文件超时关闭时间
a1.sinks.k1.hdfs.fileType=DataStream ##数据类型
#a1.sinks.k1.type =hdfs
#a1.sinks.k1.type =hdfs
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
vim test4
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type =spooldir
a1.sources.r1.spoolDir=/opt/flume/
# Describe the sink
a1.sinks.k1.type =hdfs
a1.sinks.k1.hdfs.path=hdfs://liuhaijing/flume/data/%Y-%m-%d/%H%M
a1.sinks.k1.hdfs.rollInterval=0
a1.sinks.k1.hdfs.rollSize=10240000
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.idleTimeout=3
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.round=true ##配置为true表示启动
a1.sinks.k1.hdfs.roundValue=10 ##每隔10分钟产生一个新文件
a1.sinks.k1.hdfs.roundUnit=minute ##单位
a1.sinks.k1.hdfs.useLocalTimeStamp=true ##启用本机时间
#a1.sinks.k1.type =hdfs
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
vim test5 (exec source (主动的source) 和 和hdfs Sink 的配置文件 )
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type =exec
a1.sources.r1.command=tail -F /opt/data/access.log
# Describe the sink
a1.sinks.k1.type =hdfs
a1.sinks.k1.hdfs.path=hdfs://liuhaijing/flume/data/%Y-%m-%d
a1.sinks.k1.hdfs.rollInterval=0
a1.sinks.k1.hdfs.rollSize=10240
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.idleTimeout=3
a1.sinks.k1.hdfs.fileType=DataStream
#a1.sinks.k1.hdfs.round=true
#a1.sinks.k1.hdfs.roundValue=10
#a1.sinks.k1.hdfs.roundUnit=minute
a1.sinks.k1.hdfs.useLocalTimeStamp=true
#a1.sinks.k1.type =hdfs
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
flume 是数据收集工具,可以将数据收集到hdfs上,下面是nginx的配置和 flume的执行命令
nginx.conf:
log_format my_format '$remote_addr^A$msec^A$http_host^A$request_uri';
location = /log.gif {
default_type image/gif;
access_log /opt/data/access.log my_format;
}
flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console
etl的结果存储到hbase中,由于考虑到不同事件有不同的数据格式,所以我们将最终etl的结果保存到hbase中,我们使用单family的数据格式,rowkey的生产模式我们采用timestamp+uuid.crc编码的方式。hbase创建命令:create 'event_logs', 'info'
kafka sink
a1.sources = r1
a1.sources.r1.type =spooldir
a1.sources.r1.spoolDir=/opt/flume/
a1.channels = c1
a1.channels.c1.type =memory
a1.channels.c1.capacity=100
a1.sinks = k1
a1.sinks.k1.channel=c1
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList=192.168.47.12:9092,192.168.47.13:9092,192.168.47.14:9092
a1.sinks.k1.custom.partition.key=kafkaPartition
a1.sinks.k1.topic=test2
a1.sinks.k1.serializer.class=kafka.serializer.StringEncoder















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









