







APK解析是很久以前想完成的一件事,但是因为一些事情搁下了。
当时使用Iteedee的代码在200多个APK文件中有将近四分之一的文件是无法成功解析AXML的。Iteedee下称I
因此,本文的代码基于I的代码修改,效果基本接近于APKTOOL(https://code.google.com/p/android-apktool/)
毋庸置疑的是,在解析的时候,会遇到各种奇葩的编码问题,首先会遇到文件的压缩解压缩码流问题,不得不说SharpZip的性能还是可以的,注意APK使用的Zip压缩格式是非固实压缩,虽然压缩性能(Performance of Compression ,BenchMark)降低了,但是对于文件寻址来说还是很方便的。
常用的APK解析读取APK信息的方法有很多种:
1、AAPT工具、2、apkTool工具、3、AXMLPrinter2工具、4、自带ZIP解压引擎纯字节流解码分析、5、其它...
这里要讲的就是第四种,是基于开源库SharpZipLib的。
下面言归正传,谈谈个中遇到的一些问题:
1、关于怎么解压zip可以看这个问题的某层回答:
http://bbs.csdn.net/topics/390421494
注意GZip和Zip不一样,Gzip在HTTP请求中比较常见
使用到的sharp库到如下网站去找
http://icsharpcode.github.io/SharpZipLib/
2、zip版本问题(788):
大部分文件的解压版本都是0x14,而个别文件出现0x0314,因此抛出了异常,具体原因无法考究,解决方案是在SharpZipLib源码中加入代码过滤掉,影响应该不大:
if (extractVersion==788)
{
extractVersion &= 0xff;
}记得备案,免得那天遇到问题了不知道这一茬。
3、文本编码问题:
从I那儿下载的代码经过测试后还是存在不少问题的,这里说的文本编码就是一个典型的例子。
I使用的是UTF8编码格式进行转码
通过 http://tool.chinaz.com/Tools/URLEncode.aspx 查了下"赶集"两字的UTF8的码流形式为:%e8%b5%b6%e9%9b%86 .
然而,把解析之前的AndroidManifest.xml在程序里dump出来发现实际上是这样的:
![]()
那么问题就来了,通过http://tool.chinaz.com/Tools/Unicode.aspx 查了一下unicode码流(unicode的编码据说没有一个统一的标准,所以才出现了UTF8\16\32等编码),给出的结果是:\u8d76\u96c6\u7b80\u6613\u5730\u56fe。
原因真的就找到了吗,有时候人真的是聪明反被聪明误啊,博主考虑了大小端的问题,于是字节换序、去00字节、重返UTF8(为什么再使用UTF8也是基于很多原因)各种方法试过皆无果之后,探究了下Unicode编码在c#中实现的具体码流:
byte[] bytes = Encoding.Unicode.GetBytes(textBox1.Text);
for (int ii = 0; ii < bytes.Length; ii++)
{
textBox2.Text += string.Format("{0:x2} ", bytes[ii]);
}结果如下:
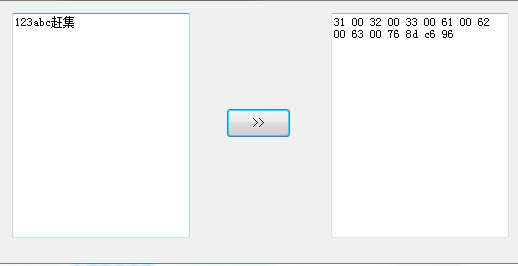
显然字序跟AXML中的是一模一样,注意00字节,可见AXML和c#中的unicode都使用了双字节对齐的(这不废话么),那么修复了编码Bug之后的某个子函数是这样的:
private String compXmlStringAt(byte[] arr, int strOff)
{
int strLen = arr[strOff + 1] << 8 & 0xff00 | arr[strOff] & 0xff;
byte[] chars = new byte[strLen<<=1 ];
for (int ii = 0; ii < strLen ; ii++)
{
chars[ii] = arr[strOff + 2 + ii];
}
return Encoding.Unicode.GetString(chars);//Change to Unicode of Encoding by Parser7
}如此而来,就成功支持了中文/多语言了。然而让我郁闷的是,通篇的注释都在说Unicode,只字未提UTF8,代码的原作者居然赫然在目地写着错误的代码,令人费解的注释
4、TEXT事件类型的处理:
I写的代码,只对startTag之类的事件做了处理,然而XmlPullParser使用了五类事件,但是I对未知事件的处理是直接break了,这样会造成manifest等元素在流中未关闭的问题,严重的致命/FATOL ERROR。
由于此处对TEXT内容并不关心,所以使用对offset简单处理防止死循环的方法跳过。后面有空了再来细细研究这个东西。有需要的朋友可以一起交流下。
XmlPullParser的源码我估计可能就在这个网站http://www.xmlpull.org/ ,找到的记得发我一份,先谢谢了。
相关资料:
http://blog.csdn.net/andyhuabing/article/details/8036340
5、size=0问题导致无法正确读到androidmanifest.xml:
I使用了如下的方法遍历每一个压缩包中的文件
while ((item = zip.GetNextEntry()) != null)
{...}在某个APK的解析中发现出现size=0导致未能成功读取androidmanifest.xml文件。
跟踪了size读写器所有的过程后,发现在ZipFile构造函数中已经能够获得所有的ZipEntry,而I的代码这里调用GetNextEntry方法显然不仅是画蛇添足而且还引入了Bug,废话少说,使用迭代器轻松搞定:
PZipFile = new ZipFile(fsStream);
foreach (ZipEntry entry in PZipFile )
{ ... }小结:
至此,已经能成功解析1021个文件的AXML,但还有35个文件不能成功解析。
经检验,有21个文件已经损坏,但还有14个文件可以成功打开压缩包,具体原因还在分析中。
6、XmlException抛出的EntityName解析错误:并指出在35行51列
I的代码似乎没有实现将decompressXML之后的result转为XMLDocument,这里是我自己加了相应的代码,但是却出现这样的问题。
dump出解析的xml内容后发现在指定位置出现了xml非法字符'&',将非法字符转义处理就行了。
下面就是很直接、赤裸裸的代码了:
public static string HandleInvalidCharAtXMLDoc(string filename)
{
return filename.Replace("<", "<").Replace(">", ">").Replace("&", "&").Replace("'", "'").Replace("\"", """);
}7、压缩包签名头问题:
apktool解不开,winrar能看到目录结构,从压缩档中拖拽文件貌似可以解压AXML,但是会提示文件损坏,将解压出来的AXML文件放入成功解析的APK后能正确解析出AXML明文内容。
经过一些实验后,发现dump出来的字节流跟能解析出来的字节流不一样,说明可能是entry索引出了问题,或者内容被破坏了。根据上文描述,明显问题出在entry索引问题,或者是其它问题(不是788等版本问题)















 1229
1229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









