






源代码中的Java类插装 本节将讨论如何实现源代码级插装,并将提供一些最佳实践和示例代码。文章还介绍了一些新的跟踪结构,我将在源代码插装的上下文中阐明它们的操作和它们的插装模式。
虽然其他选择已经流行,但源代码插装在某些实例中是无法避免的;在某些情况下,它是惟一的解决方案。借助一些明智的预防措施,它可以实现良好的效果。需要考虑的事项包括:
如果插装代码的方案可用,并且无法实现配置更改来垂直影响插装,则使用可配置和灵活的跟踪 API 非常重要。
抽象的跟踪 API 类似于事件记录 API(如 log4j),它们的共用属性包括:
运行时冗长控制:log4j 记录程序和附加程序的冗长等级可以在系统启动时配置,并随后在运行时修改。同样,跟踪 API 应该能够根据分级名称模式来控制哪些指标名称受跟踪支持。
输出端点配置:log4j 通过记录程序发起记录声明,并将它分发给附加程序。经过配置,附加程序可以将记录流发送给各种输出,如文件、套接字和电子邮件。跟踪 API 不需要多样的输出方式,但抽象专有或特定于 APM 系统的库的能力将保护源代码不受外部配置的更改。
在某些情况下,通过其他方法来跟踪具体的项目不太可行。通常,我将这种情况称作上下文跟踪。我使用该术语描述的性能数据并不是很重要,但它为主要数据添加上下文。
上下文跟踪上下文跟踪受具体的应用程序影响极大,但是可以考虑一个经过简化的例子:含有 processPayroll(long clientId) 方法的 payroll-processing 类。当被调用时,该方法计算并存储各客户员工的薪水。您可以通过各种方法插装该方法,但是,执行中的底层模式清楚表明,调用时间的增加与员工的数量不成比例。因此,研究 processPayroll 的运行时间趋势没有上下文可供参考,除非您知道程序每次处理的员工数量。简单来讲,对于特定的时间段,processPayroll 平均耗时 x 毫秒。无法确定这个值反映的性能是好还是坏,因为您不知道它处理的员工数量是 1 还是 150,而两种情况反映的性能差别巨大。清单 5 在代码中显示了这个简化的概念:
清单5.上下文跟踪的例子
public void processPayroll(long clientId) {
Collection employees = null;
// Acquire the collection of employees
//...
//...
// Process each employee
for(Employee emp: employees) {
processEmployee(emp.getEmployeeId(), clientId);
}}
此处的主要挑战是,根据大多数插装技巧,processPayroll() 方法中的任何东西都是不可触及的。因此,虽然能够插装 processPayroll 甚至 processEmployee,但是却无法跟踪员工的数量,从而不能为方法的性能数据提供上下文。清单 6 显示了一个拙劣的硬编码示例(且有点效率不高),它将捕获上面提到的上下文数据:清单 6. 上下文跟踪示例
public void processPayrollContextual(long clientId) {
Collection employees = null;
// Acquire the collection of employees
employees = popEmployees();
// Process each employee
int empCount = 0;
String rangeName = null;
long start = System.currentTimeMillis();
for(Employee emp: employees) {
processEmployee(emp.getEmployeeId(), clientId);
empCount++;
}
rangeName = tracer.lookupRange("Payroll Processing", empCount);
long elapsed = System.currentTimeMillis()-start;
tracer.trace(elapsed, "Payroll Processing", rangeName, "Elapsed Time (ms)");
tracer.traceIncident("Payroll Processing", rangeName, "Payrolls Processed");
log("Processed Client with " + empCount + " employees.");
清单 6 中的关键部分是 tracer.lookupRange 调用。Ranges 是指定的收集,它由数值范围限制键控,并且拥有一个表示数值范围名称的 String 值。不再跟踪薪水处理的简单无格式运行时间,清单 6 将员工计数划分为范围,有效分隔运行时间并根据基本类似的员工计数将它们分组。图 10 显示了 APM 系统生成的指标树:| 图 10:根据范围分组的薪水处理时间
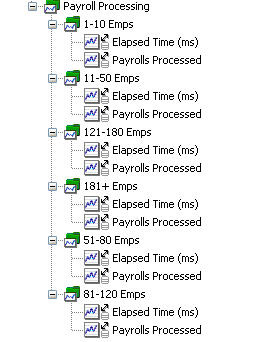
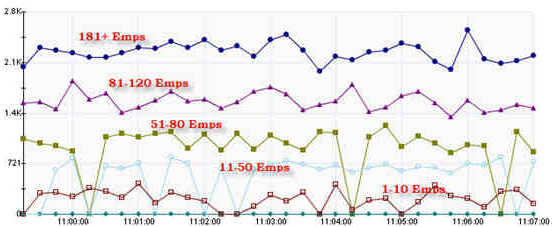
图 11 演示了根据员工计数划分的薪水处理运行的时间,它揭示了员工数量和运行时间之间的相互关系:=图 11. 各范围的薪水处理运行时间
跟踪程序配置属性允许在属性文件中包括 URL,并能在其中定义范围和阀值(我将简单介绍一下阀值)。属性将在跟踪程序的构造时间被读取,并为 tracer.lookupRange 实现提供后台数据。清单 7 显示了 Payroll Processing 范围的示例配置。我选择使用 java.util.Properties 的 XML 表示,因为它更能兼容奇怪的字符.清单 7. 范围配置示例
Payroll Process Range
181+ Emps,10:1-10 Emps,50:11-50 Emps,
80:51-80 Emps,120:81-120 Emps,180:121-180 Emps
注入外部定义的范围可以使您的应用程序不必频繁更新源代码,这受益于预期的调整和服务水平协议(SLA)在业务方面的变更。当范围和阀值更改生效之后,您只需更新外部文件,而不是应用程序本身。
跟踪阀值和SLA 外部可配置上下文跟踪的灵活性支持以更加准确和粒度化的方式来定义和测量性能阀值。范围 定义一系列数值区间,可以在其中对测量数据进行分类,而阀值 是对范围的进一步分类,它根据测量数据的确定范围对获取的测量数据进行分类。在分析收集的性能数据时,一个常见的需求是确定和报告执行是 “成功” 还是 “失败”(因为它们未在指定时间发生)。这些数据的总和可以作为关于系统运行健康状况和性能的通用成绩单,或者作为某种形式的 SLA 遵从性评价。
使用薪水处理系统示例,考虑一个内部服务级目标,它将薪水的执行时间(在定义的员工数范围之内)定义为 Ok、Warn 和 Critical 3 个区间。生成阀值计数的流程从概念上来说非常简单。您只需为跟踪程序提供您认为是各类别各区间的上限运行时间的值,并引导跟踪程序为分类的运行时间发起一个 tracer.traceIncident,然后 — 为简化报告 — 提供一个总数。表 2 显示了一些经过设计的 SLA 运行时间:
表2.薪水处理阀值
员工数
Ok (ms)
Warn (ms)
Critical (ms)
1-10
280
400
>400
11-50
850
1200
>1200
51-80
900
1100
>1100
81-120
1100
1500
>1500
121-180
1400
2000
>2000
181+
2000
3000
>3000
ITracer API 使用与范围中相同的 XML(属性)文件中定义的值实现了阀值报告。范围和阀值定义在两个方面稍有不同。首先,阀值定义的关键值是一个正则表达式。当 ITracer 在跟踪一个数值时,它会检查阀值正则表达式是否匹配被跟踪指标的复合名称。如果匹配,则阀值会将测量数据分类为 Ok、Warn 或 Critical,并为跟踪附加一个额外的 tracer.traceIncident。其次,由于阀值只定义了两个值(根据定义,Critical 值大于 warn 值),因此配置只由两个数值组成。清单 8 显示了之前介绍的薪水处理 SLA 的阀值配置:清单 8. 薪水处理的阀值配置
1100,1500
280,400
850,1200
900,1100
1400,2000
2000,3000
图 12 显示添加了阀值指标的薪水处理的指标树:
图 12. 添加了阀值的薪水处理指标
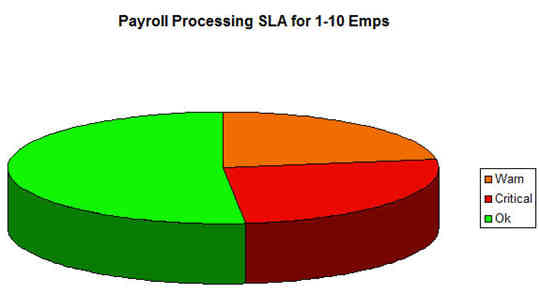
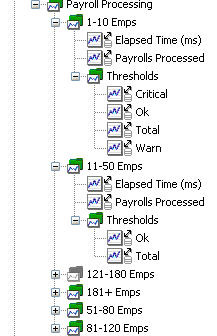 图 13 演示了哪些收集的数据可以表示在饼形图中:
图 13 演示了哪些收集的数据可以表示在饼形图中:
图 13. 薪水处理的 SLA 汇总(1 到 10 名员工)
确保查找上下文和阀值分类的效率和速度非常重要,因为它们在完成实际工作的线程中执行。在 ITracer 实现中,所有指标名称在第一次被跟踪程序发现时,将存储在(线程安全)为具备和不具备阀值的指标指定的映射中。当特定指标的跟踪事件发生后,阀值确定过程占用的时间是一个 Map 查找时间,它的速度通常足够快。如果阀值条目或指标名称的数量非常大,则一种合理的解决方案是推迟阀值确定,并在异步跟踪线程池中处理它们。















 201
201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









