







在初始化过程中处理mybatis-config.xml配置文件中,使用DOM解析,并结合XPath解析XML配置文件。

上面三个接口是jdk中的,mybatis封装了它们。
XMLMapperEntityResolver 实现了 EntityResolver 用作离线加载DTD文档即如下所示的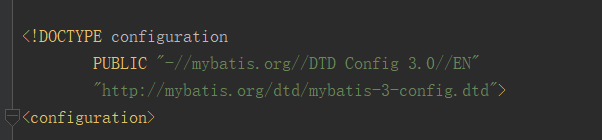
避免联网加载导致缓慢
其中的resolveEntity方法入参解释如下:
DTD声明始终以!DOCTYPE开头,空一格后跟着文档根元素的名称,如果是内部DTD,则再空一格出现[],在中括号中是文档类型定义的内容. 而对于外部DTD,则又分为私有DTD与公共DTD,私有DTD使用SYSTEM表示,接着是外部DTD的URL. 而公共DTD则使用PUBLIC,接着是DTD公共名称,接着是DTD的URL
doctype 属性可返回与文档相关的文档类型声明(Document Type Declaration)。
systemId: 外部资源(多半是DTD)的URI,比如本地文件file:///usr/share/dtd/somefile.dtd或者网络某个地址的文件http://www.w3.org/somefile.dtd;
publicId: systemId已经可以表示任何位置的外部DTD资源了,但是它是直接指向相应的资源,publicId的作用在于其间接性。
publicID就相当于一个名字,这个名字代表了一个外部资源。
比如,我们规定”W3C HTML 4.01″这个字符串对应”http://www.w3.org/somedir/somefile.dtd”这个资源。
那么,publicID=”W3C HTML 4.01″ 和 systemID=”http://www.w3.org/somedir/somefile.dtd”是一样的,
二者都引用了http://www.w3.org/somedir/somefile.dtd作为该文档的外部DTD。
对于以DTD为Schema的XML文件
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN " "http://java.sun.com/dtd/web-app_2_3.dtd ">
publicId是-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN
SystemId是http://java.sun.com/dtd/web-app_2_3.dtd
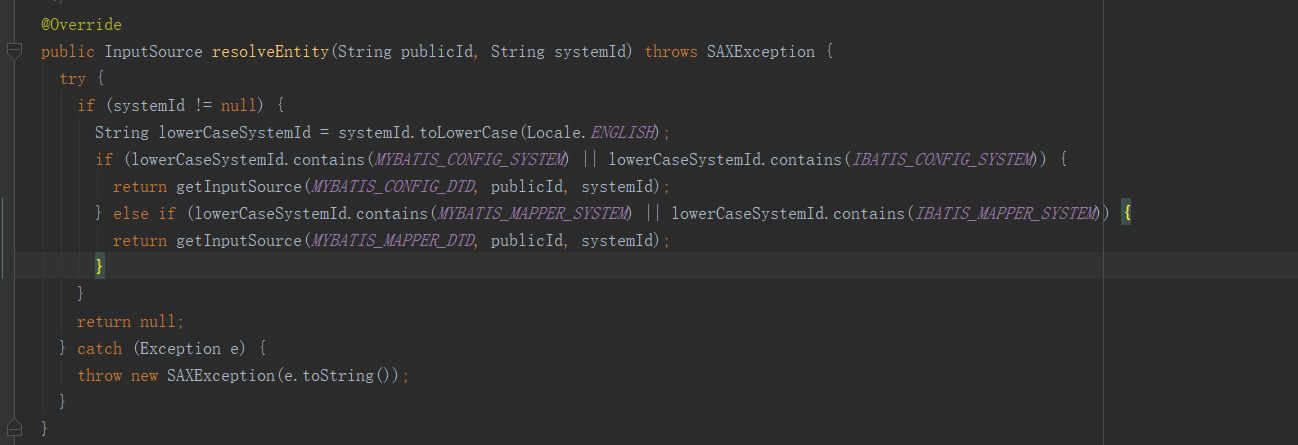
调用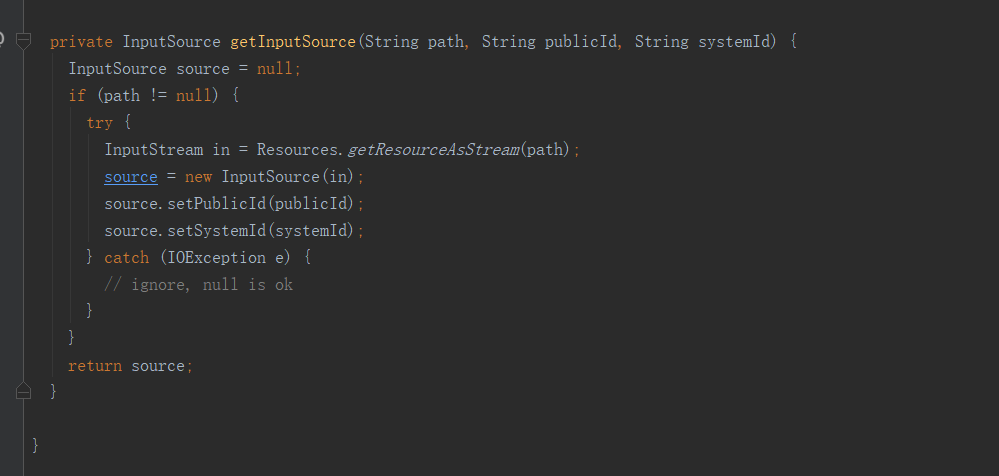
读取dtd文档形成InputSource对象。
在XPathParser中
如下构造方法:

先调用

然后再调用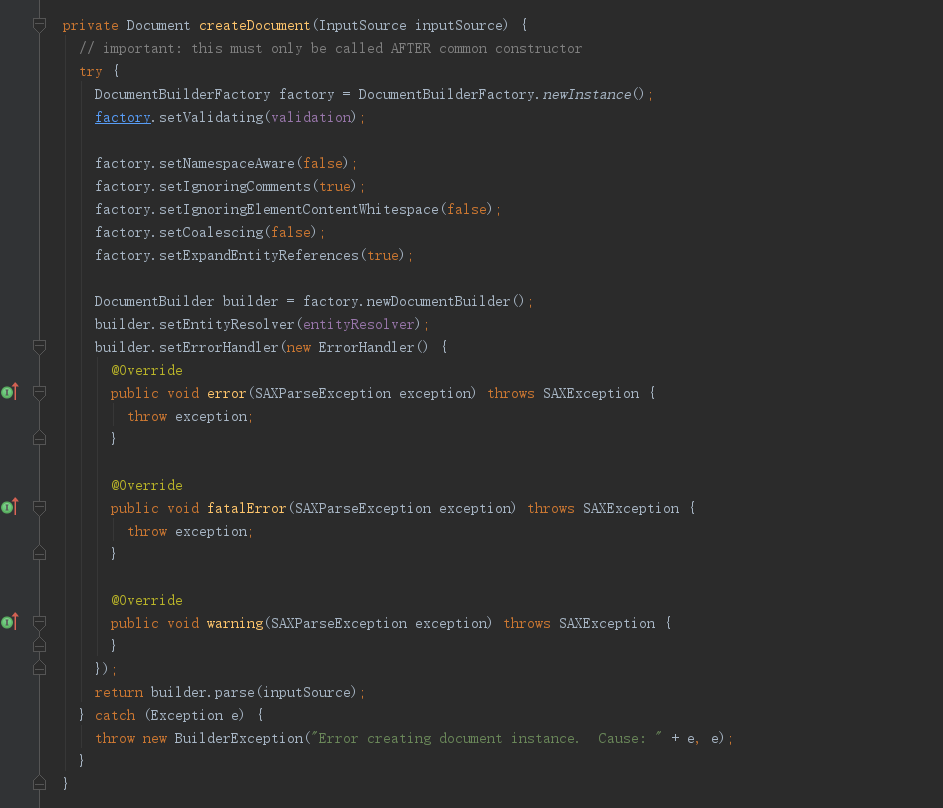
加载xml文档
其中builder.parse(inputSource)是加载xml文件:调用如下方法
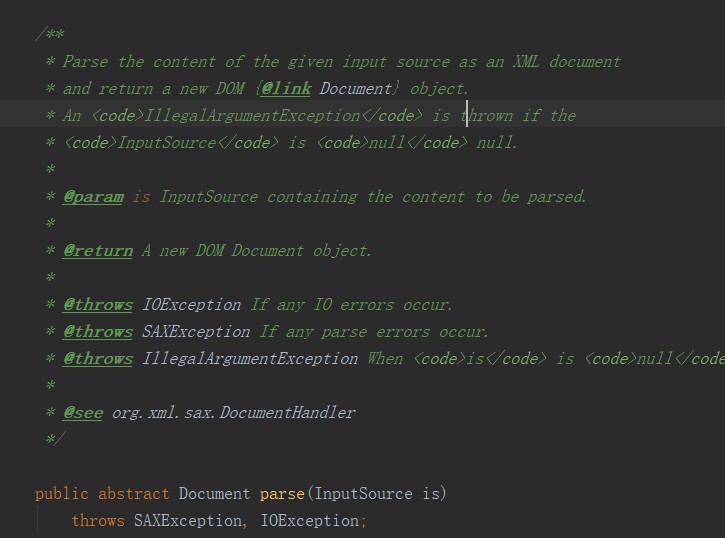
PropertyParser.parse方法如下:
使用了GenericTokenParser创建对象,处理占位符格式为‘${}’:

GenericTokenParser为通用字占位符解析器
以下为其parse方法的逻辑:
public String parse(String text) {
if (text == null || text.isEmpty()) {
return "";
}
// search open token 从openToken占位符开始标记开始查
int start = text.indexOf(openToken, 0);
if (start == -1) {
return text;
}
char[] src = text.toCharArray();
int offset = 0;
final StringBuilder builder = new StringBuilder();
StringBuilder expression = null;
while (start > -1) {
if (start > 0 && src[start - 1] == '\\') {
// this open token is escaped. remove the backslash and continue.
//遇到了转义的开始标记,移除转移标记并将其拼接好放入builder中
builder.append(src, offset, start - offset - 1).append(openToken);
offset = start + openToken.length();//修改offset偏移量的位置移到openToken之后
} else {
// found open token. let's search close token.
//开始查找占位符开始标记,但没转义标志
if (expression == null) {
expression = new StringBuilder();
} else {
expression.setLength(0);//将这个expression大小改为0长度
}
//将前面的字符串追加Bulider中
builder.append(src, offset, start - offset);
offset = start + openToken.length();//修改offset偏移量的位置移到openToken之后
int end = text.indexOf(closeToken, offset);//从offset之后开始找closeToken索引位置
while (end > -1) {//找到closeToken
if (end > offset && src[end - 1] == '\\') {//除以转义结束标记同上openToken方法
// this close token is escaped. remove the backslash and continue.
expression.append(src, offset, end - offset - 1).append(closeToken);
offset = end + closeToken.length();//修改offset偏移量的位置移到closeToken之后
end = text.indexOf(closeToken, offset);//修改end索引位置到closeToken之后
} else {
//将开始标记和结束标记之间的字符串追加到expression中保存
expression.append(src, offset, end - offset);
offset = end + closeToken.length();//修改offset的索引位置到closeToken之后
break;
}
}
if (end == -1) {
// close token was not found.
//没有找到结束标记closeToken就添加到builder中范围是从start即openToken
builder.append(src, start, src.length - start);
offset = src.length;
} else {
//将占位符字面值交给handleToken处理,并将处理直接追加到builderz中保存
//最终拼凑出解析后的完整内容
builder.append(handler.handleToken(expression.toString()));
offset = end + closeToken.length();//修改offset的索引位置到closeToken之后
}
}
start = text.indexOf(openToken, offset);//移动start索引位置到openToken之后
}
if (offset < src.length) {//这里的offset是0则就是把0到src.length整体长度给追加进去
builder.append(src, offset, src.length - offset);
}
return builder.toString();
}
}
TokenHandler接口共有四个实现类


其中上面的
使用了PropertyParser中的一个私有静态内部类VariableTokenHandler
其中的handleToken方法:
@Override
public String handleToken(String content) {
if (variables != null) {//<properties>节点下定义的键值对,用于替换占位符,检测本集合是否为空
String key = content;
if (enableDefaultValue) {//是否支持占位符中使用默认值功能
final int separatorIndex = content.indexOf(defaultValueSeparator);//查找到指定占位符和默认值之间分隔符
String defaultValue = null;
if (separatorIndex >= 0) {//若有分隔符
key = content.substring(0, separatorIndex);//获取占位符名称即key
defaultValue = content.substring(separatorIndex + defaultValueSeparator.length());//获取默认值即value
}
if (defaultValue != null) {//若有默认值
return variables.getProperty(key, defaultValue);//在variables集合中查找指定占位符
}
}
if (variables.containsKey(key)) {//不支持占位符中使用默认值功能
return variables.getProperty(key);//直接查找variables集合
}
}
return "${" + content + "}";//variables集合是空值处理
}
举个例子:

${username:root},:就为分隔符,则PropertyParser会解析后使用username在variables集合中相对应的值若无则使用root为username的默认值
GenericTokenParser 只是处理转义标志和查找占位符,具体解析有其指定的 TokenHandler实现,(默认值和动态sql解析)















 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









