







利用selenium爬取QQ空间的留言板,方法不怎么样,练练手。直接上代码:
#-*- coding-8 -*-
from bs4 import BeautifulSoup
from selenium import webdriver
import time
#使用selenium
driver = webdriver.PhantomJS(executable_path=r"F:\常用软件\python\phantomjs-2.1.1-windows\bin\phantomjs.exe")
driver.maximize_window()
#登录QQ空间
def get_liuyanban(qq):
import time
driver.get('http://user.qzone.qq.com/{}/334'.format(qq))
print(qq+'的空间留言板')
time.sleep(5)
try:
driver.find_element_by_id('login_div')
a = True
except:
a = False
if a == True:
driver.switch_to.frame('login_frame')
driver.find_element_by_id('switcher_plogin').click()
driver.find_element_by_id('u').clear()#选择用户名框
driver.find_element_by_id('u').send_keys('访问者的QQ号')
driver.find_element_by_id('p').clear()
driver.find_element_by_id('p').send_keys('访问者的密码')
driver.find_element_by_id('login_button').click()
time.sleep(3)
driver.implicitly_wait(3)
try:
driver.find_element_by_id(r'QM_OwnerInfo_Icon')
b = True
print('可以访问')
except:
b = False
print('没有访问权限或者网络错误,请重试')
if b == True:
print('开始加载')
driver.switch_to.frame('app_canvas_frame')
num = driver.find_element_by_id('cnt')
#总留言数
x = int(num.text)
y = x // 10
#print(y),得到总页数,就可以根据这个可以爬取所有留言
#得到留言者,留言时间,留言内容
for i in range(5):#这边暂时就爬取五页,随意修改
names = driver.find_elements_by_css_selector('.c_tx.q_namecard')
times = driver.find_elements_by_css_selector('.c_tx3.mode_post')
ments = driver.find_elements_by_class_name('cont')
print('第%s页留言'%(i+1))
for name,stime,ment in zip(names,times,ments):
data = {
'留言人':name.text,
'留言时间':stime.text,
'留言内容':ment.text
}
print(data)
page_down = driver.find_element_by_xpath(r".//*[@id='pager_bottom']/div/p[1]/a[2]")
page_down.click()#翻页操作
time.sleep(3)
driver.implicitly_wait(3)
print('OK')
print("==========完成================")
driver.close()
driver.quit()
if __name__ == '__main__':
get_liuyanban('想要访问的人的QQ号')
分开说一下代码:
第一行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
#-*- coding-8 -*-然后导入三个模块,初始化浏览器PhantomJS:
from bs4 import BeautifulSoup
from selenium import webdriver
import time
#使用selenium
driver = webdriver.PhantomJS(executable_path=r"F:\常用软件\python\phantomjs-2.1.1-windows\bin\phantomjs.exe")
driver.maximize_window()定义函数,访问网页,这边有一个小问题,就是如果不在函数内import time的话,那么就会报错,说time不是一个全局变量巴拉巴拉的。
def get_liuyanban(qq):
import time
driver.get('http://user.qzone.qq.com/{}/334'.format(qq))
print(qq+'的空间留言板')
time.sleep(5)分析网页:登入界面的‘’iframe‘’,‘’帐号密码登录‘’,“输入QQ号的输入框”,“输入密码的输入框”,“登入按钮”的位置信息。
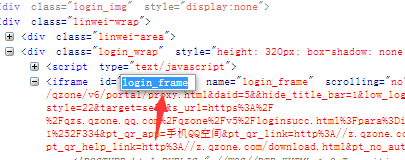
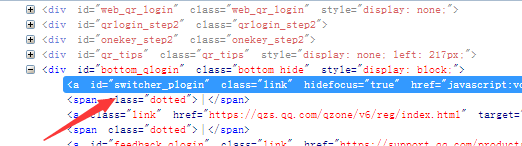
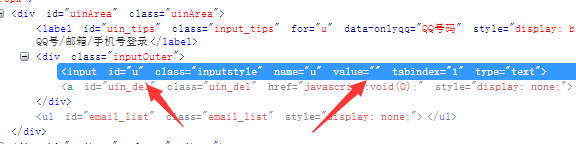
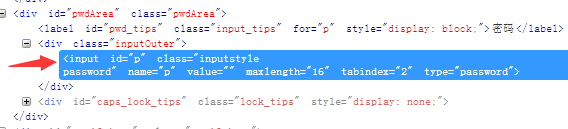

分别可以得出:id = login_frame,id = switchar_plogin,id = u,id = p,id = login_bottom
try:
driver.find_element_by_id('login_div')
a = True
except:
a = False
if a == True:
driver.switch_to.frame('login_frame')
driver.find_element_by_id('switcher_plogin').click()
driver.find_element_by_id('u').clear()#选择用户名框
driver.find_element_by_id('u').send_keys('访问者的QQ号')
driver.find_element_by_id('p').clear()
driver.find_element_by_id('p').send_keys('访问者的密码')
driver.find_element_by_id('login_button').click()
time.sleep(3)
driver.implicitly_wait(3)判断login_div是判断有没到登入界面,到了的话,切换frame到输入框那儿,然后模拟登入,driver.implicitly是隐式等待。
QQ空间一般还会有无权限登入的问题,所以通过寻找有无id = QM_OwnerInfo_Icon的来判断是否有权限进入。进入后同样切换到留言板的frame,然后通过css路径定位到我们所要的要素:留言人,留言时间,留言内容。
try:
driver.find_element_by_id(r'QM_OwnerInfo_Icon')
b = True
print('可以访问')
except:
b = False
print('没有访问权限或者网络错误,请重试')
if b == True:
print('开始加载')
driver.switch_to.frame('app_canvas_frame')
num = driver.find_element_by_id('cnt')
#总留言数
x = int(num.text)
y = x // 10
#print(y),得到总页数,就可以根据这个可以爬取所有留言
#得到留言者,留言时间,留言内容
for i in range(5):#这边暂时就爬取五页,随意修改
names = driver.find_elements_by_css_selector('.c_tx.q_namecard')
times = driver.find_elements_by_css_selector('.c_tx3.mode_post')
ments = driver.find_elements_by_class_name('cont')
print('第%s页留言'%(i+1))
for name,stime,ment in zip(names,times,ments):
data = {
'留言人':name.text,
'留言时间':stime.text,
'留言内容':ment.text
}
print(data)
page_down = driver.find_element_by_xpath(r".//*[@id='pager_bottom']/div/p[1]/a[2]")
page_down.click()#翻页操作
time.sleep(3)
driver.implicitly_wait(3)
print('OK')
print("==========完成================")
driver.close()
driver.quit()这边还读取了总留言数,而一页是呈现10条留言,这样就可以算出所有页数,模拟点击下一页的按钮,进入下一页继续读取。当然这边也可以把这些信息存成文件,或者加一些其它的操作。
这个程序也有一点点小问题,等待时间过久,爬取的时间有些为空,留言内容有表情,或者图片的时候呈现不对。如果再修修改改应该没问题。















 906
906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









