







1 概述
- 线程是CPU基本操作单元,由程序计数器、栈和一些的寄存器组成(当然包括一个线程ID)
- 传统(重量级的)进程控制着单一的线程——包括一个单一的程序计数器,及可以在任意给定时间执行的一系列指令集
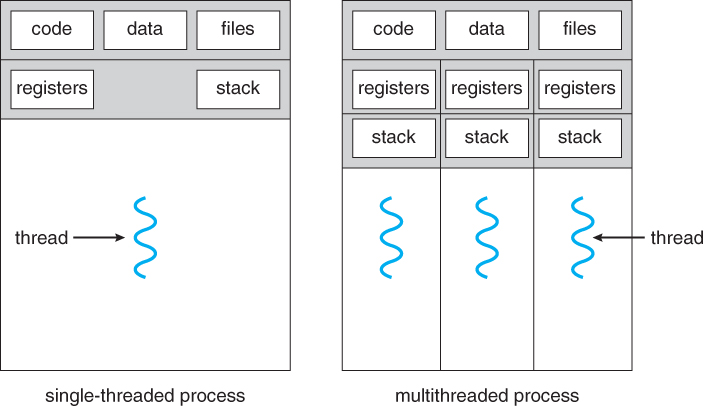
- 如下图所示,多线程应用程序在一个进程中有多个线程,每个线程都有自己的程序计数器、堆栈和寄存器组,但是共享通用的代码、数据和某些结构,比如打开的文件。
1.1 动机
- 在现代编程中,当进程有多个任务独立于其它任务时,线程是非常有用的。
- 尤其是某个任务阻塞,又希望其它任务可以继续进行。
- 以一个字处理软件为例,既需要一个前台线程来处理用户的输入(如键盘敲击事件),又需要一个后台线程来检查语法和拼写,还需要第三个线程来从硬件驱动来显示图像(文字)、第四个线程来定期保存修改的文件。
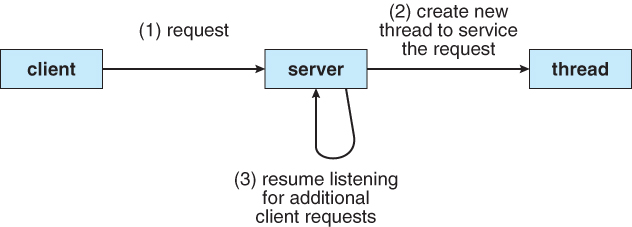
- 另一个例子是web服务器。多线程允许服务器同时处理多个任务,而不需要针对每个请求fork一个进程(这也是线程的概念被发明之前的常用做法。一个守护进程来监听一个端口,对每个进入的请求fork一个子进程,然后返回继续监听)。
1.2 好处
多线程有以下四点好处:
- 可响应的。当某些线程因为阻塞或者密集运算而运行缓慢时,其它线程仍然可以快速响应。
- 资源共享。线程默认共享公共代码、数据以及其他资源,这允许在单个地址空间中同时执行多个任务。
- 经济。创建和管理线程(及上下文切换)比起在进程上做同样的动作快太多了。
- 可扩展,如利用多核处理器架构。不管硬件提供了多少个CPU,单线程只能在其中一个上运行,而多线程应用程序可以同时利用多个CPU(值得注意的是当多个进程争用CPU时,单线程程序也能够从多核中受益,如平均负载高于某个阈值时)。
2 多核编程
- 进来的CPU架构趋势向着多核芯片发展。
- 多线程在传统的单核芯片上需要交错执行。在多核上才可以做到真正的并行,如下图:

单核
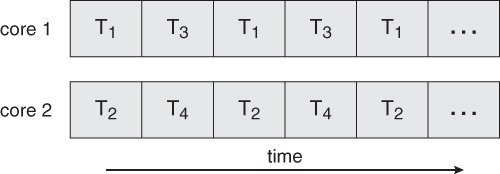
多核
- 对于操作系统来说更好的使用多核芯片需要使用新的调度算法。
- 随着多线程的日趋流行和重要(从10上升到1000的数量级),CPU的核心也被设计为可以支持更多的并发线程。
2.1 编程挑战
- 对于做应用的程序员来说,多核芯片带来了下列新的挑战:
- 挑选任务。检查应用程序以找到可以并发执行的活动。
- 平衡。查找同等重要的任务。也就是说,不把线程浪费在不重要的任务上。
- 数据分片。防止线程相互干扰。
- 数据依赖。如果某个任务依赖于另一个任务的结果,必须保证任务之间的同步顺序。
- 测试和调试。由于竞争条件变得更加复杂和难以识别,并行处理更加困难。
2.2 并发类型
理论上有两种方式来达到并发:
- 数据并发 将数据话费到多个核心(线程)上,对切分后的每块数据做同样的操作。例如,将一个大的图像分割成多个部分,并在不同的内核上执行相同的数字图像处理。
- 任务并发 将不同的任务划分到多个核心上并同时执行
实际应用中这两种并发会混用。
3 多线程模型
- 现代操作系统一般有两种线程模型:用户线程和操作系统线程(kernel thread)。
- 用户线程在kernel上层,不由kernel直接支持。程序员在他们的程序中使用的就是这种线程。
- Kernel线程由OS的kernel直接支持。所有现代操作系统都支持kernel级的线程,允许kernel执行多个并发任务/同时服务于多个系统调用。
- 用户线程必须以下列方式之一映射到kernel线程:
3.1 Many-To-One模型
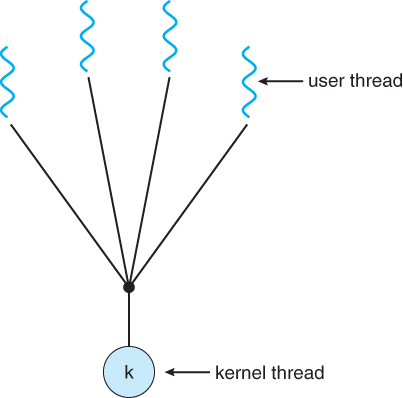
- 多个用户线程映射到一个kernel线程
- 线程管理是由用户空间中的线程库处理的,这是非常有效的。
- 但是如果某个系统调用阻塞了,所有的进程都会被阻塞,即使其他的用户线程仍然可以运行。
- 一个kernel线程只能操作一个CPU,所以这种模型无法跨多个CPU。
- 过去,Solaris上的Green thread和GNU的Portable线程实现了这种模型,但是这种做法在今天已经非常少见。
3.2 One-To-One模型
- o2o模型会创建一个单独的kernel线程来处理每个用户线程
- 解决了上面Many-To-One模型中阻塞调用及跨CPU的问题。
- 此模型的开销更大,会减慢你的系统。
- 此模型的多数实现会限制能够创建的线程最大条数
- Linux和Windows95-XP实现了o2o线程模型。
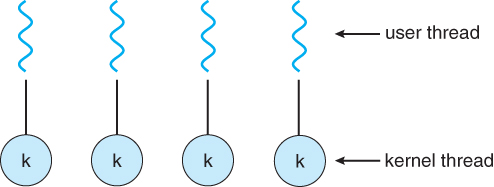
3.3 Many-To-Many模型
- m2m模型将任意数量的用户线程复用在相等或者更小数量的kernal线程上,结合了o2o和m2o模型的优点。
- 对于创建线程的数量没有限制。
- 阻塞kernel系统调用不会阻塞整个程序。
- 可以跨多个处理器。
- 根据当前CPU的数量和其他因素,可能会分配不同的进程的内核线程数量。
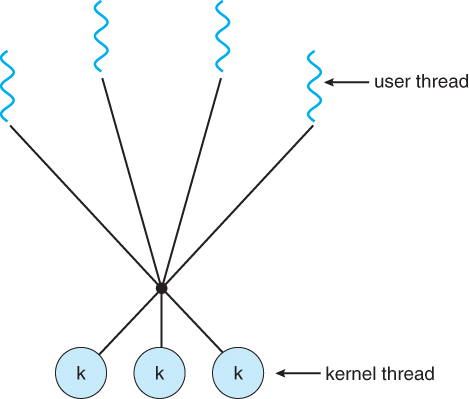
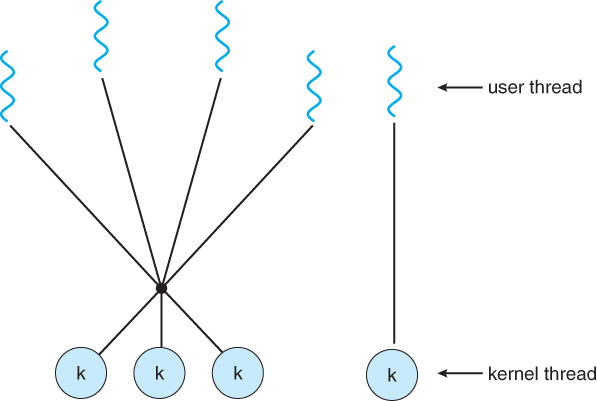
- m2m的一种流行变体是两层模型,它同时也允许many-to-many或者one-to-one操作
- IRIX, HP-UX, Tru64 UNIX及Solaris 9之前的版本使用了双层模型。
4 线程库
- 线程库为程序员创建及管理线程提供了API
- 线程库可以是现在用户空间或者内核空间中。前者仅涉及在用户空间内实现的函数,没有内核支持。后者涉及到系统调用,并且需要一个具有线程库支持的内核。
- 当前使用的主要有三种线程库:
- POSIX Pthreads - 作为POSIX扩展标准提供用户库或者内核库。
- Win32 threads - 在Windows系统上提供内核级别的库。
- Java 线程 - 线程的实现基于JVM运行的OS和硬件,如 Pthreads或Win32线程。
- 下列章节讲述如何使用者三种线程库,在独立线程中来计算0到N的和,并在 ‘sum’变量中存储最终结果。
4.1 Pthreads
- POSIX标准(IEEE 1003.1c)定义了pThreads标准,但没有定义实现。
- Solaris、Linux、Max OSX、Tru64提供了pThreads,Windows通过公共领域共享软件也支持pThreads
- 全局变量在所有threads内共享。
- 一个线程在继续运行前可以等待其他线程重新加入。
- pThreads通过一个指定的函数运行,如下例所示:
#include <pthread.h>
#include <stdio.h>
int sum;
void *runner(void *param); /* the thread */
int main(int argc, char *argv[]) {
pthread_t tid; /* the thread identifier */
pthread_attr_t attr; /* set of thread attributes */
if (argc != 2) {
fprintf(stderr, "usage: a.out <integer value>\n");
return -1;
}
if(atoi(argv[1]) < 0) {
fprintf(stderr, "%d must be >= 0\n", atoi(argv[1]));
return -1;
}
/* get the default attributes */
pthread_attr_init(&attr);
/* create the thread */
pthread_create(&tid, &attr, runner, argv[1]);
/* wait for the thread to exit */
pthread_join(tid, NULL);
printf("sum = %d\n", sum);
}
/* The thread will begin control in this function */
void *runner(void *param) {
int i, upper = atoi(param);
sum = 0;
for(i = 1; i <= upper; i++)
sum += i;
pthread_exit(0);
}4.2 Windows线程
和Pthreads类似。下面的例子描述了其中的区别,多数在于语法和变量名上:
#include <windows.h>
#include <stdio.h>
DWORD Sum;
/* the thread runs in this separate function */
DWORD WINAPI Summation(LPVOID Param) {
DWORD Upper = *(DWORD*)Param;
for (DWORD i = 0; i <= Upper; i++)
Sum += i;
return 0;
}
int main(int argc, char *argv[]) {
DWORD ThreadId;
HANDLE ThreadHandle;
int Param;
/* perform some basic error checking */
if (argc != 2) {
fprintf(stderr, "An integer parameter is required\n");
return -1;
}
Param = atoi(argv[1]);
if (Param < 0) {
fprintf(stderr, "An integer >= 0 is required\n");
return -1;
}
// create the thread
ThreadHandle = CreateThread(
NULL, // default security attributes
0, // default stack size
Summation, // thread function
&Param, // parameter to thread function
0, // default craetion flags
&ThreadId); // returns the thread identifier
if (ThreadHandle != NULL) {
// now wait for the thread to finish
WaitForSingleObject(ThreadHandle, INFINITE);
// close the thread handle
CloseHandle(ThreadHandle);
printf("sum = %d\n", Sum);
}
}
4.3 Java线程
- 所有Java程序都使用了线程,包括通常意义上单线程程序。
- 创建一个线程需要一个实现了Runnable接口的对象,具体是实现其中的"public void run()"方法。所有Thread类的子类都天然包含此方法(在实践中,必须重写run()方法以使线程具有实际功能)。
- 创建Thread对象并不直接启动线程。必须在程序中显式调用Thread的start()方法。Start()方法分配并初始化Thread所需的内存,然后调用run()方法(程序员并不直接调用run)。
- Java不支持全局对象,所以线程必须传递一个共享对象的引用来共享数据。如下例中的Sum对象。
- JVM在原生OS之上运行,JVM标准也没有指定Java线程如何映射到操作系统线程。所以各JVM实现方式可能并不一样,可以是one-to-one,many-to-many或者many-to-one。(在UNIX系统上JVM通常使用PThreads,在Windows上通常使用windows线程)。
public class JavaThread {
public static void main(String[] args) {
if(args.length > 0) {
if (Integer.parseInt(args[0]) < 0)
System.err.println(args[0] + "must be >= 0.");
else {
// create the object to be shared
Sum sumObject = new Sum();
int upper = Integer.parseInt(args[0]);
Thread thrd = new Thread(new Summation(upper, sumObject));
try {
thrd.join();
System.out.println("The sum of " + upper + " is " + sumObject.getSum());
} catch (InterruptedException e) {}
}
} else
System.err.println("Usage: Summation <integer value>");
}
}
class Sum {
private int sum;
public int getSum() {
return sum;
}
public void setSum(int sum) {
this.sum = sum;
}
}
class Summation implements Runnable {
private int upper;
private Sum sumValue;
public Summation(int upper, Sum sumValue) {
this.upper = upper;
this.sumValue = sumValue;
}
@Override
public void run() {
int sum = 0;
for (int i = 0; i <= upper; i++)
sum += i;
sumValue.setSum(sum);
}
}5 隐式提供的线程
将2.1中所列的负担从程序员身上转移到编译器和运行时库上。
5.1 线程池
- 不停地创建和销毁线程不仅非常低效,而且无法控制线程创建的数量。
- 一个可选的解决方案是在程序启动时创建一定数量的线程,然后将它们放到线程池中。
- 由线程池来分配线程,当线程运行完后放回线程池中。
- 当池中没有可用线程时,程序可以选择等待某个线程重新可用。
- 池中线程的最大数量可以由参数来调整,或者根据系统负载来动态响应。
- Win32 通过PoolFunction提供了线程池。Java通过JUC提供了线程池。Apple通过Grand Central Dispatch架构来纯支持线程池。
5.2 OpenMP
- OpenMP是一组用于C、C++或FORTRAN程序的编译器指令,这些指令指示编译器在适当的地方自动生成并行代码。
- 指令举例如下:
#pragma omp parallel
{
/* some parallel code here */
}
这会导致编译器创建可用CPU同等数量的线程数(例如,四核机器上的4个线程),并在每个线程上运行并行代码块(即并行区域)。
- 另一个示例指令是 "#pragma omp parallel for",这将导致紧跟其后的for循环被并行化,将迭代划分到可用的核心中。
5.3 GrandCentral Dispatch, GCD
- GCD是在苹果OSX和iOS操作系统上提供的支持并行的C和C++的扩展。
- 和OpenMP类似,GCD允许用户指定程序串行或并行执行,方法是在花括号前加^符号。如:^{ printf( "I am a block.\n" ); }
- GCD通过把代码块放到一个或几个分派队列中进行调度
- 放置在串行队列上的块会一个接一个地取出。前一块执行完之后,下一个块会被调度。
- 有三个并发队列,大致对应于低、中或高优先级。块也会一个接一个地从这些队列中移除,取决于线程的可用性,有些块可能不需要等待其它线程先完成就会被分派。
- GCD内部管理着一个POSIX线程池,其大小根据负载情况可能会上下波动。
5.4 其它方案
还存在着一些其它的方案,如Microsoft的Threading Building Blocks(TBB)和其他产品,及Java的JUC包。
6 线程相关问题
6.1 fork() 和 exec() 系统调用
Q:从一个线程中fork,会复制整个进程,还是新的进程是单线程的?
A:视系统而定。
A:如果新的进程立即执行,就无需复制其它线程。反之不是立即执行,则全部的线程都需要复制。
A:UNIX提供了很多版本的fork调用来适用于不同场景。
6.2: 信号处理
Q:如果一个多线程的进程收到一个信号,它会把信号转发到哪个线程?
A:有四个主要选项:
- 发送到该信号要应用的线程。
- 发送到所有线程。
- 发送到某些特定线程。
- 委托一个指定线程来接受所有信号。
- 最好的选择将取决于具体的信号类型。
- UNIX允许线程自定义需要接受和忽略的信号。但是这些信号只能被发送到一个线程,通常是能够接受此类信号的第一个线程。
- UNIX提供两个系统调用 kill(pid, signal) 和pthread_kill(tid, signal),将信号分别发送到进程或特定的线程。
- Windows不支持信号,但是可以通过Asynchronous Procedure Calls(APCs)来模拟。APCs会发送到指定线程而非进程。
6.3 取消线程
- 当不需要线程时可以通过其他线程的调用来取消:
- Asychronous Cancellation 立即取消线程。
- Deferred Cancellation 为线程设置一个取消标记,当线程觉得合适时可以取消自己。这种方式被取消的线程需要周期性地检查此标志并自己控制退出。
- 前一种方式中,(共享的)资源分配和跨线程的数据传输可能会存在问题。
6.4 线程数据
- 大多数数据在线程之间共享,这也是使用线程的主要好处之一。
- 但是有些时候线程也需要独享的数据。
- 大多数主要的线程库(pThreads,Win32,Java)都提供了线程独占数据,如thread-local storage或者TLS。注意,这更像是静态数据而不是局部变量,因为当函数结束时它仍然存在。
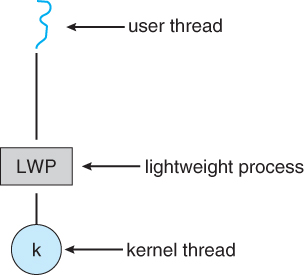
6.5 激活调度器
- 许多线程实现都提供了一个虚拟处理器作为用户线程和内核线程之间的接口,特别是对于多对多或两层模型。
- 此虚拟的处理器被称为轻量级进程,LWP。
- LWPs和kernel线程之间存在一对一的对应关系
- 可用内核线程的数量会动态变化
- 应用程序(用户级线程库)会将用户线程映射到可用的LWPs。
- kernel线程被OS调度到真实的处理器上
- 当特定事件(如通过调用upcall阻塞线程)发生时,内核会与用户级的线程库通信,通过线程库的upcall handler来处理。upcall为upcall handler提供了一个新的LWP,用来重新调度即将被阻塞的用户线程。当一个线程从阻塞状态恢复时,操作系统也会发出调用,线程库可以进行做相应调整。
- 如果kernel线程阻塞了,LWP就会阻塞,同时阻塞用户线程。
- 理想情况下,可用的LWPs应该和可以并发阻塞的内核线程数一样多。否则,如果所有的LWPs都被阻塞,那么用户线程将不得不等待一个可用的线程。
7 操作系统示例
7.1 Windows XP 线程
- Win32 API线程库支持 one-to-one 线程模型
- Win32同时提供fiber库,支持many-to-many模型
- Win32线程包含:Thread ID、寄存器、用户态栈和内核态栈、一个用于运行时库和动态链接库的私有存储区
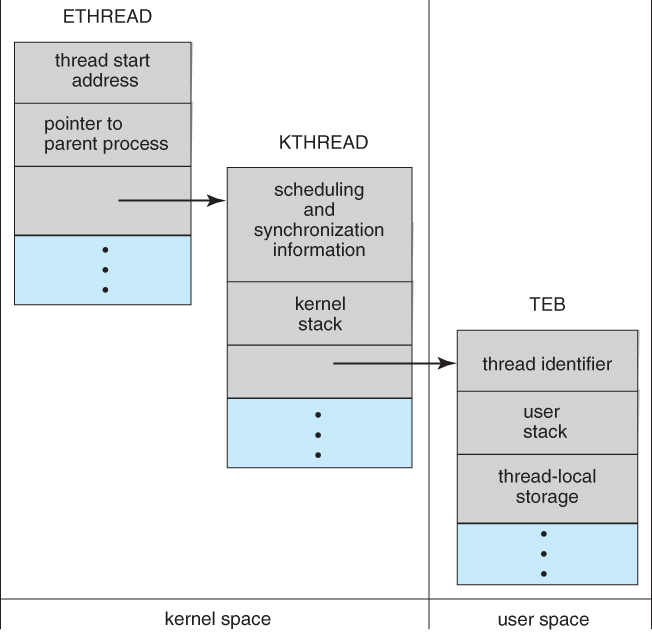
- Windows线程关键的数据结构是ETHREAD(执行线程阻塞)、KTHREAD(内核线程阻塞)和TEB(thread enviroment block)。ETHREAD和KTHREAD在内核控件中,只有内核能够获取。TEB存在用户空间。
7.2 Linux线程
- Linux并不区分线程和进程 - 它使用task来代替。
- 一个传统的fork系统调用复制整个进程,如前所述。
- 一个可选的系统调用,clone()允许父子任务间不同程度的共享,由下面的flag参数来决定:
| flag | 释义 |
|---|---|
| CLONE_FS | File-system information is shared |
| CLONE_VM | The same memory space is shared |
| CLONE_SIGHAND | Signal handlers are shared |
| CLONE_FILES | The set of open files is shared |
- 调用clone()且不设置参数时和fork()效果一样。使用CLONE_FS、CLONE_VM、CLONE_SIGHAND和CLONE_FILES调用clone()等同于创建一个线程,因为所有这些数据结构都将被共享。
- Linux使用task_struct结构来实现task级别。当没有设置标志时,就复制该结构体指向的资源;如果设置了标志,那么只复制到资源的指针,因此资源是共享的。(在OO编程中,可以考虑深度拷贝和浅拷贝。)
- (第9版中已删除)一些Linux发行版现在支持NPTL(Native POXIS Thread Library)
- POSIX 兼容
- 支持SMP(symmetric multiprocessing),NUMA(non-uniform memory access)多处理器
- 支持数以千计的线程。















 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









