






SQL(Structured Query Language 结构化查询语言 )是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。SQL 是一种 ANSI(American National Standards Institute 美国国家标准化组织)标准的计算机语言,是一种第四代语言(4GL)。
SQL包含6个部分:1、数据查询语言(DQL:Data Query Language) 2、数据操作语言(DML:Data Manipulation Language)3、事务控制语言(TCL) 4、数据控制语言(DCL)5、数据定义语言(DDL)6、指针控制语言(CCL)
在DDL或者DML中,不同的操作都有对应的语句,如CREATE、ALTER、DROP、INSERT、DELETE,而在DQL中只有一条语句,即:SELECT语句,SELECT也算是DQL的标志。在计算机或者非计算机岗位中,SQL语言中的DQL被广泛应用。
SQL语言是诸多计算机语言中相对来说比较容易学的语言,简单高效易上手,很适合青少年及对计算机编程语言感兴趣的人学习。在SQL语言的应用过程中,对于数据库的设计、操作、查询等掌握,可以帮助参与者提高计算机编程能力和设计能力。可以想象,当你拥有一些重要的数据时,如果学会了数据统计和数据处理,将是一件非常有益的事情;或者去处理一些常规的数据,有可能得到一些意外的惊喜。数据,是一种特殊的资源,如何利用这种资源非常值得去深思。
在21世纪的今天,计算机行业蓬勃发展,掌握一门计算机语言显得非常的必要。而SQL非常值得爱好者拥有,首先就是它的实用性很强,当学会SQL之后,就会将数据库的数据牢牢的攥在手里,任你想怎么查询就怎么查询,而SQl与其他编程语言结合使用的时候,SQL也是非常重要的组成部分。当SQL熟练时,已经可以掌控数据,至于数据结构的整理和数据渲染可以由其他编程语言来完成。
本人曾经利用SQL统计人口,首先整理了自建国以来至今(1949~2019)每年的出生人口(网上查的数据),然后做了一些简单的统计,其中包括总人口、劳动力人口、适龄结婚人口、各个年代总人口、各个年代平均每年出生人口、各个年代与上个年代每年出生人口差、未来几十年的劳动力人口变化、未来几十年适龄结婚人口变化以及各个指标的同比和环比增幅,最终会预判出未来很多行业的整体趋势和社会劳动力的整体趋势。以此举例,如果有了更好的数据资源,利用数据库以及SQL将其整合与分析,将会受益匪浅。
SQL分为6部分,本文着重MySQL数据库DQL的场景应用实例,可以为初学者提供适合场景设计的查询语句,通过分析和学习,积累更多的查询语句经验,来应对以后的实际应用场景。DQL语句编写简单易懂,难点在于怎样通过分析与设计将需求转化为结构化查询语句,实现数据查询。
在MySQL数据库SQL查询语句实际应用之前需要了解四点:1、SELECT语句结构 2、SELECT语句执行顺序 3、索引 4、视图。
1、SELECT语句结构:熟练的掌握SELECT语句结构是应用的前提,所有的查询语句必须按照固定结构搭配,才能正常执行,如果颠倒语句结构会出现语句报错;以下语句来自mysql官网“MySQL 8.0参考手册”:https://dev.mysql.com/doc/refman/8.0/en/select.html
SQL函数和运算符参考:https://dev.mysql.com/doc/refman/8.0/en/sql-function-reference.html 表达式评估中的类型转换: https://dev.mysql.com/doc/refman/8.0/en/type-conversion.html
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr] ...
[into_option]
[FROM table_references
[PARTITION partition_list]]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}, ... [WITH ROLLUP]]
[HAVING where_condition]
[WINDOW window_name AS (window_spec)
[, window_name AS (window_spec)] ...]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
2、SELECT语句执行顺序:SELECT语句在运行时有执行顺序,需要知道语句执行顺序,在有些场景下才会获取正确的预期结果。
参考地址:https://www.cnblogs.com/rollenholt/p/3776923.html
执行顺序如下:
1. FORM: 对FROM的左边的表和右边的表计算笛卡尔积。产生虚表VT1
2. ON: 对虚表VT1进行ON筛选,只有那些符合的行才会被记录在虚表VT2中。
3. JOIN:如果指定了OUTER JOIN(比如left join、 right join),那么保留表中未匹配的行就会作为外部行添加到虚拟表VT2中,产生虚拟表VT3, rug from子句中包含两个以上的表的话,那么就会对上一个join连接产生的结果VT3和下一个表重复执行步骤1~3这三个步骤,一直到处理完所有的表为止。
4. WHERE:对虚拟表VT3进行WHERE条件过滤。只有符合的记录才会被插入到虚拟表VT4中。
5. GROUP BY: 根据group by子句中的列,对VT4中的记录进行分组操作,产生VT5.
6. CUBE | ROLLUP: 对表VT5进行cube或者rollup操作,产生表VT6.
7. HAVING:对虚拟表VT6应用having过滤,只有符合的记录才会被 插入到虚拟表VT7中。
8. SELECT:执行select操作,选择指定的列,插入到虚拟表VT8中。
9. DISTINCT:对VT8中的记录进行去重。产生虚拟表VT9.
10. ORDER BY: 将虚拟表VT9中的记录按照进行排序操作,产生虚拟表VT10.
11. LIMIT:取出指定行的记录,产生虚拟表VT11, 并将结果返回。
3、索引:索引的建立对于MySQL数据库的DQL语句的高效运行是很重要的,索引可以大大提高数据的检索速度。
4、视图:在 SQL 中,视图是基于 SQL 语句的结果集的可视化的表。视图包含行和列,就像一个真实的表。视图中的字段就是来自一个或多个数据库中的真实的表中的字段。我们可以向视图添加 SQL 函数、WHERE 以及 JOIN 语句。在有些业务当中,表结构与数据相对比较隐私或者复杂,对业务了解不够细致的人员在获取某些业务信息时会比较麻烦,这时就可以创建一个视图。视图封装了业务数据的获取过程,直接将数据结果集展示出来,有利于其他非业务人员快速方便的查询业务信息。
在了解查询语句语法结构及规则的同时,需要掌握更多的语句结构样例,更加深刻的理解语句结构的变化和语句结构所表达的查询内容。积累更多的语法结构模型,才会有更加灵活的语句组织方式和更加深刻的认识。工欲善其事,必先利其器。
接下来列举应用场景,分析具体的应用实例。如下,是不同的语句结构实现不同场景的需求:
场景1: 测试select查询语句
分析:组织含“select”关键字的语句,查看是否运行正常。
语句:SELECT 1; 或者 SELECT 1 FROM DUAL;
场景2:测试select语句嵌套结构
分析:使用select查询语句的嵌套,查看是否运行正常。
语句:SELECT (SELECT (SELECT 2*3));
场景3:获取mysql数据库用户信息
分析:查询mysql数据库,获取用户信息。
语句:SELECT * FROM `mysql`.`user` LIMIT 0, 1000;
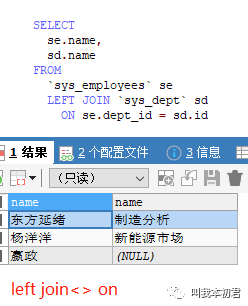
场景4:获取员工及部门信息
分析:查询员工表,附带员工部门信息。
语句:SELECT
se.name,
sd.name
FROM
`sys_employees` se
LEFT JOIN `sys_dept` sd
ON se.dept_id = sd.id
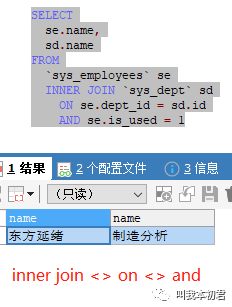
场景5:获取有部门并且可用的用户及部门信息
分析:查询用户表与部门表的交集数据,过滤可用的用户信息。
语句:
SELECT
se.name,
sd.name
FROM
`sys_employees` se
INNER JOIN `sys_dept` sd
ON se.dept_id = sd.id
AND se.is_used = 1
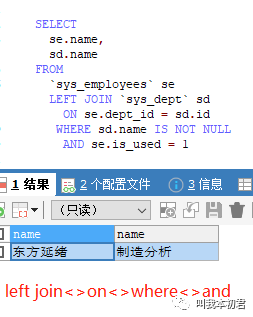
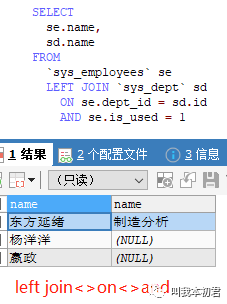
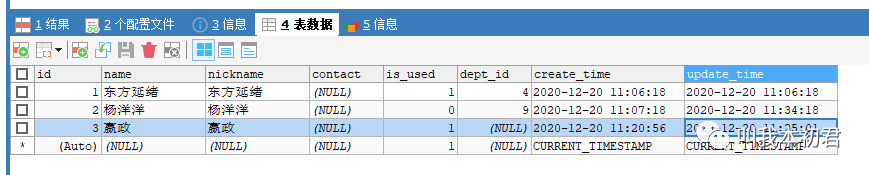
易混淆的语句:在inner join<>on<>and语句结构中join两边的表在取得交集之后,还可以继续筛选条件,最终得到筛选后的信息。然而在left join<>on<>and语句结构中左表没有进行任何筛选,所有数据的关联结果以左表为主,所有的on<>and都不会过滤左表任何数据,但是右表数据会条件筛选而受到影响。如果需要用left join完成语句查询,需要添加:
where sd.name IS NOT NULL and se.is_used = 1 如图:
场景6:获取有效员工当前部门和上一级部门的信息
分析:查询当前有效员工,关联用户部门和上一级部门,主信息为员工信息,联表部门信息。基于对场景5的分析可知left join的on<>and作用,除了关联外键信息的其他筛选条件,需要放在where后。
语句:
SELECT
se.name AS NAME,
sd.name AS deptName,
sdp.name AS deptParentName
FROM
`sys_employees` se
LEFT JOIN `sys_dept` sd
ON se.dept_id = sd.id
LEFT JOIN `sys_dept` sdp
ON sd.pid = sdp.id
WHERE se.is_used = 1
场景7:获取某用户最近7天每天的消费次数,统计用户最近一周消费习惯和活跃度。
分析:查询某用户最近7天消费记录,获取每条数据的日期 '%Y-%m-%d'格式信息,然后对日期格式信息进行分组聚合。
语句:
SELECT
dateData.create_date,
COUNT(dateData.create_date)
FROM
(SELECT
DATE_FORMAT(scr.create_time, '%Y-%m-%d') AS create_date
FROM
`sys_user_consumption_records` scr
WHERE DATE_FORMAT(scr.create_time, '%Y-%m-%d') BETWEEN DATE_FORMAT(
DATE_SUB(NOW(), INTERVAL 6 DAY),
'%Y-%m-%d'
)
AND DATE_FORMAT(NOW(), '%Y-%m-%d')
AND user_id = 1) dateData
GROUP BY dateData.create_date;
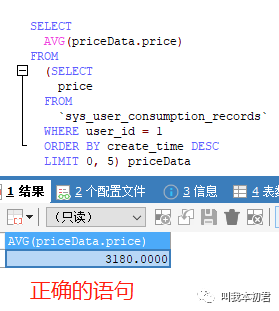
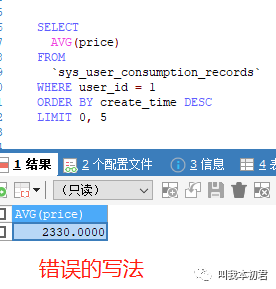
场景8:获取某用户最近100次消费的平均金额,用户消费能力评级。
分析:获取用户最近100次消费记录,通过消费记录进行聚合,获取平均消费金额
语句:
SELECT
AVG(priceData.price)
FROM
(SELECT
price
FROM
`sys_user_consumption_records`
WHERE user_id = 1
ORDER BY create_time DESC
LIMIT 0, 100) priceData
易混淆的语句:在进行数据区间的局部信息计算时,需要进行筛选(where)、排序(order by)、截取(limit)操作,在这些操作之后所获得的数据列表才是需要进行计算的有效数据。然而,SQL查询语句规定了关键字的执行顺序,”SELECT”关键字优先于”DISTINCT”、”ORDER BY”、“LIMIT”,因此在语句执行的时候,SELECT聚合函数执行完成之后,”ORDER BY”、“LIMIT”才进行筛选。因此写语句的初学者很容易忽视SQL的执行顺序,从而导致错误的语句和错误的结果。如图:
场景9:获取每一位用户最近一次消费记录,设置用户活跃等级。
分析:以用户ID分组,获取每位用户最大时间的数据,联表查询用户消费记录数据。
语句:
SELECT
sucri.*
FROM
sys_user_consumption_records sucri
INNER JOIN
(SELECT
sucr.user_id,
MAX(sucr.create_time) AS create_time
FROM
sys_user_consumption_records sucr
GROUP BY sucr.user_id) userNewRecord
ON sucri.user_id = userNewRecord.user_id
AND sucri.create_time = userNewRecord.create_time
场景10:获取每位用户的最高消费记录信息
分析:以用户ID分组,获取每位用户数据最高消费的记录(最高消费记录可能有多条,取最新一条),联表查询用户消费记录数据。
语句:
SELECT
sucri.*
FROM
sys_user_consumption_records sucri
INNER JOIN
(SELECT
sucr.user_id AS uuserId,
(SELECT
sucrchild.id
FROM
sys_user_consumption_records sucrchild
WHERE sucrchild.user_id = uuserId
ORDER BY sucrchild.price DESC,
sucrchild.create_time DESC
LIMIT 0, 1) AS sucrchildId
FROM
sys_user_consumption_records sucr
GROUP BY sucr.user_id) userNewRecord
ON sucri.id = userNewRecord.sucrchildId
易混淆的语句:在以user_id分组的select中,获取最高消费记录子句需要引用”uuserId”值进行当前用户数据的筛选。在这个子句当中所有的left join或者inner join的on<>and<>条件筛选中都不能出现”uuserId”值筛选条件,否则会报错。”uuserId”值只能出现在子句的where<>and<>筛选条件中
以上是列举的10个应用场景,举例了不同场景需求的实现方式。还有更多的语句查询细节,需要在应用过程中仔细学习其含义并且熟悉应用场景。不同场景应用到的语句各不相同, 比如“IFNULL(table.num,table.num,0)”,将为null的值默认转为0;比如“order by serial + 0”将字符串的数值转为数字进行排序等等。不同的场景和需求,需要不同的结构语句和函数,根据实际情况设计出合理的语句来实现业务。在开发中不仅要解决实际问题,更加需要不断的积累不同的结构语句模型,来给新的需求提供借鉴的思路。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









