






在前⾯的章节中,我们了解到⼀个PHP⽂件在服务器端的执⾏过程包括以下两个⼤的过程:
1. 递给php程序需要执⾏的⽂件, php程序完成基本的准备⼯作后启动PHP及Zend引擎, 加载注册的扩展模块。
2. 初始化完成后读取脚本⽂件,Zend引擎对脚本⽂件进⾏词法分析,语法分析。然后编译成opcode执⾏。 如果安装了apc之类的opcode缓存, 编译环节可能会被跳过⽽直接从缓存中读取opcode执⾏。
在第⼆步中,词法分析、语法分析,编译中间代码,执⾏中间代码等各个部分统称为Zend虚拟机。 与Java、C#等编译型语⾔相⽐,PHP少了⼀个⼿动编译的过程,它们⽆需编译即可运⾏,我们称其为解释性语⾔。 Java有⾃⼰的Java虚拟机,它在多个平台上实现统⼀语⾔; C#有⾃⼰的.NET虚拟机,它在单⼀平
台实现多种语⾔; PHP跟他们⼀样,也有属于⾃⼰的Zend虚拟机。它们在本质是相同的,它们都是抽象的计算机。 这些虚拟机都是在某种较底层的语⾔上抽象出另外⼀种语⾔,有⾃⼰的指令集,有⾃⼰的内存管理体系。 它们最终都会将抽象级别较⾼的语⾔实现转化为抽象级别较低的语⾔实现, 并且实现其它辅助功
能,如内存管理,垃圾回收等机制, 以减少程序员在具体实现上的⼯作,从⽽可以将更多的时间和精⼒投⼊到业务逻辑中。 从抽象层次看,Zend虚拟机⽐Java等语⾔更⾼级⼀些,这⾥的⾼级不是说功能更强⼤或效率更⾼, 简单点说,Zend虚拟机离真正的机器实现更远⼀些。 最近这些年,语⾔的发展只是不断的抽象,不断的远离机器,没有根本性的变化。
本章,我们从虚拟机的前世今⽣讲起,叙述Zend虚拟机的实现原理,关键的数据结构, 并其中穿插⼀个关于语法实现的⽰例和源码加密解密的过程说明。
第⼀节 Zend虚拟机概述
在wiki中虚拟机的定义是: 虚拟机(Virtual Machine),在计算机科学中的体系结构⾥,是指⼀种特殊的软件, 他可以在计算机平台和终端⽤户之间创建⼀种环境,⽽终端⽤户则是基于这个软件所创建的环境来操作软件。 在计算机科学中,虚拟机是指可以像真实机器⼀样运⾏程序的计算机的软件实现。
虚拟机是⼀种抽象的计算机,它有⾃⼰的指令集,有⾃⼰的内存管理体系。 在此类虚拟机上实现的语⾔⽐较低抽象层次的语⾔更加明了,更加简单易学。
Zend虚拟机核⼼实现代码
为了⽅便读者对Zend引擎的实现有个全⾯的感觉,下⾯列出涉及到Zend引擎实现的核⼼代码⽂件功能参考。
Zend引擎的核⼼⽂件都在$PHP_SRC/Zend/⽬录下⾯。不过最为核⼼的⽂件只有如下⼏个:
1. PHP语法实现
- Zend/zend_language_scanner.l
- Zend/zend_language_parser.y
2. Opcode编译
- Zend/zend_compile.c
3. 执⾏引擎
- Zend/zend_vm_*
- Zend/zend_execute.c
Zend虚拟机体系结构
从概念层将Zend虚拟机的实现进⾏抽象,我们可以将Zend虚拟机的体系结构分为:解释层、执⾏引擎、中间数据层,如图7.1所⽰:
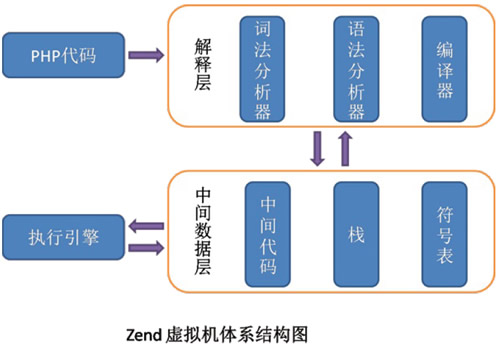
图7.1 Zend虚拟机体系结构图
当⼀段PHP代码进⼊Zend虚拟机,它会被执⾏两步操作:编译和执⾏。 对于⼀个解释性语⾔来说,这是⼀个创造性的举动,但是,现在的实现并不彻底。 现在当PHP代码进⼊Zend虚拟机后,它虽然会被执⾏这两步操作,但是这两步操作对于⼀个常规的执⾏过程来说却是连续的, 也就是说它并没有转变成和Java
这种编译型语⾔⼀样:⽣成⼀个中间⽂件存放编译后的结果。 如果每次执⾏这样的操作,对于PHP脚本的性能来说是⼀个极⼤的损失。 虽然有类似于APC,eAccelerator等缓存解决⽅案。但是其本质上是没有变化的,并且不能将两个步骤分离,各⾃发展壮⼤。
解释层
解释层是Zend虚拟机执⾏编译过程的位置。它包括词法解析、语法解析和编译⽣成中间代码三个部分。 词法分析就是将我们要执⾏的PHP源⽂件,去掉空格,去掉注释,切分为⼀个个的标记(token), 并且处理程序的层级结构(hierarchical structure)。
语法分析就是将接受的标记(token)序列,根据定义的语法规则,来执⾏⼀些动作,Zend虚拟机现在使⽤的Bison使⽤巴科斯范式(BNF)来描述语法。 编译⽣成中间代码是根据语法解析的结果对照Zend虚拟机制定的opcode⽣成中间代码, 在PHP5.3.1中,Zend虚拟机⽀持135条指令(见
Zend/zend_vm_opcodes.h⽂件), ⽆论是简单的输出语句还是程序复杂的递归调⽤,Zend虚拟机最终都会将所有我们编写的PHP代码转化成这135条指令的序列, 之后在执⾏引擎中按顺序执⾏。
中间数据层
当Zend虚拟机执⾏⼀个PHP代码时,它需要内存来存储许多东⻄, ⽐如,中间代码,PHP⾃带的函数列表,⽤户定义的函数列表,PHP⾃带的类,⽤户⾃定义的类, 常量,程序创建的对象,传递给函数或⽅法的参数,返回值,局部变量以及⼀些运算的中间结果等。 我们把这些所有的存放数据的地⽅称为中间数据层。
如果PHP以mod扩展的⽅式依附于Apache2服务器运⾏,中间数据层的部分数据可能会被多个线程共享,如果PHP⾃带的函数列表等。 如果只考虑单个进程的⽅式,当⼀个进程被创建时它就会被加载PHP⾃带的各种函数列表,类列表,常量列表等。 当解释层将PHP代码编译完成后,各种⽤户⾃定义的函数,类
或常量会添加到之前的列表中, 只是这些函数在其⾃⾝的结构中某些字段的赋值是不⼀样的。
当执⾏引擎执⾏⽣成的中间代码时,会在Zend虚拟机的栈中添加⼀个新的执⾏中间数据结构(zend_execute_data), 它包括当前执⾏过程的活动符号列表的快照、⼀些局部变量等。
执⾏引擎
Zend虚拟机的执⾏引擎是⼀个⾮常简单的实现,它只是依据中间代码序列(EX(opline)),⼀步⼀步调⽤对应的⽅法执⾏。 在执⾏引擎中没并有类似于PC寄存器⼀样的变量存放下⼀条指令,当Zend虚拟机执⾏到某条指令时,当它所有的任务都执⾏完了, 这条指令会⾃⼰调⽤下⼀条指令,即将序列的指针向前移动⼀个位置,从⽽执⾏下⼀条指令,并且在最后执⾏return语句,如此反复。 这在本质上是⼀个函数嵌套调⽤。
回到开头的问题,PHP通过词法分析、语法分析和中间代码⽣成三个步骤后,PHP⽂件就会被解析成PHP的中间代码opcode。 ⽣成的中间代码与实际的PHP代码之间并没有完全的⼀⼀对应关系。只是针对⽤户所给的PHP代码和PHP的语法规则和⼀些内部约定⽣成中间代码, 并且这些中间代码还需要依靠⼀些全局变量中转数据和关联。⾄于⽣成的中间代码的执⾏过程是依据中间代码的顺利, 依赖于执⾏过程中的全局变量,⼀步步执⾏。当然,在遇到⼀些函数跳转也会发⽣偏移,但是最终还是会回到偏移点。
第⼆节 语法的实现
世上没有⽆缘⽆故的爱,也没有⽆缘⽆故的恨。
语⾔从⼴义上来讲是⼈们进⾏沟通交流的各种表达符号。每种语⾔都有专属于⾃⼰的符号,表达⽅式和规则。 就编程语⾔来说,它也是由特定的符号,特定的表达⽅式和规则组成。 语⾔的作⽤是沟通,不管是⾃然语⾔,还是编程语⾔,它们的区别在于⾃然语⾔是⼈与⼈之间沟通的⼯具, ⽽编程语⾔是⼈与机器
之间的沟通渠道。相对于⾃然语⾔,编程语⾔的历史还⾮常短, 虽然编程语⾔是站在历史巨⼈的基础上创建的,但是它还很⼩,还是⼀个⼩孩。 它只能按编程⼈员所给的指令翻译成对应的机器可以识别的语⾔。它就相当于⼀个转化⼯具, 将⼈们的知识或者业务逻辑转化成机器码(机器的语⾔),让其执⾏对应的的
操作。 ⽽这些指令是⼀些规则,⼀些约定,这些规则约定都是由编程语⾔来处理。
就PHP语⾔来说,它也是⼀组符合⼀定规则的约定的指令。 在编程⼈员将⾃⼰的想法以PHP语⾔实现后,通过PHP的虚拟机将这些PHP指令转变成C语⾔ (可以理解为更底层的⼀种指令集)指令,⽽C语⾔⼜会转变成汇编语⾔, 最后汇编语⾔将根据处理器的规则转变成机器码执⾏。这是⼀个更⾼层次抽象的不断具体化,不断细化的过程。
在这⼀章,我们讨论PHP虚拟机是如何将PHP语⾔转化成C语⾔。 从⼀种语⾔到另⼀种语⾔的转化称之为编译,这两种语⾔分别可以称之为源语⾔和⽬标语⾔。 这种编译过程通过发⽣在⽬标语⾔⽐源语⾔更低级(或者说更底层)。 语⾔转化的编译过程是由编译器来完成, 编码器通常被分为⼀系列的过程:词法分析、语法分析、语义分析、中间代码⽣成、代码优化、⽬标代码⽣成等。 前⾯⼏个阶段(词法分析、语法分析和语义分析)的作⽤是分析源程序,我们可以称之为编译器的前端。 后⾯的⼏个阶段(中间代码⽣成、代码优化和⽬标代码⽣成)的作⽤是构造⽬标程序,我们可以称之为编译器的后端。 ⼀种语⾔被称为
编译类语⾔,⼀般是由于在程序执⾏之前有⼀个翻译的过程, 其中关键点是有⼀个形式上完全不同的等价程序⽣成。 ⽽PHP之所以被称为解释类语⾔,就是因为并没有这样的⼀个程序⽣成, 它⽣成的是中间代码,这只是PHP的⼀种内部数据结构。
在本章我们会介绍PHP编译器的前端的两个阶段,语法分析、语法分析;后端的⼀个阶段,中间代码⽣成。 在第⼀节我们介绍PHP的词法分析过程及其⽤到的⼯具re2c, 第⼆节我们介绍在词法分析后的语法分析过程, 第三节我们以PHP的⼀个简单语法实现作为本章的结束。
词法解析
在前⾯我们提到语⾔转化的编译过程⼀般分为词法分析、语法分析、语义分析、中间代码⽣成、代码优化、⽬标代码⽣成等六个阶段。 不管是编译型语⾔还是解释型语⾔,扫描(词法分析)总是将程序转化成⽬标语⾔的第⼀步。 词法分析的作⽤就是将整个源程序分解成⼀个⼀个的单词, 这样做可以在⼀定程度
上减少后⾯分析⼯作需要处理的个体数量,为语法分析等做准备。 除了拆分⼯作,更多的时候它还承担着清洗源程序的过程,⽐如清除空格,清除注释等。 词法分析作为编译过程的第⼀步,在业界已经有多种成熟⼯具,如PHP在开始使⽤的是Flex,之后改为re2c, MySQL的词法分析使⽤的Flex,除此之外还有作为
UNIX系统标准词法分析器的Lex等。 这些⼯具都会读进⼀个代表词法分析器规则的输⼊字符串流,然后输出以C语⾔实做的词法分析器源代码。 这⾥我们只介绍PHP的现版词法分析器,re2c。
re2c是⼀个扫描器制作⼯具,可以创建⾮常快速灵活的扫描器。 它可以产⽣⾼效代码,基于C语⾔,可以⽀持C/C++代码。与其它类似的扫描器不同, 它偏重于为正则表达式产⽣⾼效代码(和他的名字⼀样)。因此,这⽐传统的词法分析器有更⼴泛的应⽤范围。 你可以在sourceforge.net获取源码。
PHP在最开始的词法解析器是使⽤的是Flex,后来改为使⽤re2c。 在源码⽬录下的Zend/zend_language_scanner.l ⽂件是re2c的规则⽂件, 如果需要修改该规则⽂件需要安装re2c才能重新编译,⽣成新的规则⽂件。
re2c调⽤⽅式:
re2c [-bdefFghisuvVw1] [-o output] [-c [-t header]] file
我们通过⼀个简单的例⼦来看下re2c。如下是⼀个简单的扫描器,它的作⽤是判断所给的字符串是数字/⼩写字⺟/⼤⼩字⺟。 当然,这⾥没有做⼀些输⼊错误判断等异常操作处理。⽰例如下:
#include <stdio.h> char *scan(char *p){ #define YYCTYPE char #define YYCURSOR p #define YYLIMIT p #define YYMARKER q #define YYFILL(n) /*!re2c [0-9]+ {return "number";} [a-z]+ {return "lower";} [A-Z]+ {return "upper";} [^] {return "unkown";} */ } int main(int argc, char* argv[]) { printf("%s\n", scan(argv[1])); return 0; }
如果你是在ubuntu环境下,可以执⾏下⾯的命令⽣成可执⾏⽂件。
re2c -o a.c a.l gcc a.c -o a chmod +x a ./a 1000
此时程序会输出number。
我们解释⼀下我们⽤到的⼏个re2c约定的宏。
- YYCTYPE ⽤于保存输⼊符号的类型,通常为char型和unsigned char型
- YYCURSOR 指向当前输⼊标记, -当开始时,它指向当前标记的第⼀个字符,当结束时,它指向下⼀个标记的第⼀个字符
- YYFILL(n) 当⽣成的代码需要重新加载缓存的标记时,则会调⽤YYFILL(n)。
- YYLIMIT 缓存的最后⼀个字符,⽣成的代码会反复⽐较YYCURSOR和YYLIMIT,以确定是否需要重新填充缓冲区。
参照如上⼏个标识的说明,可以较清楚的理解⽣成的a.c⽂件,当然,re2c不会仅仅只有上⾯代码所显⽰的标记, 这只是⼀个简单⽰例,更多的标识说明和帮助信息请移步 re2c帮助⽂档:http://re2c.org/manual.html。
我们回过头来看PHP的词法规则⽂件zend_language_scanner.l。 你会发现前⾯的简单⽰例与它最⼤的区别在于每个规则前⾯都会有⼀个条件表达式。
NOTE re2c中条件表达式相关的宏为YYSETCONDITION和YYGETCONDITION,分别表⽰设置条件范围和获取条件范围。 在PHP的词法规则中共有10种,其全部在zend_language_scanner_def.h⽂件中。此⽂件并⾮⼿写, ⽽是re2c⾃动⽣成的。如果需要⽣成和使⽤条件表达式,在编译成c时需要添加-c 和-t参数。
在PHP的词法解析中,它有⼀个全局变量:language_scanner_globals,此变量为⼀结构体,记录当前re2c解析的状态,⽂件信息,解析过程信息等。 它在zend_language_scanner.l⽂件中直接定义如下:
#ifdef ZTS ZEND_API ts_rsrc_id language_scanner_globals_id; #else ZEND_API zend_php_scanner_globals language_scanner_globals; #endif
在zend_language_scanner.l⽂件中写的C代码在使⽤re2c⽣成C代码时会直接复制到新⽣成的C代码⽂件中。 这个变量贯穿了PHP词法解析的全过程,并且⼀些re2c的实现也依赖于此, ⽐如前⾯说到的条件表达式的存储及获取,就需要此变量的协助,我们看这两个宏在PHP词法中的定义:
// 存在于zend_language_scanner.l⽂件中 #define YYGETCONDITION() SCNG(yy_state) #define YYSETCONDITION(s) SCNG(yy_state) = s #define SCNG LANG_SCNG // 存在于zend_globals_macros.h⽂件中 # define LANG_SCNG(v) (language_scanner_globals.v)
结合前⾯的全局变量和条件表达式宏的定义,我们可以知道PHP的词法解析是通过全局变量在⼀次解析过程中存在。 那么这个条件表达式具体是怎么使⽤的呢?我们看下⾯⼀个例⼦。这是⼀个可以识别为结束, 识别字符,数字等的简单字符串识别器。它使⽤了re2c的条件表达式,代码如下:
#include <stdio.h> #include "demo_def.h" #include "demo.h" Scanner scanner_globals; #define YYCTYPE char #define YYFILL(n) #define STATE(name) yyc##name #define BEGIN(state) YYSETCONDITION(STATE(state)) #define LANG_SCNG(v) (scanner_globals.v) #define SCNG LANG_SCNG #define YYGETCONDITION() SCNG(yy_state) #define YYSETCONDITION(s) SCNG(yy_state) = s #define YYCURSOR SCNG(yy_cursor) #define YYLIMIT SCNG(yy_limit) #define YYMARKER SCNG(yy_marker) int scan(){ /*!re2c <INITIAL>"<?php" {BEGIN(ST_IN_SCRIPTING); return T_BEGIN;} <ST_IN_SCRIPTING>[0-9]+ {return T_NUMBER;} <ST_IN_SCRIPTING>[ \n\t\r]+ {return T_WHITESPACE;} <ST_IN_SCRIPTING>"exit" { return T_EXIT; } <ST_IN_SCRIPTING>[a-z]+ {return T_LOWER_CHAR;} <ST_IN_SCRIPTING>[A-Z]+ {return T_UPPER_CHAR;} <ST_IN_SCRIPTING>"?>" {return T_END;} <ST_IN_SCRIPTING>[^] {return T_UNKNOWN;} <*>[^] {return T_INPUT_ERROR;} */ } void print_token(int token) { switch (token) { case T_BEGIN: printf("%s\n", "begin");break; case T_NUMBER: printf("%s\n", "number");break; case T_LOWER_CHAR: printf("%s\n", "lower char");break; case T_UPPER_CHAR: printf("%s\n", "upper char");break; case T_EXIT: printf("%s\n", "exit");break; case T_UNKNOWN: printf("%s\n", "unknown");break; case T_INPUT_ERROR: printf("%s\n", "input error");break; case T_END: printf("%s\n", "end");break; } } int main(int argc, char* argv[]) { int token; BEGIN(INITIAL); // 全局初始化,需要放在scan调⽤之前 scanner_globals.yy_cursor = argv[1]; //将输⼊的第⼀个参数作为要解析的字符串 while(token = scan()) { if (token == T_INPUT_ERROR) { printf("%s\n", "input error"); break; } if (token == T_END) { printf("%s\n", "end"); break; } print_token(token); } return 0; }
和前⾯的简单⽰例⼀样,如果你是在linux环境下,可以使⽤如下命令⽣成可执⾏⽂件
re2c -o demo.c -c -t demo_def.h demo.l gcc demo.c -o demo -g chmod +x demo
在使⽤re2c⽣成C代码时我们使⽤了-c -t demo_def.h参数,这表⽰我们使⽤了条件表达式模式,⽣成条件的定义头⽂件。 main函数中,在调⽤scan函数之前我们需要初始化条件状态,将其设置为INITIAL状态。 然后在扫描过程中会直接识别出INITIAL状态,然后匹配<?php字符串识别为开始,如果开始不为
<?php,则输出input error。 在扫描的正常流程中,当扫描出<?php后,while循环继续向下⾛,此时会再次调⽤scan函数,当前条件状态为ST_IN_SCRIPTING, 此时会跳过INITIAL状态,直接匹配<ST_IN_SCRIPTING>状态后的规则。如果所有的<ST_IN_SCRIPTING>后的规则都⽆法匹配,输出unkwon。 这只是⼀个简单的识别⽰例,但是它是从PHP的词法扫描器中抽离出来的,其实现过程和原理类似。
那么这种条件状态是如何实现的呢?我们查看demo.c⽂件,发现在scan函数开始后有⼀个跳转语句:
int scan(){ #line 25 "demo.c" { YYCTYPE yych; switch (YYGETCONDITION()) { case yycINITIAL: goto yyc_INITIAL; case yycST_IN_SCRIPTING: goto yyc_ST_IN_SCRIPTING; } ... }
在zend_language_scanner.c⽂件的lex_scan函数中也有类型的跳转过程,只是过程相对这⾥来说if语句多⼀些,复杂⼀些。 这就是re2c条件表达式的实现原理。
语法分析
Bison是⼀种通⽤⽬的的分析器⽣成器。它将LALR(1)上下⽂⽆关⽂法的描述转化成分析该⽂法的C程序。 使⽤它可以⽣成解释器,编译器,协议实现等多种程序。 Bison向上兼容Yacc,所有书写正确的Yacc语法都应该可以不加修改地在Bison下⼯作。 它不但与Yacc兼容还具有许多Yacc不具备的特性。
Bison分析器⽂件是定义了名为yyparse并且实现了某个语法的函数的C代码。 这个函数并不是⼀个可以完成所有的语法分析任务的C程序。 除此这外我们还必须提供额外的⼀些函数: 如词法分析器、分析器报告错误时调⽤的错误报告函数等等。 我们知道⼀个完整的C程序必须以名为main的函数开头,如果我们要⽣成⼀个可执⾏⽂件,并且要运⾏语法解析器, 那么我们就需要有main函数,并且在某个地⽅直接或间接调⽤yyparse,否则语法分析器永远都不会运⾏。
先看下bison的⽰例:逆波兰记号计算器
%{ #define YYSTYPE double #include <stdio.h> #include <math.h> #include <ctype.h> int yylex (void); void yyerror (char const *); %} %token NUM %% input: /* empty */ | input line ; line: '\n' | exp '\n' { printf ("\t%.10g\n", $1); } ; exp: NUM { $$ = $1; } | exp exp '+' { $$ = $1 + $2; } | exp exp '-' { $$ = $1 - $2; } | exp exp '*' { $$ = $1 * $2; } | exp exp '/' { $$ = $1 / $2; } /* Exponentiation */ | exp exp '^' { $$ = pow($1, $2); } /* Unary minus */ | exp 'n' { $$ = -$1; } ; %%
#include <ctype.h> int yylex (void) { int c; /* Skip white space. */ while ((c = getchar ()) == ' ' || c == '\t') ; /* Process numbers. */ if (c == '.' || isdigit (c)) { ungetc (c, stdin); scanf ("%lf", &yylval); return NUM; } /* Return end-of-input. */ if (c == EOF) return 0; /* Return a single char. */ return c; } void yyerror (char const *s) { fprintf (stderr, "%s\n", s); } int main (void) { return yyparse (); }
我们先看下运⾏的效果:
bison demo.y gcc -o test -lm test.tab.c chmod +x test ./test
gcc命令需要添加-lm参数。因为头⽂件仅对接⼝进⾏描述,但头⽂件不是负责进⾏符号解析的实体。此时需要告诉编译器应该使⽤哪个函数库来完成对符号的解析。 GCC的命令参数中,-l参数就是⽤来指定程序要链接的库,-l参数紧接着就是库名,这⾥我们在-l后⾯接的是m,即数学库,他的库名是m,他的库⽂件名是libm.so。
这是⼀个逆波兰记号计算器的⽰例,在命令⾏中输⼊ 3 7 + 回车,输出10。
⼀般来说,使⽤Bison设计语⾔的流程,从语法描述到编写⼀个编译器或者解释器,有三个步骤:
- 以Bison可识别的格式正式地描述语法。对每⼀个语法规则,描述当这个规则被识别时相应的执⾏动作,动作由C语句序列。即我们在⽰例中看到的%%和%%这间的内容。
- 描述编写⼀个词法分析器处理输⼊并将记号传递给语法分析器(即yylex函数⼀定要存在)。词法分析器既可是⼿⼯编写的C代码, 也可以由lex产⽣,后⾯我们会讨论如何将re2c与bison结合使⽤。上⾯的⽰例中是直接⼿⼯编写C代码实现⼀个命令⾏读取内容的词法分析器。
- 编写⼀个调⽤Bison产⽣的分析器的控制函数,在⽰例中是main函数直接调⽤。编写错误报告函数(即yyerror函数)。
将这些源代码转换成可执⾏程序,需要按以下步骤进⾏:
- 按语法运⾏Bison产⽣分析器。对应⽰例中的命令,bison demo.y
- 同其它源代码⼀样编译Bison输出的代码,链接⽬标⽂件以产⽣最终的产品。即对应⽰例中的命令gcc -o test -lm test.tab.c
我们可以将整个Bison语法⽂件划分为四个部分。 这三个部分的划分通过%%',%{' 和`%}'符号实现。⼀般来说,Bison语法⽂件结构如下:
%{ 这⾥可以⽤来定义在动作中使⽤类型和变量,或者使⽤预处理器命令在那⾥来定义宏, 或者使⽤ #include包含需要的⽂件。 如在⽰例中我们声明了YYSTYPE,包含了头⽂件math.h等,还声明了词法分析器yylex和错误打印程序yyerror。 %} Bison 的⼀些声明 在这⾥声明终结符和⾮终结符以及操作符的优先级和各种符号语义值的各种类型 如⽰例中的%token NUM。我们在PHP的源码中可以看到更多的类型和符号声明,如%left,%right的使⽤ %% 在这⾥定义如何从每⼀个⾮终结符的部分构建其整体的语法规则。 %% 这⾥存放附加的内容 这⾥就⽐较⾃由了,你可以放任何你想放的代码。 在开始声明的函数,如yylex等,经常是在这⾥实现的,我们的⽰例就是这么搞的。
我们在前⾯介绍了PHP是使⽤re2c作为词法分析器,那么PHP是如何将re2c与bison集成在⼀起的呢?我们以⼀个从PHP源码中剥离出来的⽰例来说明整个过程。这个⽰例的功能与上⼀⼩节的⽰例类似,作⽤都是识别输⼊参数中的字符串类型。 本⽰例是在其基础上添加了语法解析过程。 ⾸先我们看这个⽰例的语
法⽂件:demo.y。
%{ #include <stdio.h> #include "demo_scanner.h" extern int yylex(znode *zendlval); void yyerror(char const *); #define YYSTYPE znode //关键点⼀,znode定义在demo_scanner.h %} %pure_parser // 关键点⼆ %token T_BEGIN %token T_NUMBER %token T_LOWER_CHAR %token T_UPPER_CHAR %token T_EXIT %token T_UNKNOWN %token T_INPUT_ERROR %token T_END %token T_WHITESPACE
%%
begin: T_BEGIN {printf("begin:\ntoken=%d\n", $1.op_type);} | begin variable { printf("token=%d ", $2.op_type); if ($2.constant.value.str.len > 0) { printf("text=%s", $2.constant.value.str.val); } printf("\n"); } variable: T_NUMBER {$$ = $1;} |T_LOWER_CHAR {$$ = $1;} |T_UPPER_CHAR {$$ = $1;} |T_EXIT {$$ = $1;} |T_UNKNOWN {$$ = $1;} |T_INPUT_ERROR {$$ = $1;} |T_END {$$ = $1;} |T_WHITESPACE {$$ = $1;} %%
void yyerror(char const *s) { printf("%s\n", s); }
这个语法⽂件有两个关键点:
214页。。。















 2246
2246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









