







设想一个海量数据场景下的wordcount需求:
| 单机版:内存受限,磁盘受限,运算能力受限 分布式: 1、文件分布式存储(HDFS) 2、运算逻辑需要至少分成2个阶段(一个阶段独立并发,一个阶段汇聚) 3、运算程序如何分发 4、程序如何分配运算任务(切片) 5、两阶段的程序如何启动?如何协调? 整个程序运行过程中的监控?容错?重试? |
mapreduce 核心机制
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上;
mapreduce 核心模块
| 1、MRAppMaster(mapreduce application master) 2、MapTask 3、ReduceTask |
一个完整的mapreduce程序在分布式运行时有三类实例进程:
1、MRAppMaster:负责整个程序的过程调度及状态协调
2、mapTask:负责map阶段的整个数据处理流程
3、ReduceTask:负责reduce阶段的整个数据处理流程
下面以wordcount统计单词数量为例来分析:
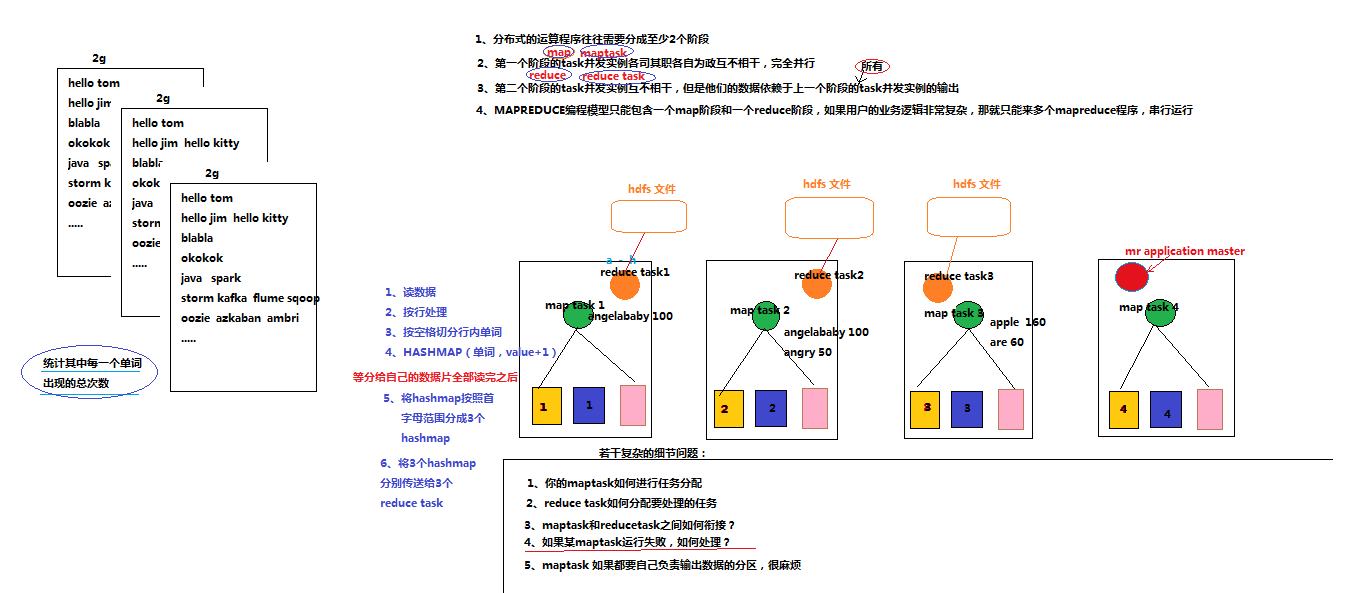
1.面对数据量比较大的文本数据,首先应该是将大量数据分发到不同的map 线程中,也就是同一个程序跑不同的实例。
2.第一个阶段的map task 并发实例各司其职互不相干,完全并行。
3.第二个阶段的reduce task 并发实例互不相干,但是他们的数据依赖于上一个阶段的所有task并发实例输出。
对于wordcount程序来说,有map和reduce阶段,但是两者之间如何衔接是最难的问题!!!
可能会出现的问题:
| 1.maptas如何进行任务分配 2.ruduce task如何分配要处理的任务 3.map task和reduce task 如何衔接通信的? 4.如果maptask运行失败,如何处置? 5.maptask如果都要自己负责输出数据的分区? |
对于以上会出现的问题,MAPREDUCE 框架提供了两个阶段的主管mapreduce application master,在任务初始化的时候,reduce 和map 都没有启动,mr application task先启动,负责协调开启几个map,每个map去处理那块文件数据,也会监控map task 何时处理完任务。而作为具体任务的执行者map task 不需要管怎样输出数据给reduce,只要把自己产生的结果文件输出到自己的工作目录。mr application master 然后负责启动若干数量的reduce task (参数配置reduce task 数量),告诉map task 输出数据中的哪一些片段,这样每一个map和reduce task会被master监控,如果哪一个任务失败会重新起一个任务。
流程解析
1、 一个mr程序启动的时候,最先启动的是MRAppMaster,MRAppMaster启动后根据本次job的描述信息,计算出需要的maptask实例数量,然后向集群申请机器启动相应数量的maptask进程。
2、 maptask进程启动之后,根据给定的数据切片范围进行数据处理,主体流程为:
a) 利用客户指定的inputformat来获取RecordReader读取数据,形成输入KV对
b) 将输入KV对传递给客户定义的map()方法,做逻辑运算,并将map()方法输出的KV对收集到缓存
c) 将缓存中的KV对按照K分区排序后不断溢写到磁盘文件
3、 MRAppMaster监控到所有maptask进程任务完成之后,会根据客户指定的参数启动相应数量的reducetask进程,并告知reducetask进程要处理的数据范围(数据分区)
4、 Reducetask进程启动之后,根据MRAppMaster告知的待处理数据所在位置,从若干台maptask运行所在机器上获取到若干个maptask输出结果文件,并在本地进行重新归并排序,然后按照相同key的KV为一个组,调用客户定义的reduce()方法进行逻辑运算,并收集运算输出的结果KV,然后调用客户指定的outputformat将结果数据输出到外部存储。
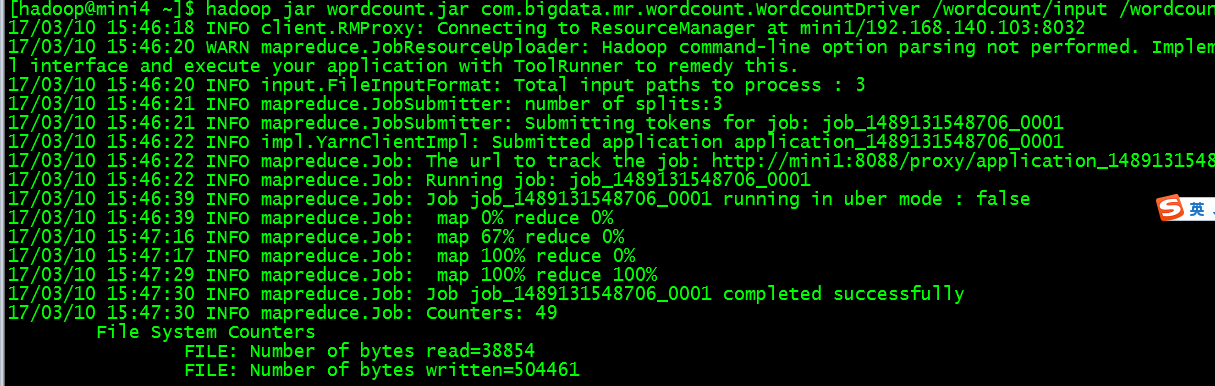
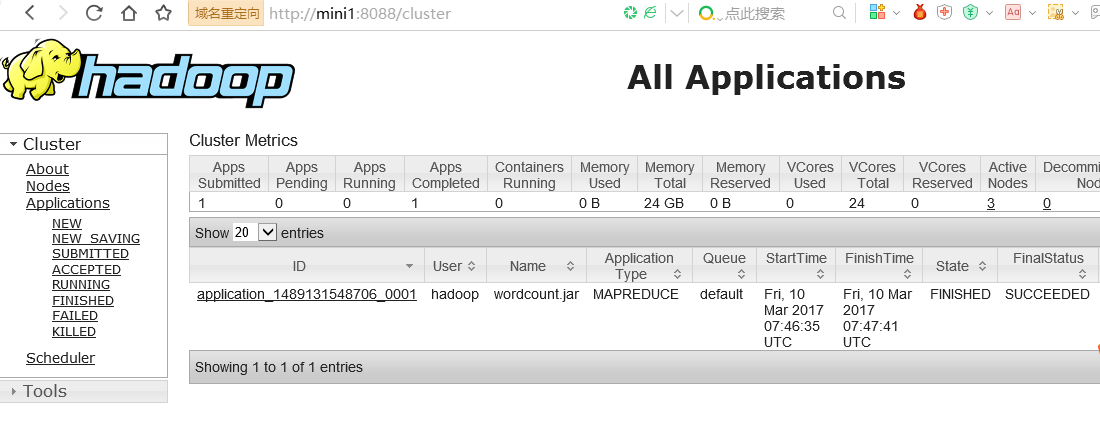
以wordcount程序为例,在hdfs中运行情况截图:

在页面观察到的mapreduce运行情况:















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









