







solr是apache下的一个用于做搜索引擎的高级项目,使用它可以满足绝大部分应用的搜索需求。
主机环境:
Linux:centos6.5
JDK:1.8
solr:7.3.0
zookeeper:3.4.8
mmseg4j-solr:2.4.0
1. 创建与启动solr集群
使用三台虚拟机模拟创建solr集群
| IP | 名称 | |
|---|---|---|
| 192.168.245.128 | APP1 | |
| 192.168.245.129 | APP2 | |
| 192.168.245.130 | APP3 |
下载solr-7.3.0.tgz
下载地址1: http://mirror.bit.edu.cn/apache/lucene/solr/7.3.0/
下载地址2:https://github.com/apache/lucene-solr/releases/tag/releases%2Flucene-solr%2F7.3.0
将包上传到linux主机上,执行命令提取安装脚本
--将压缩包中的install_solr_service.sh提取出来
tar xzf solr-7.3.0.tgz solr-7.3.0/bin/install_solr_service.sh --strip-components=2执行安装脚本(必须安装JDK)
sudo bash ./install_solr_service.sh solr-7.3.0.tgz -i /home/solr/proc/solr -d /home/solr/data/solr -u solr -s solr -p 8983-i: solr安装目录
-d:solr实时文件目录
-u:为solr创建的操作系统用户名
-s:开机启动服务名称
-p:监听端口
如果安装并设置了环境变量后还报JAVA_HOME找不到的话可以参考如下步骤操作,否则忽略这一步:
#使用root用户编辑/etc/profile,在文件最后添加jdk相关的信息
export JAVA_HOME=/home/jionsvolk/proc/jdk1.8.0_65
export JAVA_BIN=$JAVA_HOME/bin
export PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME JAVA_BIN PATH CLASSPATH
#在当前用户主目录下编辑.bashrc文件
vi .bashrc
添加:alias sudo='sudo env PATH=$PATH'
#修改sudo默认配置
sudo visudo
# Defaults env_reset # 注释掉原有配置
# Defaults env_keep=”…” # 注释掉指定的变量保持
Defaults !env_reset # 修改为不重置环境
或者
Defaults env_reset
Defaults env_keep="JAVA_HOME"重启主机,再次执行solr安装脚本install_solr_service.sh
因为solr自带有jetty容器,就没有部署到tomcat中了,而且也已经设置为开机启动。如果想部署到tomcat可以将solr安装目录下/server/solr-webapp/下面的内容复制过去
安装与配置zookeeper集群
下载zookeeper-3.4.8
下载地址1:http://mirror.bit.edu.cn/apache/zookeeper/
下载地址2:https://github.com/apache/zookeeper/releases
上传到linux主机,并解压
tar -xf zookeeper-3.4.8修改配置文件
cd /home/solr/proc/zookeeper-3.4.8/conf
cp zoo_sample.conf zoo.conf# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/solr/data/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1 = 192.168.245.128:2888:3888
server.2 = 192.168.245.129:2888:3888
server.3 = 192.168.245.130:2888:3888其中dataDir 和 server.x 需要修改,clientPort=2181端口是solr在down和upload配置文件时使用的端口
在各个主机上的zookeeper数据文件目录下创建一个myid文件,里面存放对应主机的server.x中的x数字,比如server.1 = 192.168.245.128:2888:3888,那么192.168.245.128主机上myid文件中就写1
每台机器上启动zookeeper和solr
#在solr用户下操作
cd /home/solr/proc/zookeeper-3.4.8/bin
./zkServer.sh start
./zkServer.sh status
#在root用户下操作
service solr stop
service solr start如果看到Leader或者Follower字样就表示zookeeper集群创建成功
备注:建议修改这部分设置
*** [WARN] *** Your open file limit is currently 10240.
It should be set to 65000 to avoid operational disruption.
If you no longer wish to see this warning, set SOLR_ULIMIT_CHECKS to false in your profile or solr.in.sh
*** [WARN] *** Your Max Processes Limit is currently 1024.
It should be set to 65000 to avoid operational disruption.
If you no longer wish to see this warning, set SOLR_ULIMIT_CHECKS to false in your profile or solr.in.sh
Waiting up to 180 seconds to see Solr running on port 8983 [\]
Started Solr server on port 8983 (pid=6011). Happy searching!上面的warning可以在/etc/security/limits.conf中修改打开文件数限制为
* soft nofile 65000 * hard nofile 65000
或者根据上面的建议,在solr.in.sh中设置SOLR_ULIMIT_CHECKS=false
zookeeper设置为开机启动
在上面的步骤设置完之后,每次重启虚拟机只有solr是启动了的,然后自己手工再启动zookeeper,solr是不能访问的,要求zookeeper集群先于solr集群启动,因此在设置zookeeper集群开机启动前要先查看solr开机启动的优先级
查看solr开机启动的优先级
在执行这一步操作时,有兴趣的老铁可以先看 Linux开机启动一些知识点 的一片文章,了解rcx.d文件目录的作用
cd /etc/rc3.d
ls *solr*![]()
"S50solr"分析:
S:代表启动
50:代表启动的顺序,值越小越先启动
solr:服务名字,就是/etc/init.d中的文件名
因zookeeper要先于solr启动,所以它的启动顺序对应的值应该小于50
设置zookeeper开机启动
cd /etc/init.d
touch zookeeper
vim zookeeper将下面的内容粘贴到zookeeper文件中
#!/bin/bash
#chkconfig:2345 20 90
#description:zookeeper
#processname:zookeeper
export JAVA_HOME=/home/jionsvolk/proc/jdk1.8.0_65
export ZOO_LOG_DIR=/home/solr/data/zookeeper/logs
case $1 in
start) su solr /home/solr/proc/zookeeper-3.4.8/bin/zkServer.sh start;;
stop) su solr /home/solr/proc/zookeeper-3.4.8/bin/zkServer.sh stop;;
status) su solr /home/solr/proc/zookeeper-3.4.8/bin/zkServer.sh status;;
restart) su solr /home/solr/proc/zookeeper-3.4.8/bin/zkServer.sh restart;;
*) echo "require start|stop|status|restart" ;;
esac其中chkconfig:2345 20 90非常重要
2345:为主机运行的级别,表示主机运行在2、3、4、5个级别时都会启动zookeeper,而0 、1、6级别时停止zookeeper
20:开机启动的优先级,要比solr的50大
90:关机停止的顺序
一般设置时,先启动,则后停止,注意不要把启动值设置得太小,否则可能一些系统核心服务还没有启动起来,导致你的应用无法启动
JAVA_HOME是必须的
ZOO_LOG_DIR是可选的,用于保存zookeeper启动时的日志文件,我把它指定到了自定义目录,否则你得使用root用户启动zookeeper或者给root用户根目录的写权限授予给zookeeper的启动用户
chmod +x zookeeper启动zookeeper
service zookeeper start设置为开机启动
chkconfig --add zookeeper然后去/etc/rc3.d中查看zookeeper的启动顺序

查看zookeeper的停止顺序
![]()
重启主机,验证solr的浏览器控制台是否可以访问
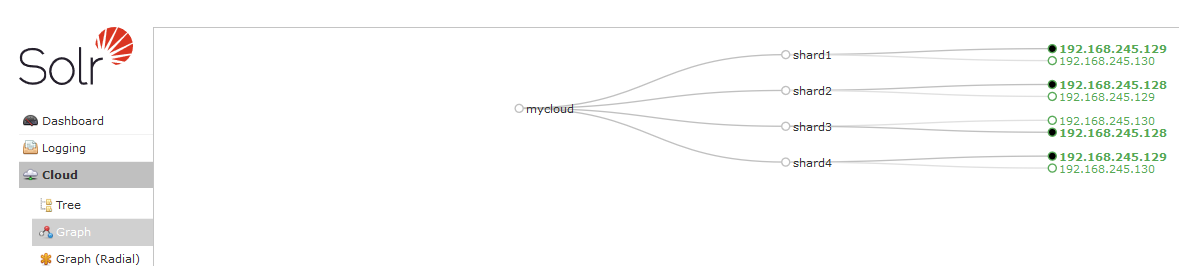
2. 创建mycloud连接
./solr create -c mycloud -n mycloud -shards 4 -replicationFactor 2 -p 8983在8983这个solr实例上创建一个连接mycloud,有四个shards(分片) ,每个shards有两个replicationFactor(复制品)
3. 在浏览器查看新建连接情况
可以看到下图
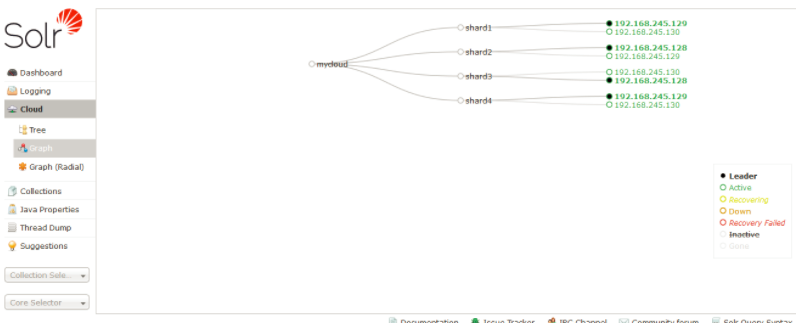
还可以点击tree,查看zookeeper中的关于solr的配置信息,这些配置信息是从默认的配置文件目录中读取的
/home/solr/proc/solr/solr-7.3.0/server/solr/configsets/_default4. 创建自己配置文件目录
4.1 导出配置
./solr zk downconfig -z 192.168.245.130:2181 -n mycloud -d /home/solr/proc/solr/solr-7.3.0/myconfig/mycloud/conf到对应目录下查看已导出的文件,只需要在一台机器上导出来,修改再上传即可

4.2 修改配置(添加中文分词器)
例如在managed-schema.xml(solr云的配置文件)或者schema.xml(单实例solr的配置文件)里面添加中文分词器mmseg4j或者ik-analyzer
<fieldtype name="textComplex" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<!--
中文分词器 其中dicPath是指定自定义分词的目录
1.默认目录为启动命令所在目录下的data/wordsxxx.dic文件
2.绝对路径下的wordsxxx.dic文件
3.solr_home下的wordsxxx.dic文件
-->
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="/home/solr/proc/solr/solr-7.3.0/myconfig/mycloud/conf"/>
</analyzer>
</fieldtype>
<fieldtype name="textMaxWord" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" />
</analyzer>
</fieldtype>
<fieldtype name="textSimple" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple"/>
</analyzer>
</fieldtype>
<!-- myname是document对象中的字段名,表示doc中myname使用textComplex字段类型,该类型使用mmseg4j中文分词器,indexed=true 表示需要建立索引 stored=true 表示需要存储到索引文件中 -->
<field name="myname" type="textComplex" indexed="true" stored="true"></field>增加了中文分词器,一定要将相应的jar包上传到solr_install_home下的server/solr-webapp/webapp/WEB-INF/lib目录中,比如我添加的是mmseg4j分词器,那么需要将mmseg4j-core-1.10.0.jar和mmseg4j-solr-2.4.0.jar添加该目录中
注:中文分词器跟不上solr的更新速度,所以使用的时候最好去对应的分词器官博或者githup上看看适配情况,比如mmseg4j的githup上目前适配到的solr最高版本为6.3.0(经过测试目前的7.3.0也是支持的)。
地址:https://github.com/chenlb/mmseg4j-solr
对schema.xml的所有配置可以参考官方文档https://lucene.apache.org/solr/guide/7_3/documents-fields-and-schema-design.html,里面非常有用的CopyingField和DynamicField等等
在solrconfig.xml中添加中文分词器动态加载handler
<requestHandler name="/mmseg4j/reloadwords" class="com.chenlb.mmseg4j.solr.MMseg4jHandler">
<lst name="defaults">
<!-- 如果solrcloud是多台机器需要注意相同的配置目录 -->
<str name="dicPath">/home/solr/proc/solr/solr-7.3.0/myconfig/mycloud/conf</str>
<str name="check">true</str>
<str name="reload">true</str>
</lst>
</requestHandler>需要重启solr
service solr stop
service solr start
4.3 重新加载配置
可以通过浏览器控制页面查看重新加载前的配置文件内容
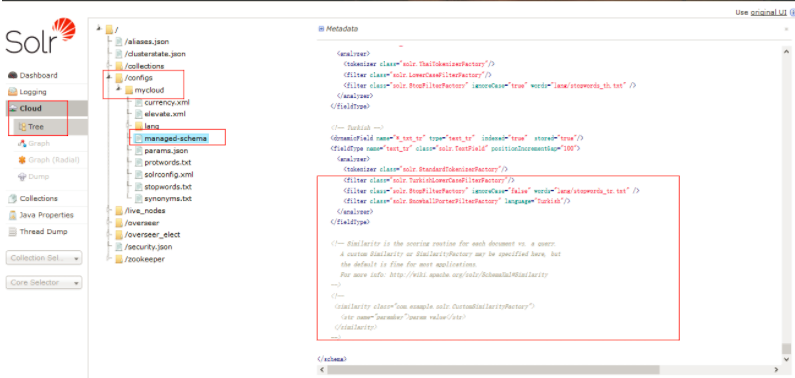
执行命令重新加载文件
./solr zk upconfig -z 192.168.245.130:2181 -n mycloud -d /home/solr/proc/solr/solr-7.3.0/myconfig/mycloud/conf
在浏览器中重新查看配置文件是否有变化
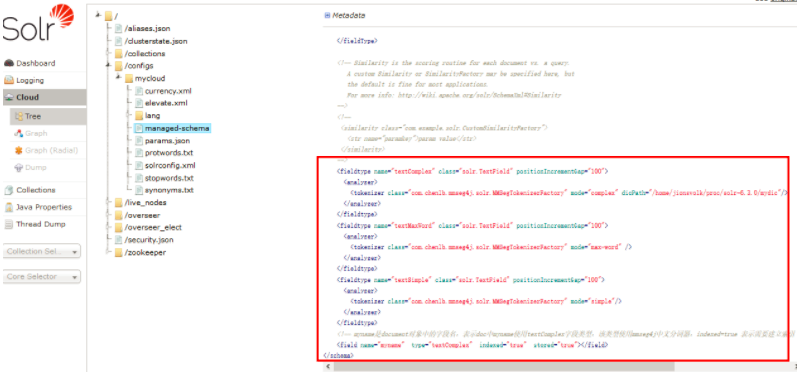
可以看到中文分词器的设置已经加载成功
写一段代码测试中文分词器
@Test
public void test3() throws Exception {
final String solrUrl = "http://192.168.245.130:8983/solr/mycloud";
HttpSolrClient client = new HttpSolrClient(solrUrl);
FieldAnalysisRequest request = new FieldAnalysisRequest();
request.addFieldName("myname");// 字段名,随便指定一个支持中文分词的字段
request.setFieldValue("");// 字段值,可以为空字符串,但是需要显式指定此参数
request.setQuery("可以看到中文分词器的设置已经加载成功");
FieldAnalysisResponse response = request.process(client);
Iterator<AnalysisPhase> it = response.getFieldNameAnalysis("myname").getQueryPhases().iterator();
while(it.hasNext()) {
AnalysisPhase pharse = (AnalysisPhase)it.next();
List<TokenInfo> list = pharse.getTokens();
for (TokenInfo info : list) {
System.out.println(info.getText());
}
}
}输出结果:

分词结果中没有“分词器”这个词语,可以使用mmseg4j的自定义分词功能
Dictionary.java中的loadDic方法部分内容
File[] words = listWordsFiles(); //只要 wordsXXX.dic的文件
if(words != null) { //扩展词库目录
for(File wordsFile : words) {
loadWord(new FileInputStream(wordsFile), dic, wordsFile);
addLastTime(wordsFile); //用于检测是否修改
}
}所以/home/solr/proc/solr/solr/mydic创建一个words_1.dic,里面添加"分词器"三个字,一个词一行
动态加载分词
使用curl在执行语句,一台物理机有一条语句即可,不需要每个shard-replica都要照顾到:
其中mycloud_shard1_replica1的规则是:连接名称-shard名称-replica名称,参考下图中粗框圈出来的内容
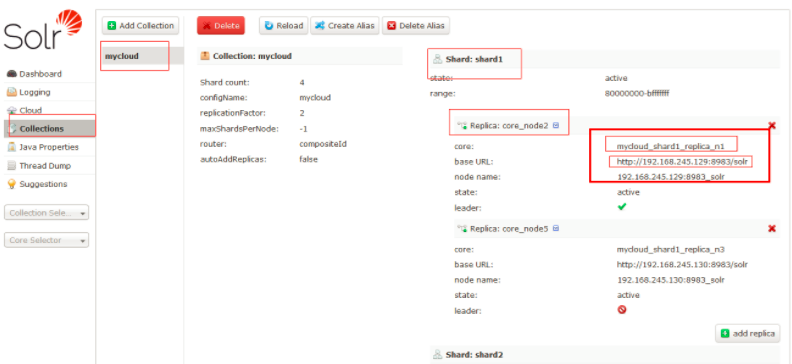
curl 'http://192.168.245.129:8983/solr/mycloud_shard1_replica1/mmseg4j/reloadwords?wt=json'
curl 'http://192.168.245.130:8983/solr/mycloud_shard1_replica3/mmseg4j/reloadwords?wt=json'
curl 'http://192.168.245.128:8983/solr/mycloud_shard2_replica4/mmseg4j/reloadwords?wt=json'
最好在到主机上执行一次该命令,让自定义分词立即生效
curl 'http://192.168.245.128:8983/solr/admin/collections?action=RELOAD&name=mycloud'
再验证结果:
5. 测试集群
连接192.168.245.128,使用solrj客户端API将数据添加到集群中
测试代码:
public void test2() throws Exception {
final String solrUrl = "http://192.168.245.128:8983/solr";
HttpSolrClient client = new HttpSolrClient(solrUrl);
final SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", UUID.randomUUID().toString());
doc.addField("myname", "梅西又当爹了,儿子还叫C罗");
final UpdateResponse updateResponse = client.add("mycloud", doc);
//NamedList<?> ns = updateResponse.getResponse();
// Indexed documents must be committed
client.commit("mycloud");
}
连接192.168.245.130,使用浏览器查询数据
http://192.168.245.130:8983/solr/mycloud/select?q=*:*
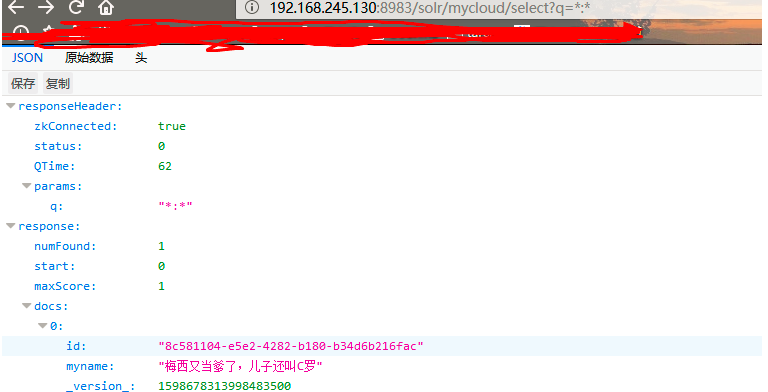
请C罗球迷不要多想
连接192.168.245.129,使用浏览器查询数据
http://192.168.245.129:8983/solr/mycloud/select?q=*:*

请C罗球迷不要多想
从测试结果看,无论 连接那台机器,查询的结果都是一致的
6. 从数据库中导入索引
6.1 配置数据导入处理器
在solrconfig.xml最后添加如下配置
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<!-- 数据源配置文件名自定义 -->
<str name="config">mysql_db_import_config.xml</str>
</lst>
</requestHandler>
6.2 配置数据源
配置mysql_db_import_config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://192.168.245.1:3306/study" user="root" password="12340101"/>
<document>
<entity name="account" query="select * from account">
<field column="acct_id" name="acct_id_i" />
<field column="acct_name" name="acct_name_t" />
<field column="cust_id" name="cust_id_i" />
</entity>
</document>
</dataConfig>其中的acct_id_id规则是xxxx_xx_i,其实就是manage-schema中的动态属性dynamicField,如:
<dynamicField name="*_i" type="pint" indexed="true" stored="true"/>这是solr默认给我们配置的一些可用属性
重要1:将solr_home/dist/下的solr-dataimporthandler-7.3.0.jar复制到solr_home/server/solr-webapp/webapp/WEB-INF/lib目录下
重要2:将修改后的配置文件上传到集群中一台主机,然后执行配置上传命令
重要3:重启solr,如果有报错的话,把zookeeper和solr先后重启一遍
6.3 在浏览器控制台导入数据
打开浏览器控制台
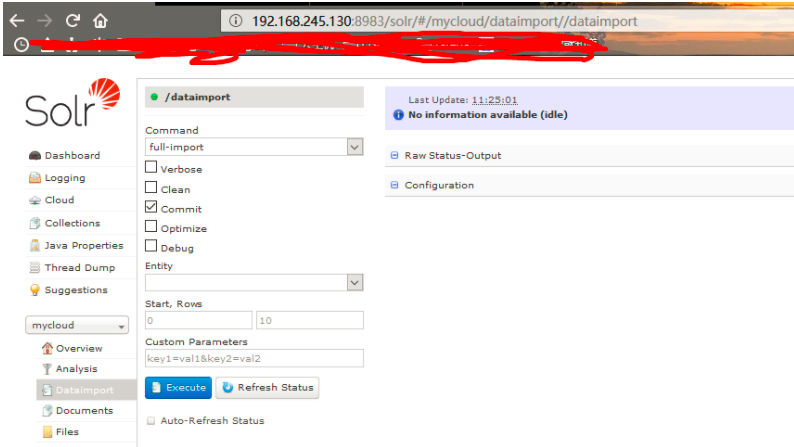
点击“Execute”

或者使用curl执行
curl "http://192.168.245.130:8983/solr/dataimport?command=full-import&clean=true&offset=0&length=10000&indent=on"
执行到这一步的时候可能会失败:比如你数据库配置有误,或者网络不通、防火墙没有关闭、MYSQL的非本机访问没有打开之类的问题。
在实际生产中,自己用solrj简单写一个框架(比如像mybatis配合jpa所采用的方式)来导入数据库中的各种表比上面的方式更方便灵活
7. 在Tomcat中启动solr(此部分是转载)
创建目录
[root@node004 ]# mkdir -p /usr/local/solrCloud
复制单节点
[root@node004 ~]# cp /usr/local/solr /usr/local/solrCloud/solr1 -rf
[root@node004 ~]# cp /usr/local/solr /usr/local/solrCloud/solr2 -rf
[root@node004 ~]# cp /usr/local/solr /usr/local/solrCloud/solr3 -rf
[root@node004 ~]# cp /usr/local/solr /usr/local/solrCloud/solr4 -rf
注意:删除每个solrhome实例目录下的core.properties
[root@node004 ~]# rm /usr/local/solrCloud/solr1/home/jonychen/core.properties -rf[root@node004 ~]# rm /usr/local/solrCloud/solr2/home/jonychen/core.properties -rf[root@node004 ~]# rm /usr/local/solrCloud/solr3/home/jonychen/core.properties -rf[root@node004 ~]# rm /usr/local/solrCloud/solr4/home/jonychen/core.properties -rf
solr中的配置文件
solr.xml
[root@node004 ~]# vi /usr/local/solrCloud/solr1/home/solr.xml
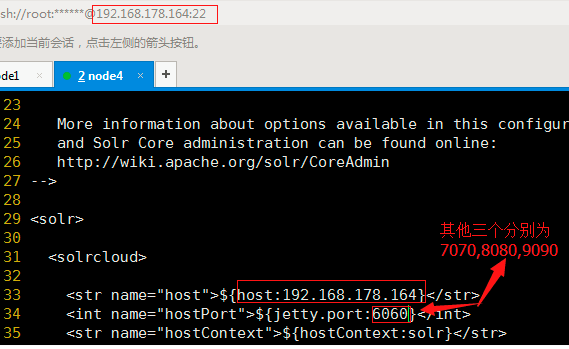
[root@node004 ~]# vi /usr/local/solrCloud/solr2/home/solr.xml [root@node004 ~]# vi /usr/local/solrCloud/solr3/home/solr.xml [root@node004 ~]# vi /usr/local/solrCloud/solr4/home/solr.xml
tomcat中的配置文件
server.xml
[root@node004 ~]# vi /usr/local/solrCloud/solr1/apache-tomcat-8.5.24/conf/server.xml

[root@node004 ~]# vi /usr/local/solrCloud/solr2/apache-tomcat-8.5.24/conf/server.xml [root@node004 ~]# vi /usr/local/solrCloud/solr3/apache-tomcat-8.5.24/conf/server.xml [root@node004 ~]# vi /usr/local/solrCloud/solr4/apache-tomcat-8.5.24/conf/server.xml
web.xml
[root@node004 ~]# vi /usr/local/solrCloud/solr1/apache-tomcat-8.5.24/webapps/solr/WEB-INF/web.xml

[root@node004 ~]# vi /usr/local/solrCloud/solr2/apache-tomcat-8.5.24/webapps/solr/WEB-INF/web.xml [root@node004 ~]# vi /usr/local/solrCloud/solr3/apache-tomcat-8.5.24/webapps/solr/WEB-INF/web.xml [root@node004 ~]# vi /usr/local/solrCloud/solr4/apache-tomcat-8.5.24/webapps/solr/WEB-INF/web.xml
catalina.sh
[root@node004 ~]# vi /usr/local/solrCloud/solr1/apache-tomcat-8.5.24/bin/catalina.sh

[root@node004 ~]# vi /usr/local/solrCloud/solr2/apache-tomcat-8.5.24/bin/catalina.sh [root@node004 ~]# vi /usr/local/solrCloud/solr3/apache-tomcat-8.5.24/bin/catalina.sh [root@node004 ~]# vi /usr/local/solrCloud/solr4/apache-tomcat-8.5.24/bin/catalina.sh
上传配置文件至zookeeper
调用solr解压目录zkCli.sh上传配置文件
[root@node004 ~]# cd /root/solr-7.2.0/server/scripts/cloud-scripts/ [root@node004 cloud-scripts]# ls log4j.properties snapshotscli.sh zkcli.bat zkcli.sh [root@node004 cloud-scripts]# ./zkcli.sh -zkhost 192.168.178.161:2181,192.168.178.161:2182,192.168.178.161:2183 -cmd upconfig -confdir /usr/local/s olrCloud/solr1/home/jonychen/conf/ -confname jonychen
查看是否上传成功
[root@node001 ~]# /usr/local/zkCluster/zk1/bin/zkServer.sh statusZooKeeper JMX enabled by defaultUsing config: /usr/local/zkCluster/zk1/bin/../conf/zoo.cfgMode: follower[root@node001 ~]# /usr/local/zkCluster/zk1/bin/zkCli.sh

有configs则说明上传成功
[zk: localhost:2181(CONNECTED) 1] quitQuitting...
启动4个tomcat
为方便查看日志,复制四个窗口进行操作,分别切换到各自对应的目录
[root@node004 ~]# cd /usr/local/solrCloud/solr1[root@node004 solr1]# lsapache-tomcat-8.5.24 home logs[root@node004 solr1]# ./apache-tomcat-8.5.24/bin/startup.sh && tailf ./apache-tomcat-8.5.24/logs/catalina.out
启动成功界面
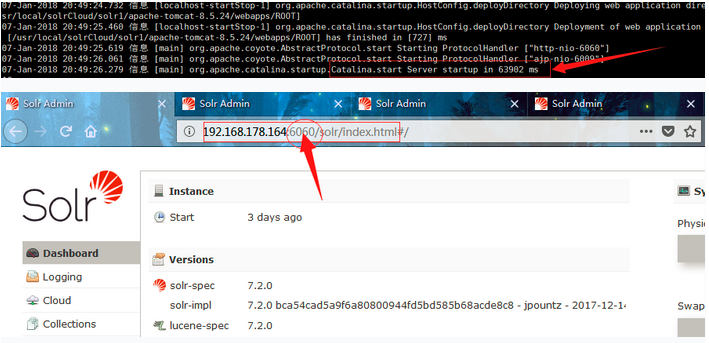
创建集群
可以使用浏览器控制台,也可以在后台使用./solr create 命令创建















 270
270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









