







一、 启动篇
(一) 引子 在spark-shell终端执行
val arr = Array(1,2,3,4) val rdd = sc.makeRDD(arr)
rdd.collect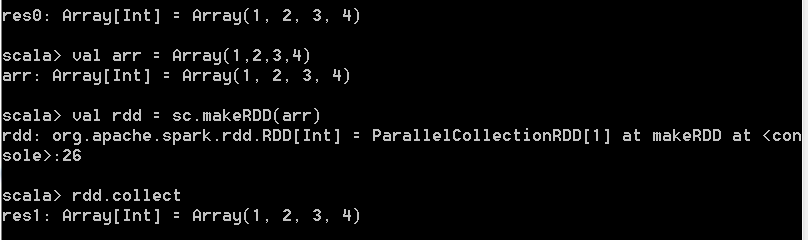
以上3行代码构成了一个完整的spark job执行。
(二) 启动篇
shell模式 shell模式下启动入口:org.apache.spark.repl. Main
shell模式下启动入口:org.apache.spark.repl. Main
submit模式
spark的启动过程就是实例化SparkContext的过程,涉及到driver、和executor端两边
1. SparkSubmit
AppClient
根据shell文件可以得知, spark入口是org.apache.spark.deploy.SparkSubmit,依次打印各类信息,其中最引人注目的是welcome信息
在源码中的体现:
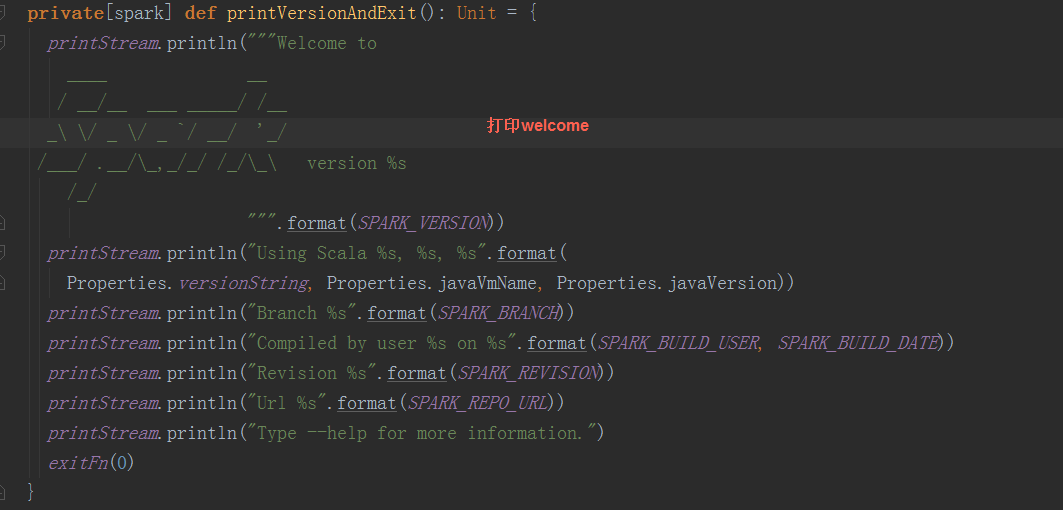 在SparkSubmit中,执行main函数 1.根据外部参数(在我们应用中对应启动sh文件中的参数)构造SparkSubmitArguments
在SparkSubmit中,执行main函数 1.根据外部参数(在我们应用中对应启动sh文件中的参数)构造SparkSubmitArguments
2.调用submit方法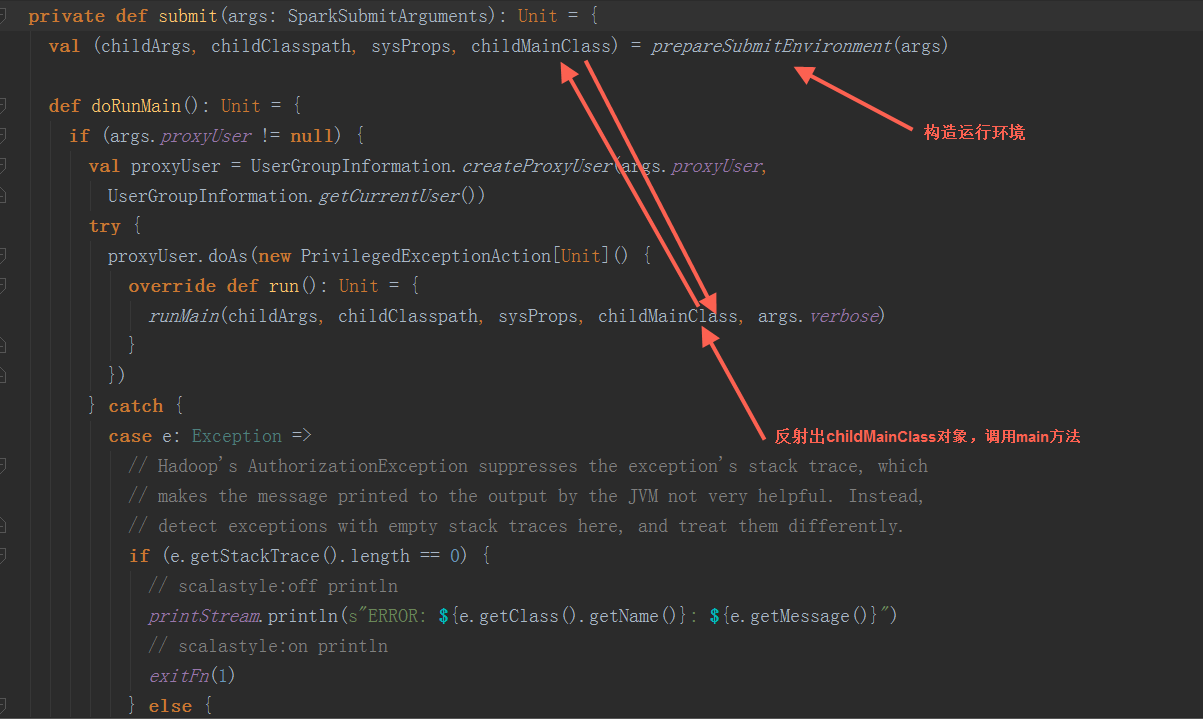 2.1 构造运行环境:
2.1 构造运行环境:
根据步骤1中构造的SparkSubmitArguments对象,确定运行环境,例如master 、deployMode、childMainClass,如果是yarn-cluster,使用org.apache.spark.deploy.yarn.YarnClusterApplication(有的资料上显示是org.apache.spark.deploy.yarn.Client可能是老版本,YarnClusterApplication这个class与org.apache.spark.deploy.yarn.Client在同一个scala文件中)作为childMainClass;如果是mesos-cluster,使用org.apache.spark.deploy.rest.RestSubmissionClient作为childMainClass;如果是standalone模式,使用org.apache.spark.deploy.rest.RestSubmissionClient作为childMainClass
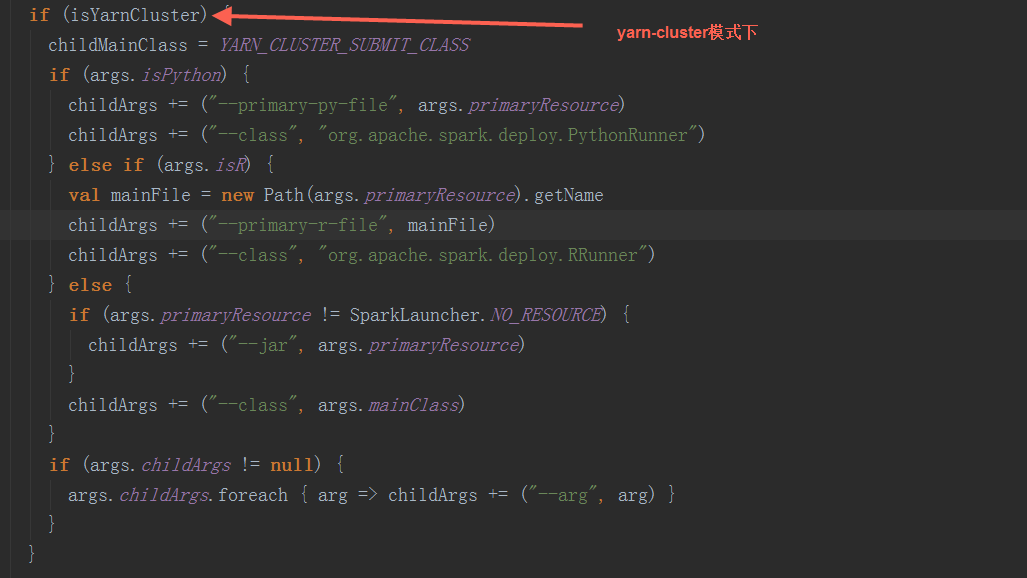 2.2 反射出上一步骤的生成的 childMainClass,调用其main方法
2.2 反射出上一步骤的生成的 childMainClass,调用其main方法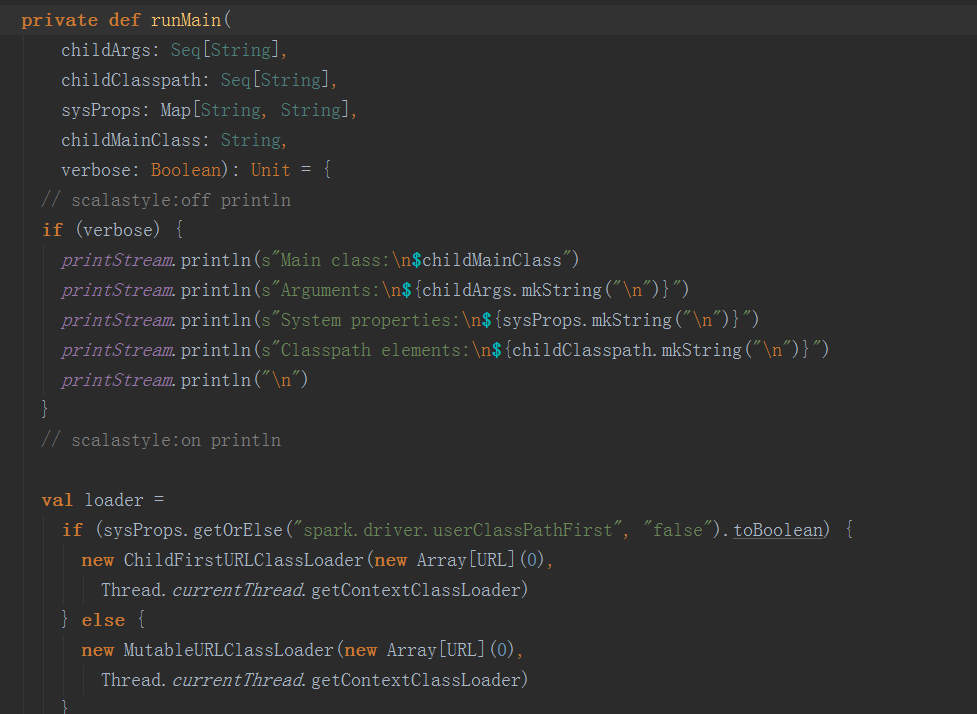
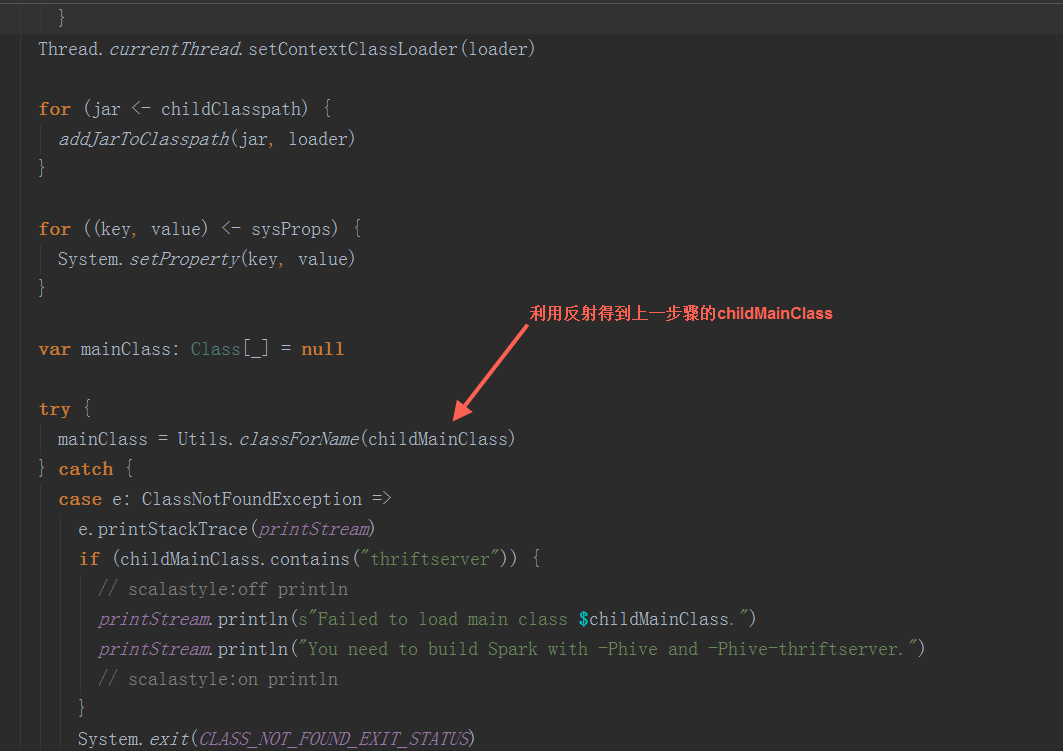
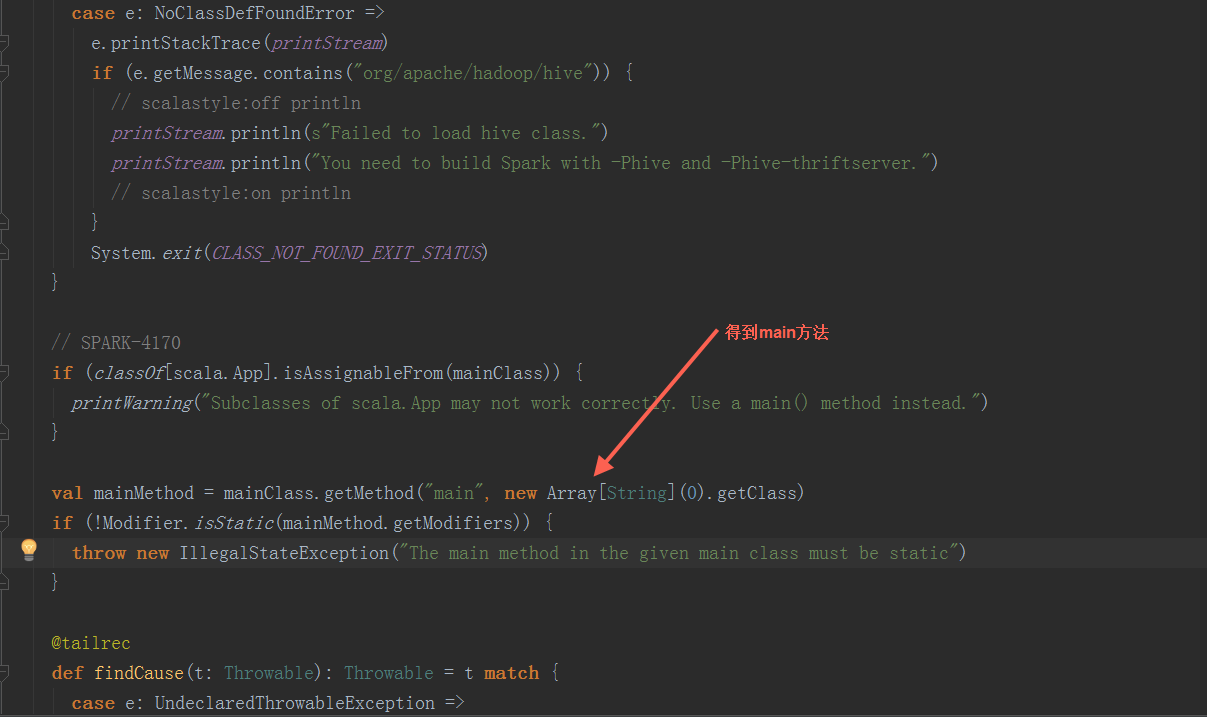
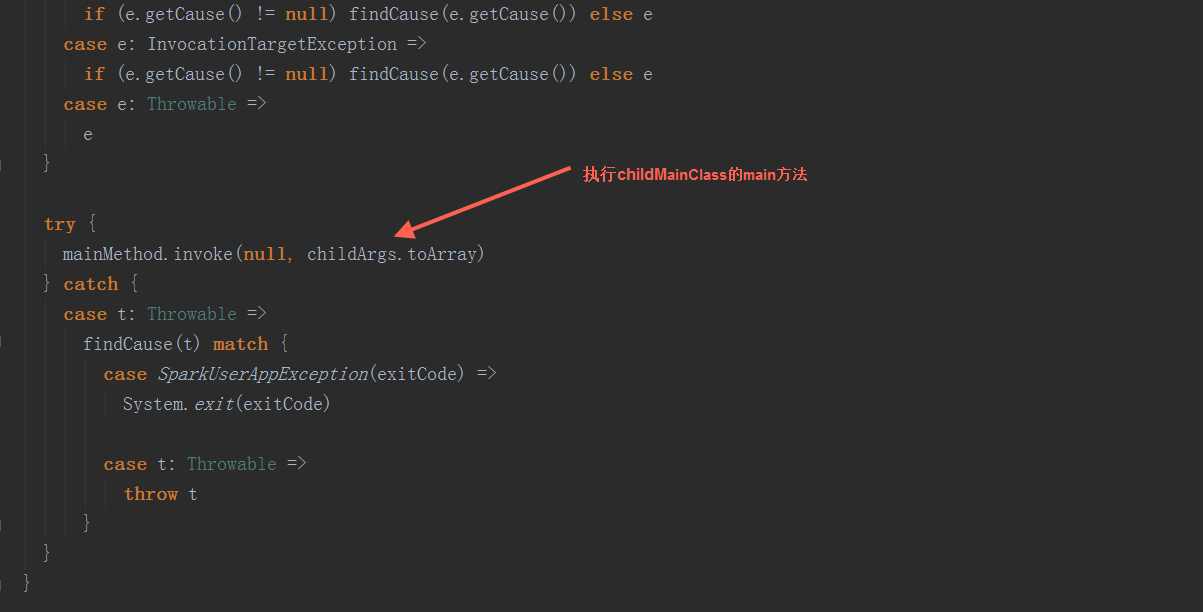 以yarn-cluster模式下,org.apache.spark.deploy.yarn.YarnClusterApplication启动(在spark-yarn这个module里,与org.apache.spark.deploy.yarn.Client在同一个scala文件中)
以yarn-cluster模式下,org.apache.spark.deploy.yarn.YarnClusterApplication启动(在spark-yarn这个module里,与org.apache.spark.deploy.yarn.Client在同一个scala文件中) 
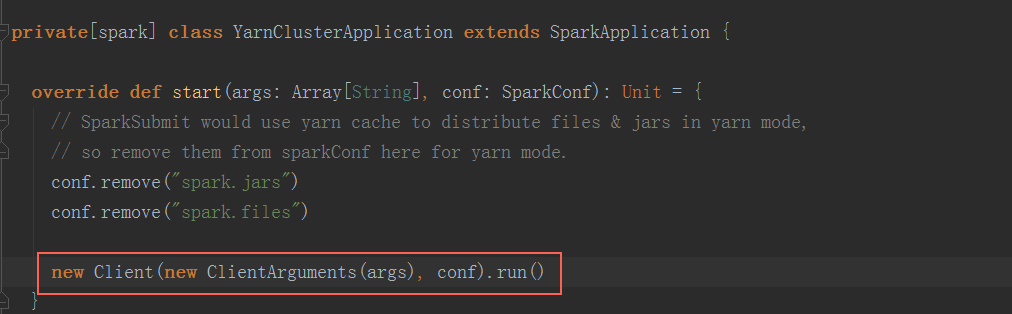 最终调用Client.run()方法:
最终调用Client.run()方法: 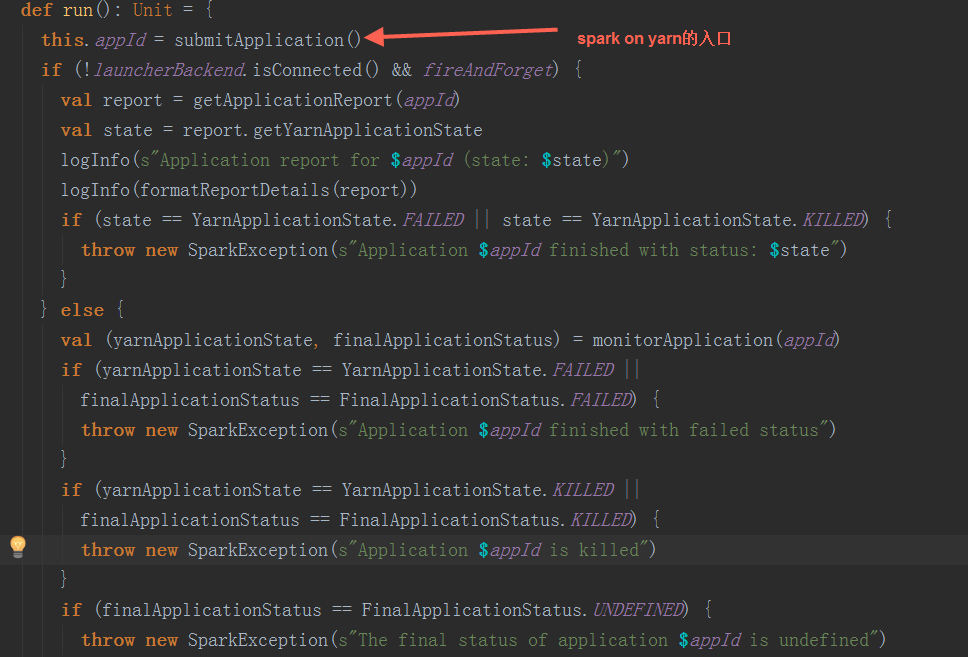 在submitApplication方法中,在经过一些初始化操作后,提交请求到ResouceManager,检查集群的内存情况,检验集群的内存等资源是否满足当前的作业需求,最后正式提交application
在submitApplication方法中,在经过一些初始化操作后,提交请求到ResouceManager,检查集群的内存情况,检验集群的内存等资源是否满足当前的作业需求,最后正式提交application 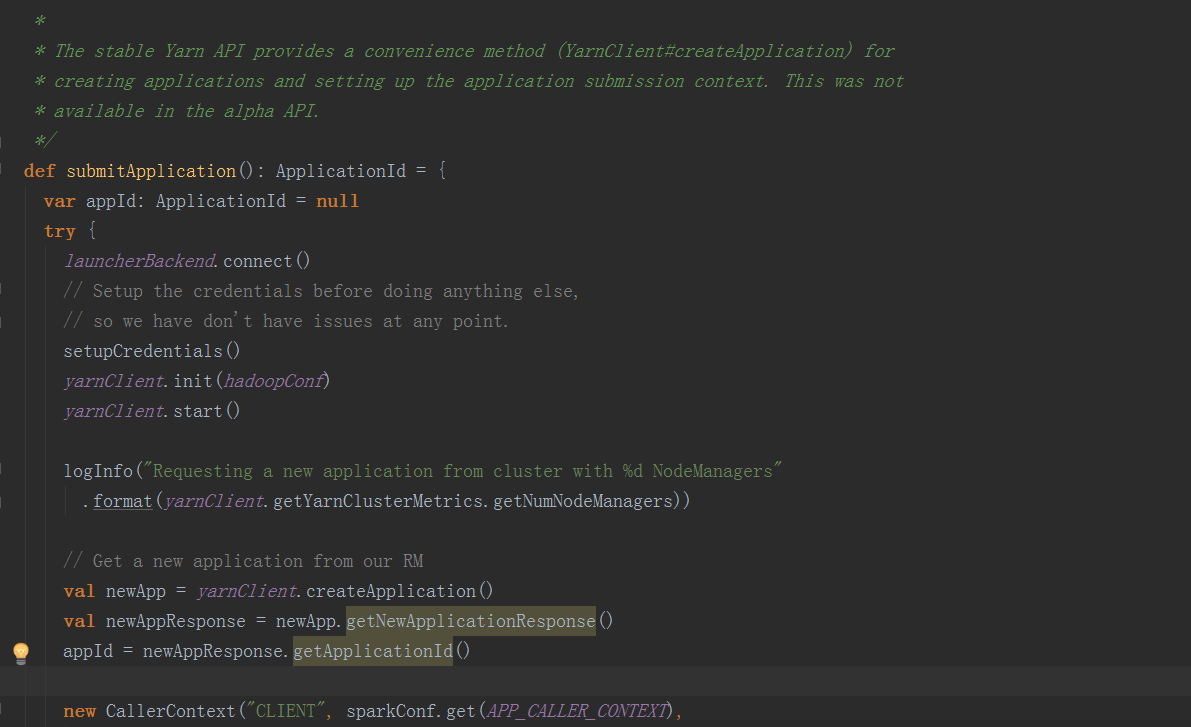
 在createContainerLaunchContext方法中,用反射创建ApplicationMaster,负责运行Spark Application的Driver程序,并分配执行需要的Executors。
在createContainerLaunchContext方法中,用反射创建ApplicationMaster,负责运行Spark Application的Driver程序,并分配执行需要的Executors。 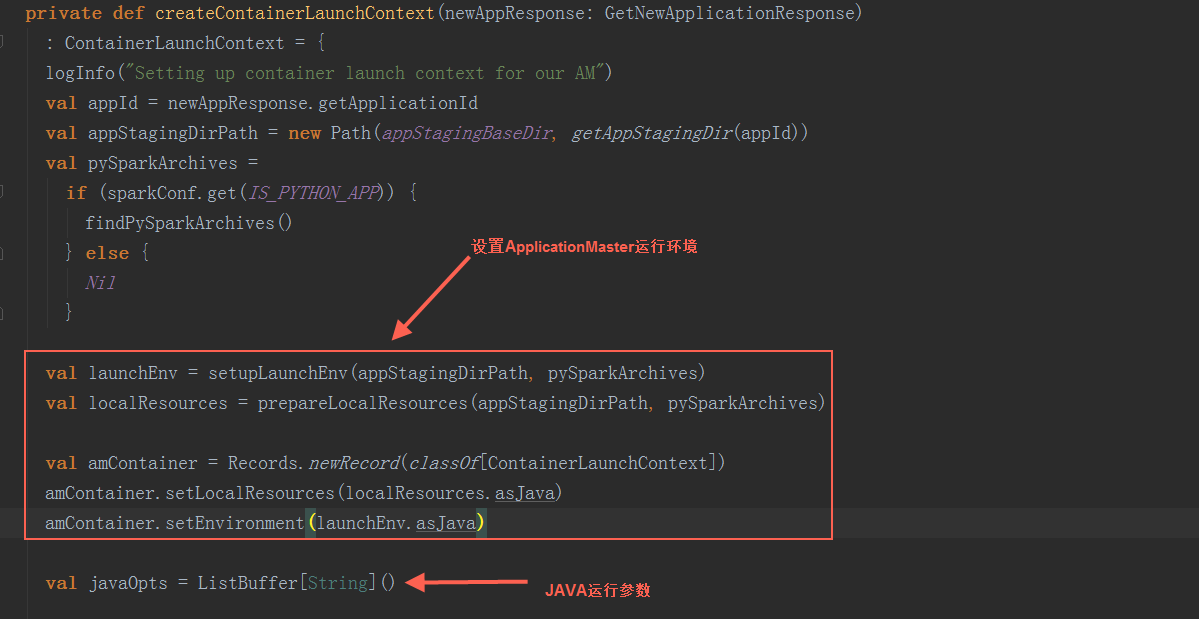
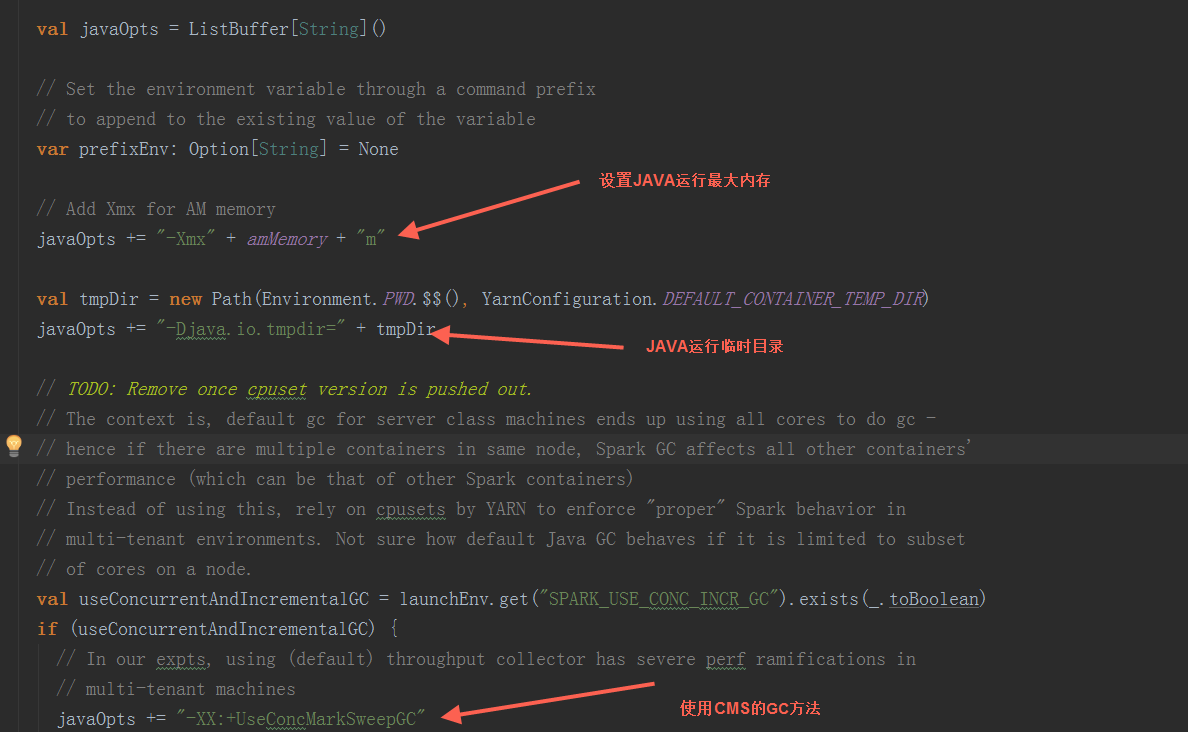
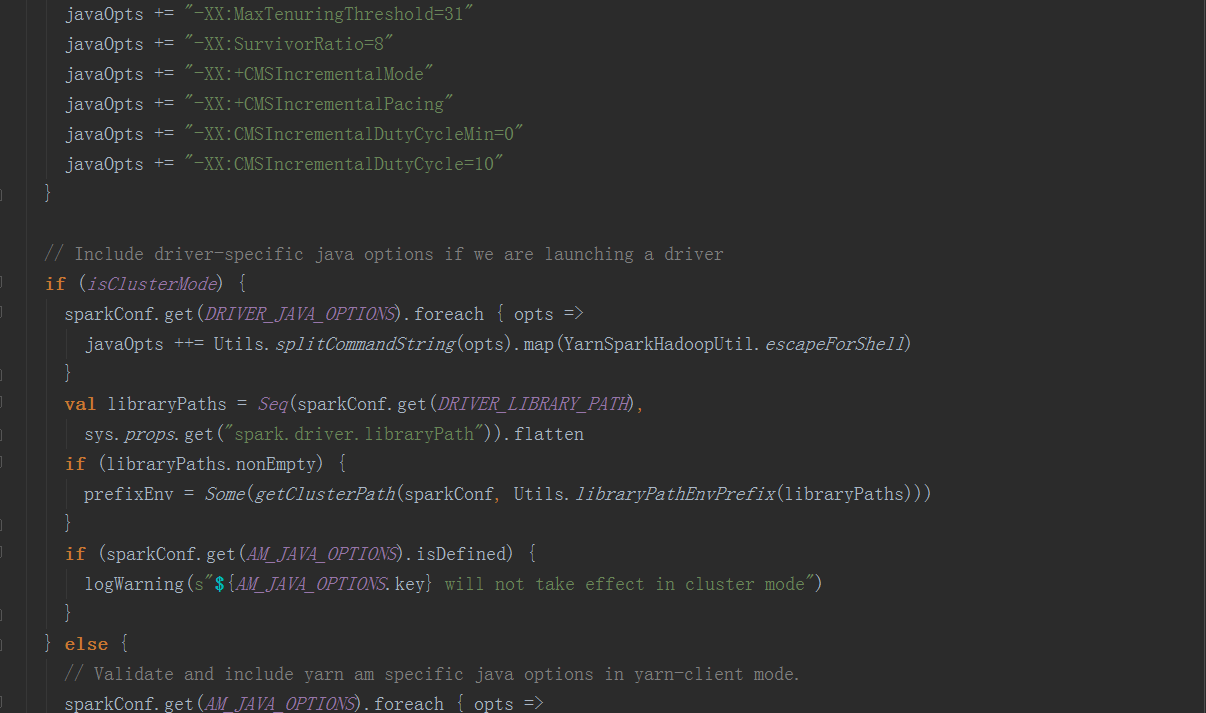
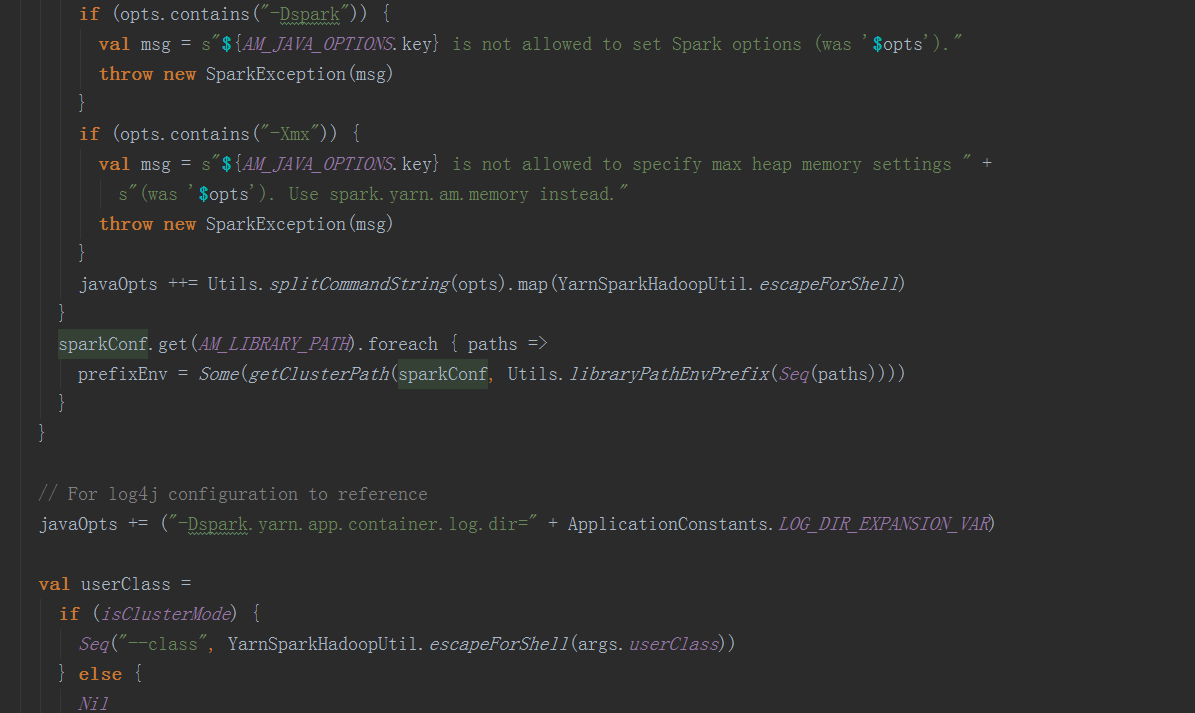
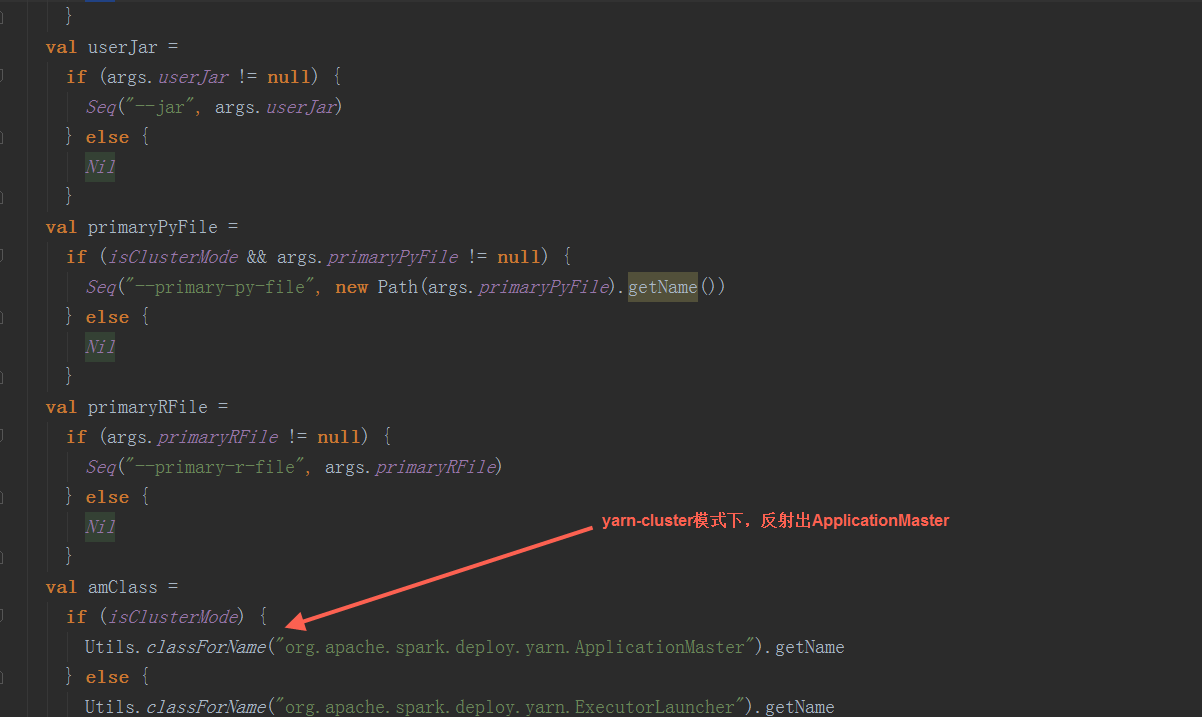
 在ApplicationMaster中,其run方法中调用runImpl,如果是集群模式,调用runDriver启动driver端和executor端
在ApplicationMaster中,其run方法中调用runImpl,如果是集群模式,调用runDriver启动driver端和executor端 

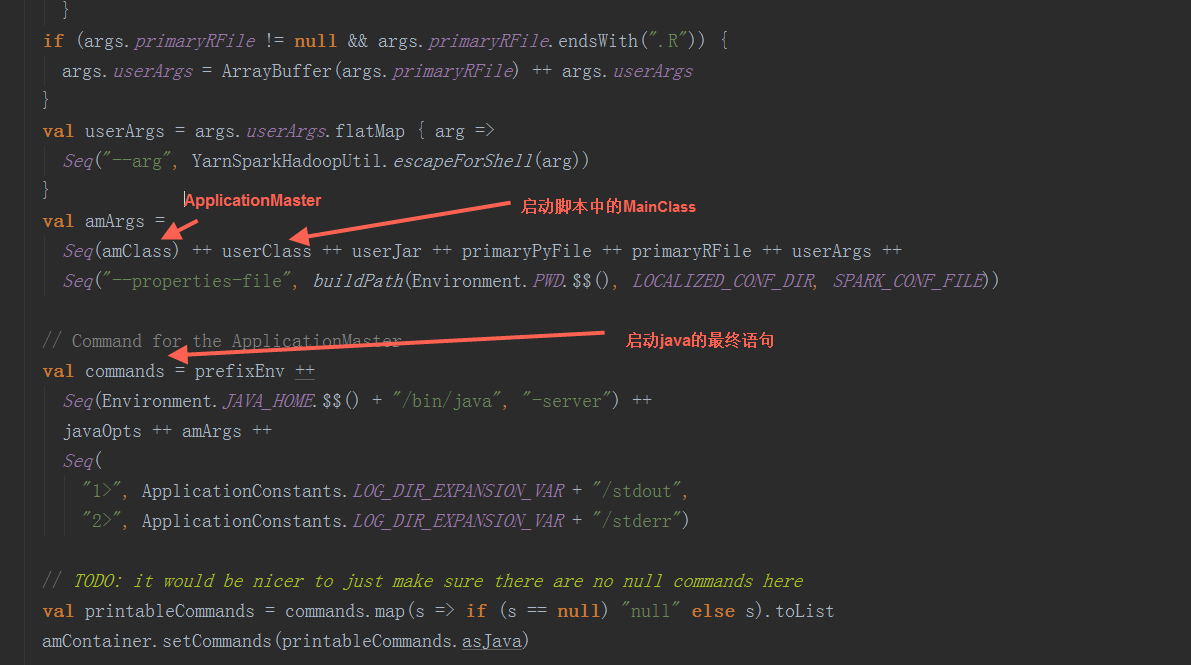
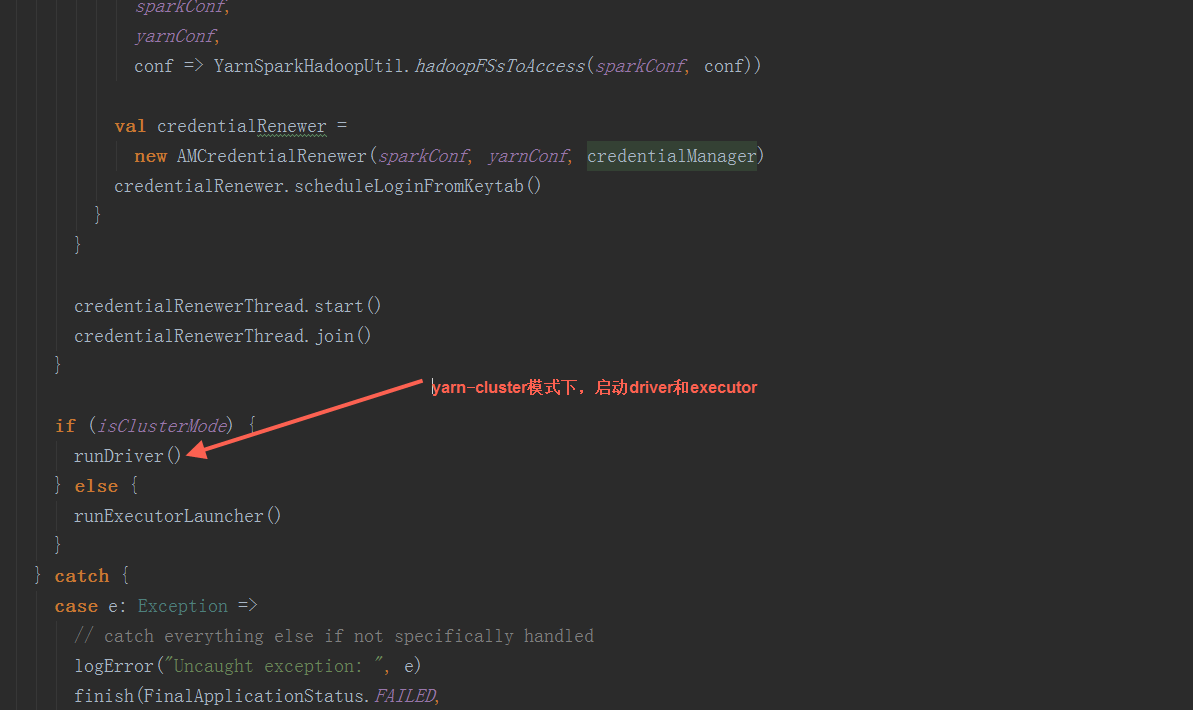 在runDriver方法中,调用startUserApplication方法,创建一个线程,用反射构造出启动脚本中的MainClass,并在线程中执行其main方法。调用registerAM方法,注册driver到yarn集群,并为executor分配资源并启动。
在runDriver方法中,调用startUserApplication方法,创建一个线程,用反射构造出启动脚本中的MainClass,并在线程中执行其main方法。调用registerAM方法,注册driver到yarn集群,并为executor分配资源并启动。 
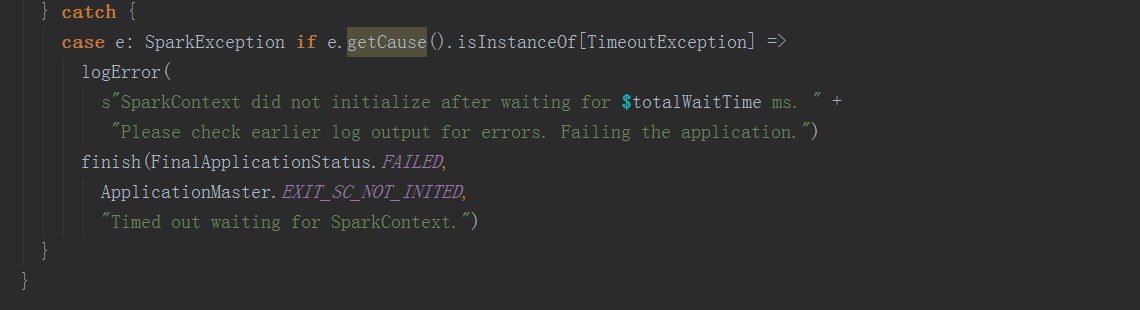 在startUserApplication方法中,
在startUserApplication方法中, 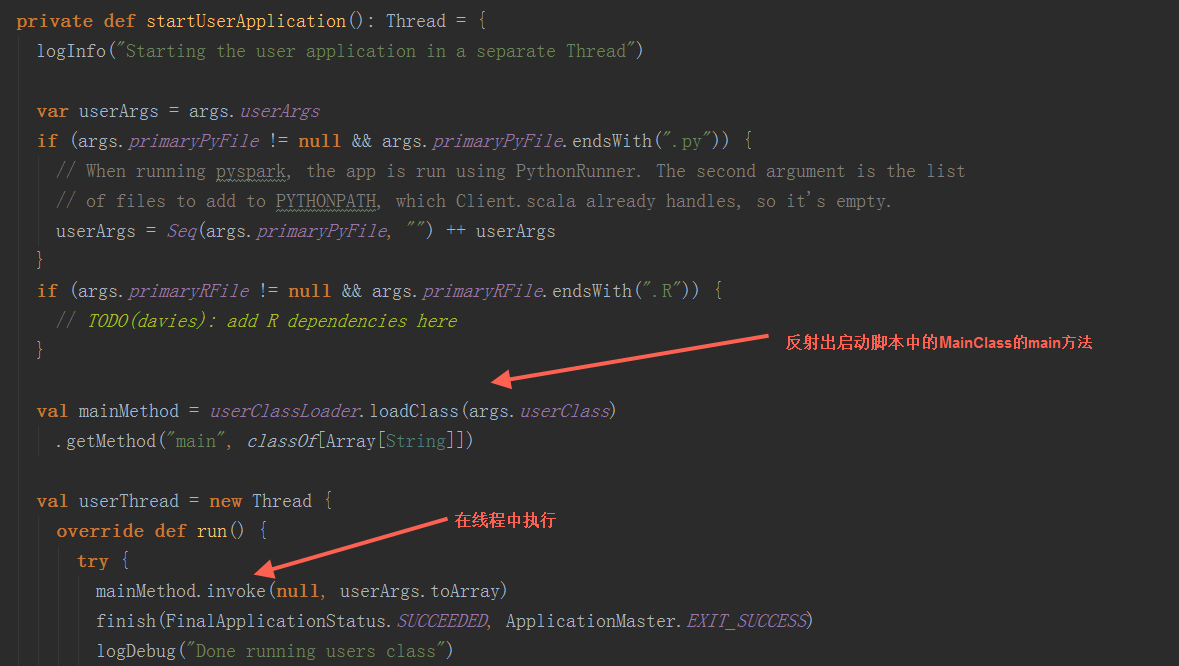

 userClassThread.join通过运行startUserApplication方法返回的线程启动Driver
userClassThread.join通过运行startUserApplication方法返回的线程启动Driver
在其run方法中,通过反射执行userClass中的main方法启动Driver。
- Driver篇
 Spark会将Driver中的任务提交给Executor中,具体的计算是发生在Executor上,调用线程,在线程池用运行计算,每个任务都会有独立的Executor计算。
Spark会将Driver中的任务提交给Executor中,具体的计算是发生在Executor上,调用线程,在线程池用运行计算,每个任务都会有独立的Executor计算。
1) SparkContext
在Driver端SparkContext初始化中, 调用createTaskScheduler方法创建SchedulerBackend和TaskScheduler,实例化DAGScheduler,然后调用TaskScheduler.start方法启动TaskScheduler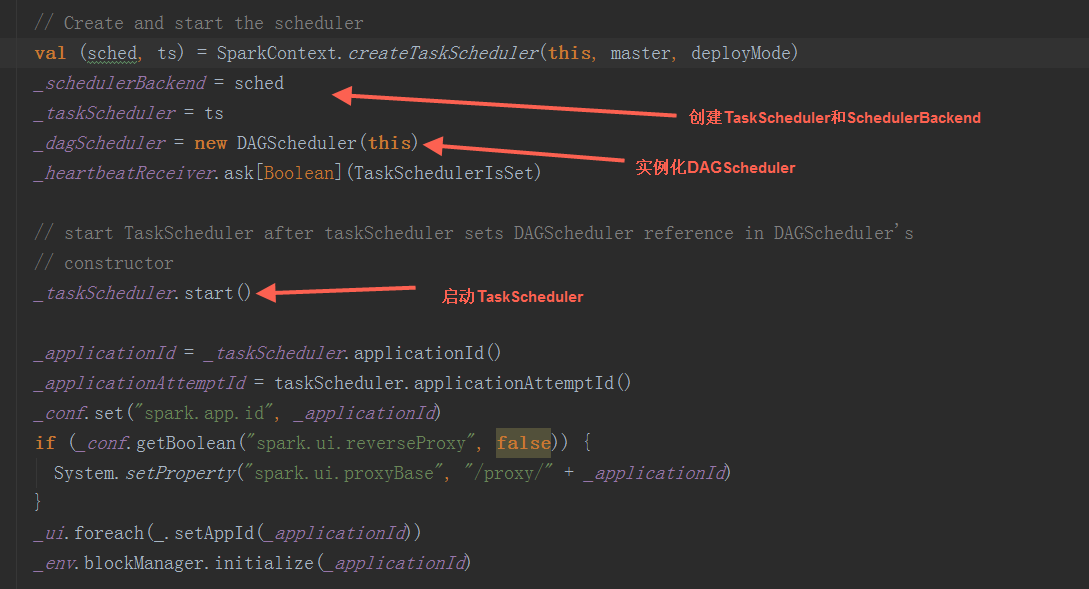 Sparn On Yarn模式下,SchedulerBackend和TaskScheduler通过ClassLoader初始化YarnschedulerBackend和YARTaskscheduler。
Sparn On Yarn模式下,SchedulerBackend和TaskScheduler通过ClassLoader初始化YarnschedulerBackend和YARTaskscheduler。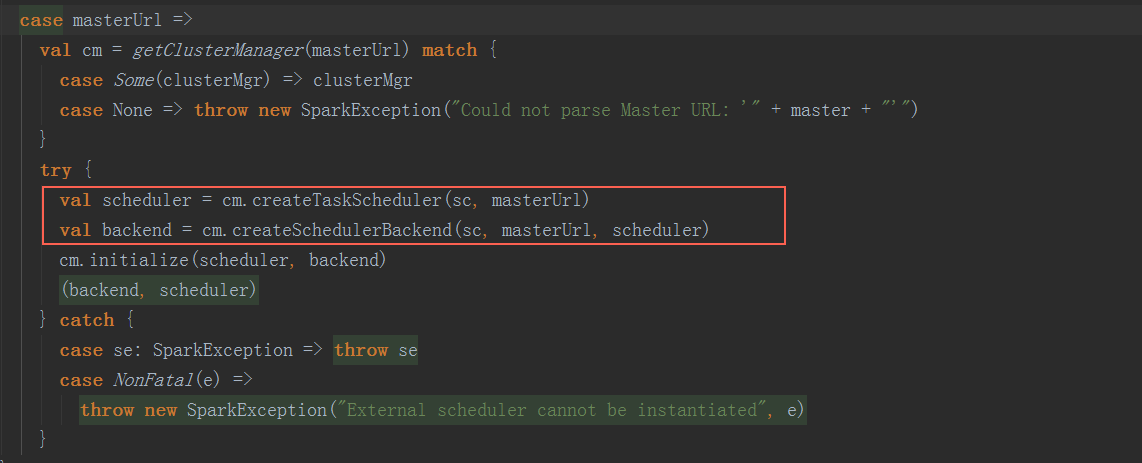 在getClusterManager方法中,返回ExternalClusterManager类型,在Sparn On Yarn模式下,为org.apache.spark.scheduler.cluster.YarnClusterManager的实例,在YarnClusterManager. createTaskScheduler和YarnClusterManager. createSchedulerBackend方法中,返回YarnTaskscheduler和YarnschedulerBackend。根据是deployMode为cluster或client分别返回。
在getClusterManager方法中,返回ExternalClusterManager类型,在Sparn On Yarn模式下,为org.apache.spark.scheduler.cluster.YarnClusterManager的实例,在YarnClusterManager. createTaskScheduler和YarnClusterManager. createSchedulerBackend方法中,返回YarnTaskscheduler和YarnschedulerBackend。根据是deployMode为cluster或client分别返回。  2) SparkEnv
2) SparkEnv
3) DagScheduler
4) TaskSchedler
5) SchedlerBackend - Executor篇
在registerAM方法中,调用YarnRMClien.register方法把ApplicationMaster注册到yarn并返回YarnAllocator对象,最后调用YarnAllocator.allocateResources方法来构造executor并启动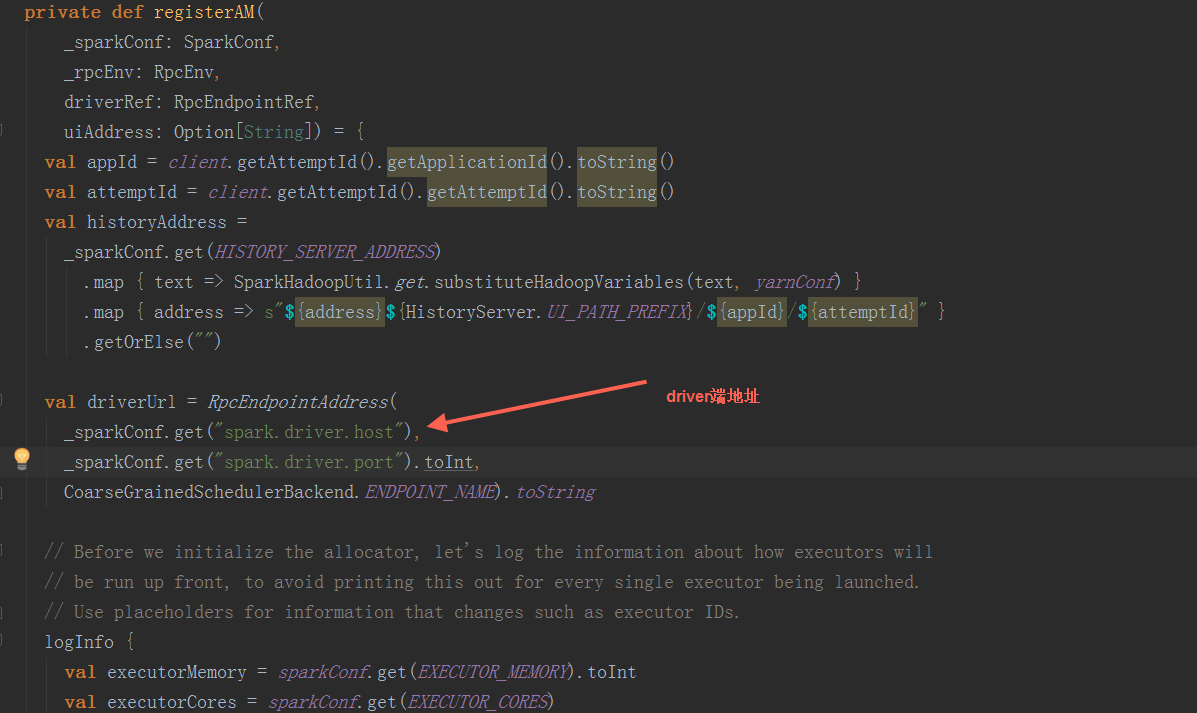
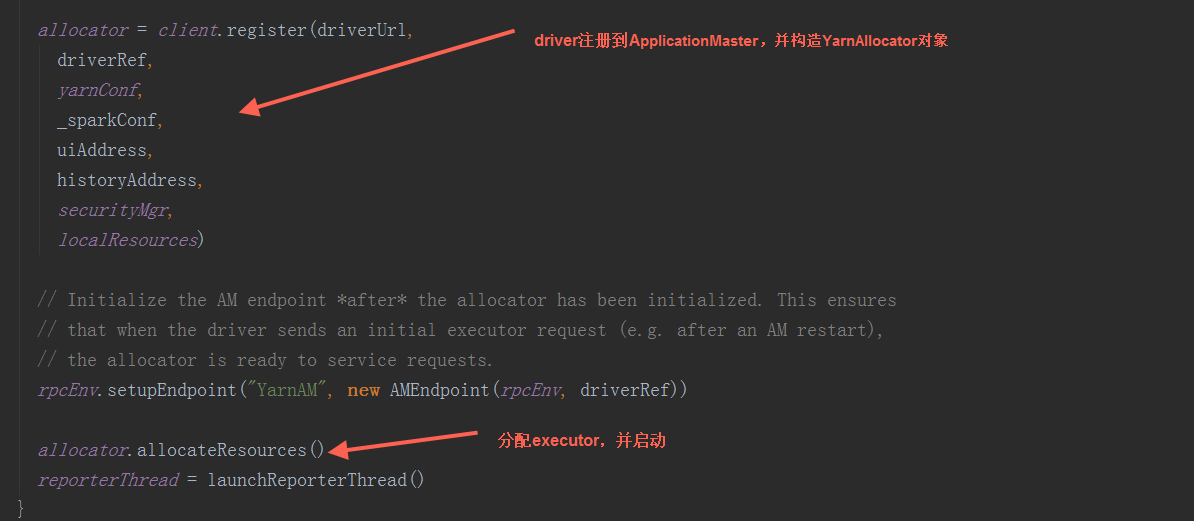
 在YarnRMClien.register方法中,把ApplicationMaster注册到yarn集群,构造YarnAllocator对象
在YarnRMClien.register方法中,把ApplicationMaster注册到yarn集群,构造YarnAllocator对象 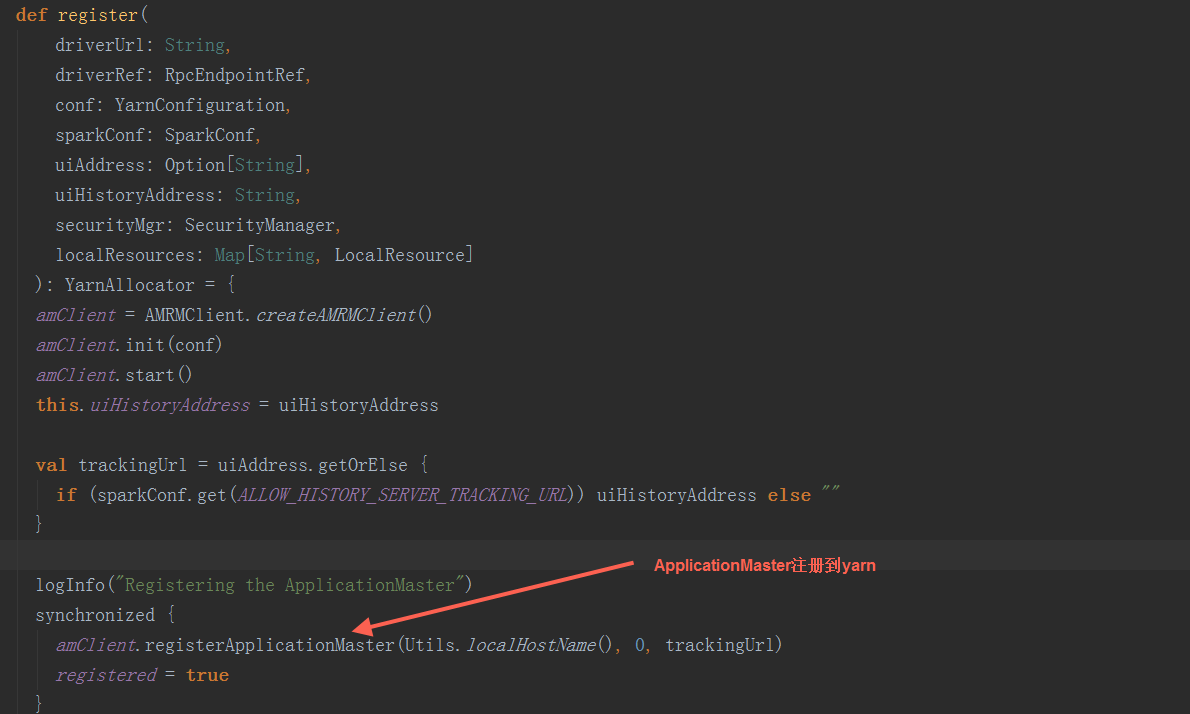
 在YarnAllocator.allocateResources方法中,先获取到可用Container(Container作为executor启动容器的抽象,Resource作为启动资源的抽象,主要包括memory和virtualCores_即内存与cpu核数,Container持有Resource的引用)来构造executor并启动资源,调用handleAllocatedContainers方法,根据同节点本地>ack本地>随机的顺序来确定本次分配的Container,最后调用runAllocatedContainers方法启动executor。
在YarnAllocator.allocateResources方法中,先获取到可用Container(Container作为executor启动容器的抽象,Resource作为启动资源的抽象,主要包括memory和virtualCores_即内存与cpu核数,Container持有Resource的引用)来构造executor并启动资源,调用handleAllocatedContainers方法,根据同节点本地>ack本地>随机的顺序来确定本次分配的Container,最后调用runAllocatedContainers方法启动executor。 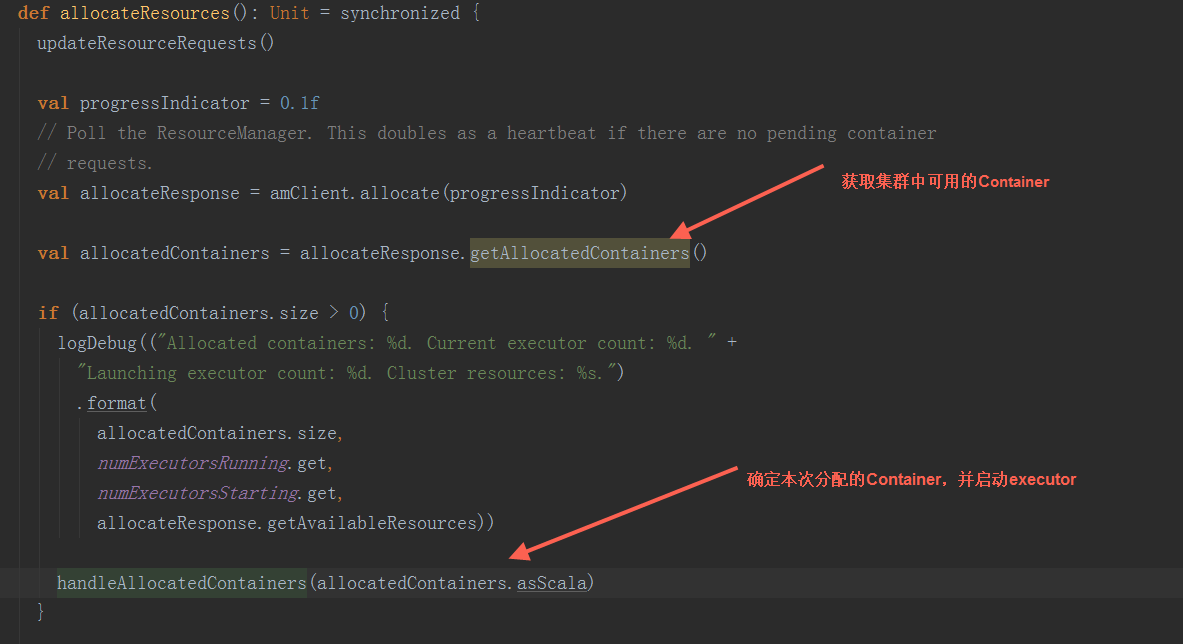
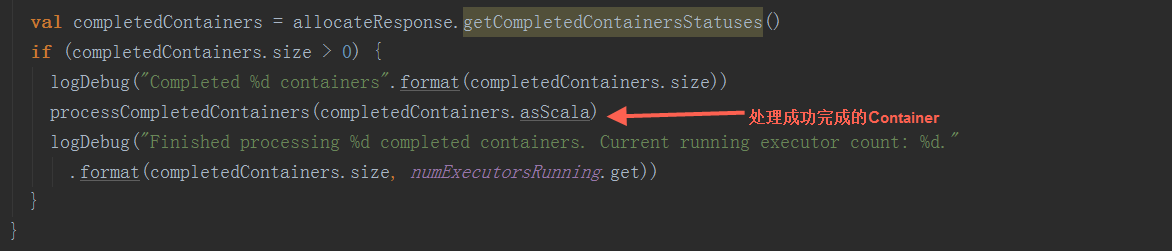 在handleAllocatedContainers方法,根据同节点数据本地>机架本地>随机的顺序来确定本次分配的Container
在handleAllocatedContainers方法,根据同节点数据本地>机架本地>随机的顺序来确定本次分配的Container 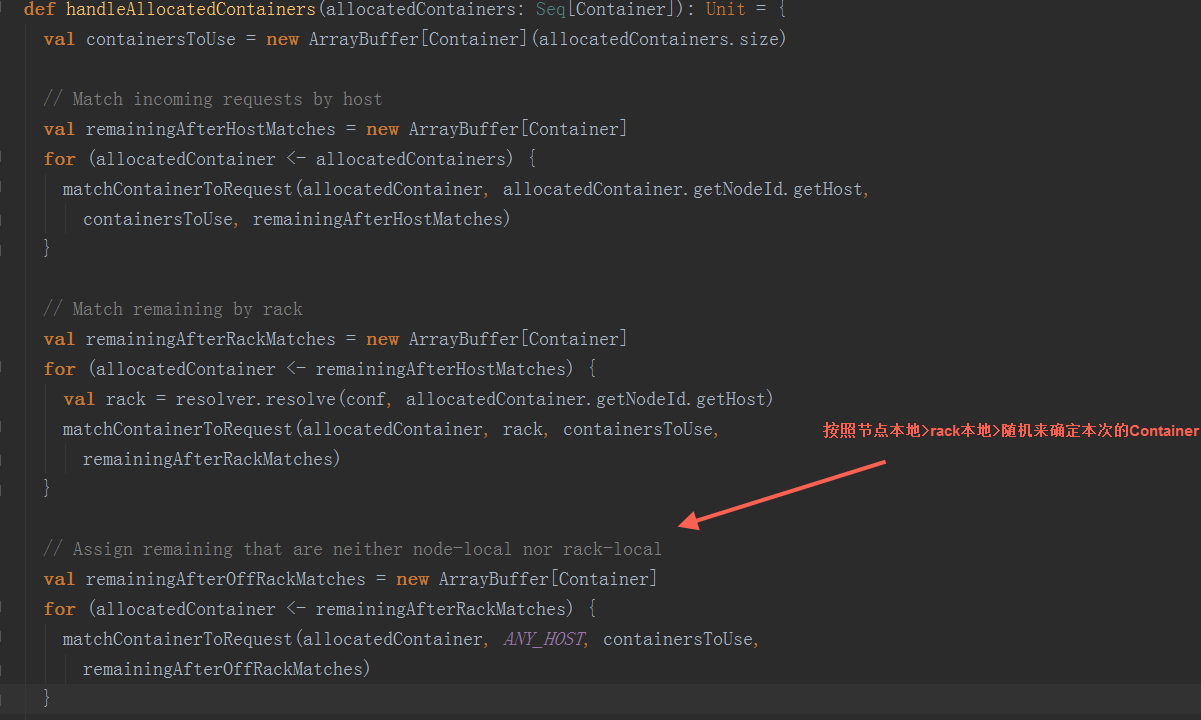
 在runAllocatedContainers方法中,构造ExecutorRunnable对象,并在线程中调用其run方法,启动executor
在runAllocatedContainers方法中,构造ExecutorRunnable对象,并在线程中调用其run方法,启动executor 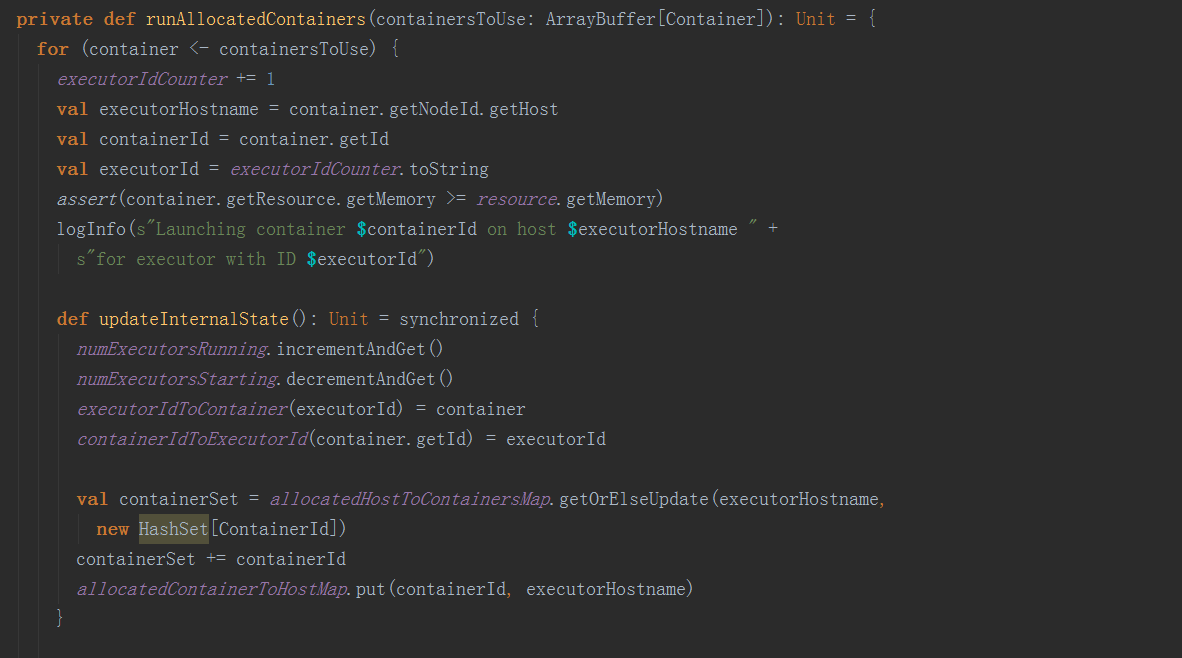
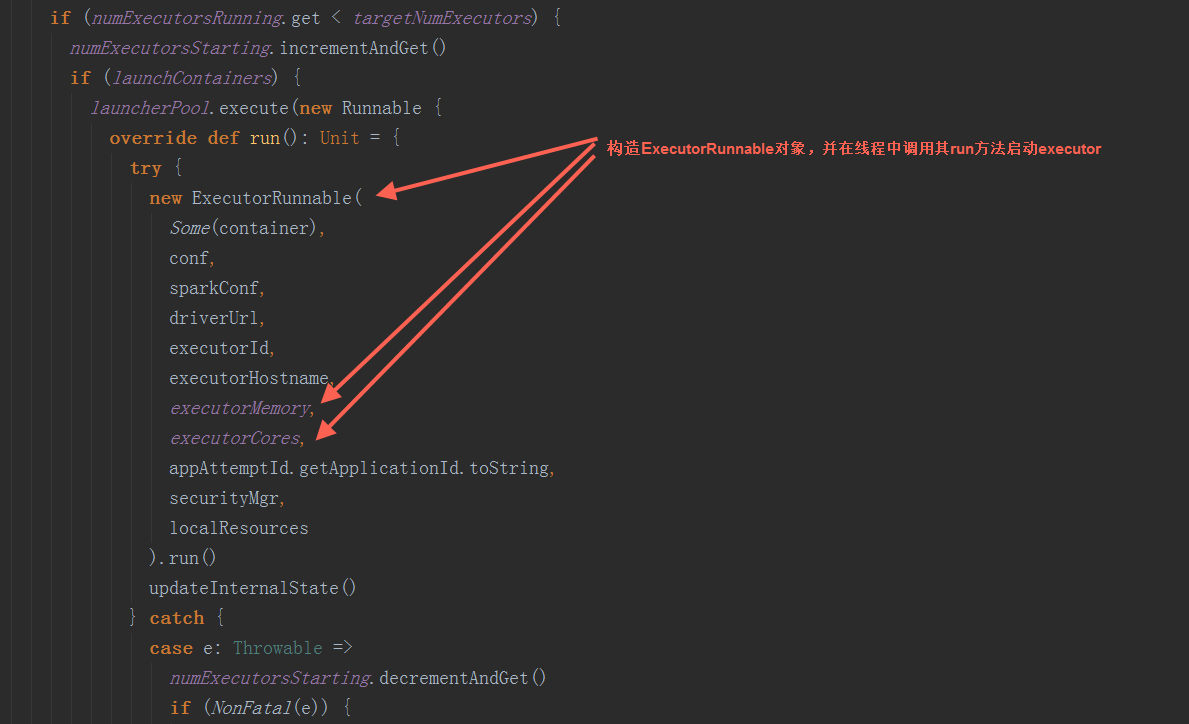
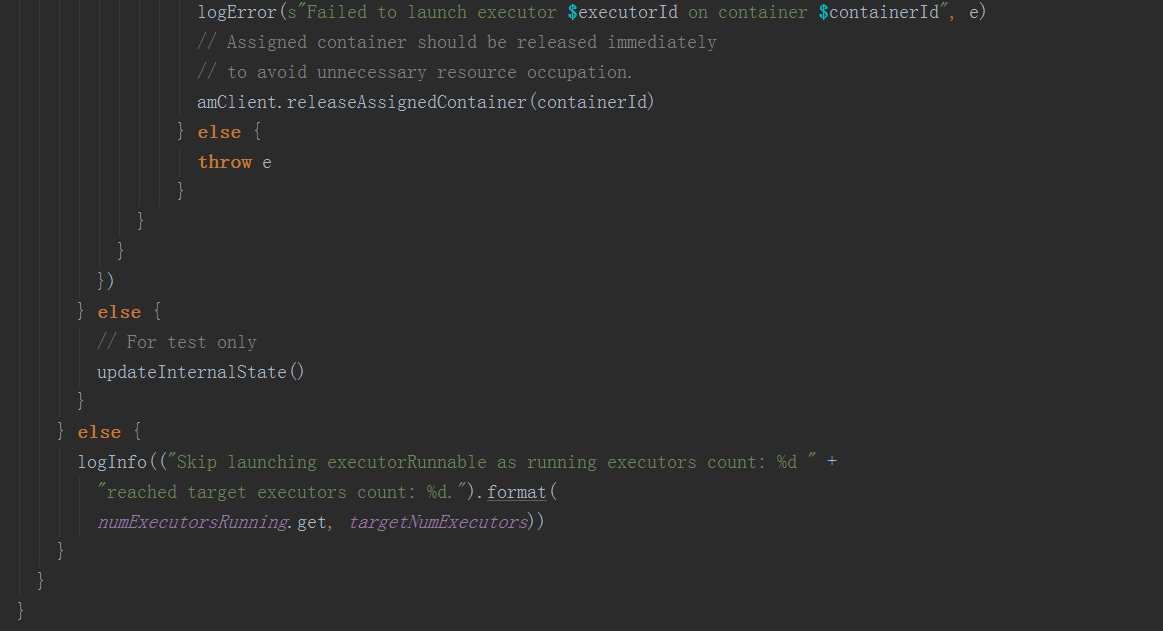 在ExecutorRunnable.run方法中,调用startContainer方法启动executor
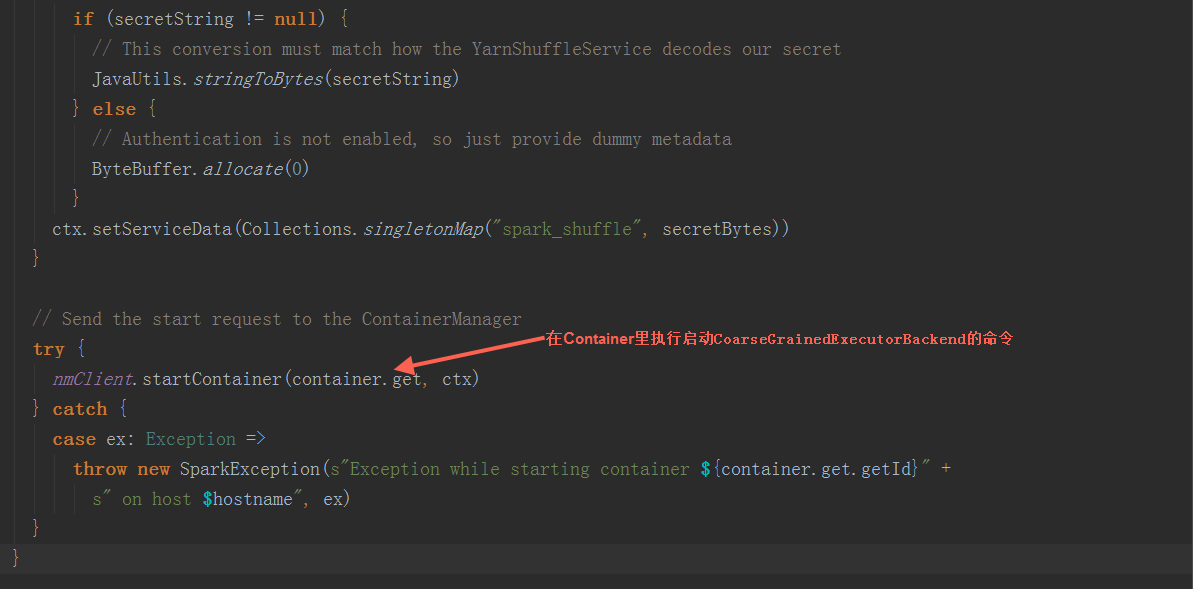
在ExecutorRunnable.run方法中,调用startContainer方法启动executor  在startContainer方法中,调用prepareCommand方法,设置JVM参数后,构造启动命令,发送到yarn中启动CoarseGrainedExecutorBackend进程。
在startContainer方法中,调用prepareCommand方法,设置JVM参数后,构造启动命令,发送到yarn中启动CoarseGrainedExecutorBackend进程。 
 在prepareCommand方法中,设置JVM参数后,构造启动命令
在prepareCommand方法中,设置JVM参数后,构造启动命令 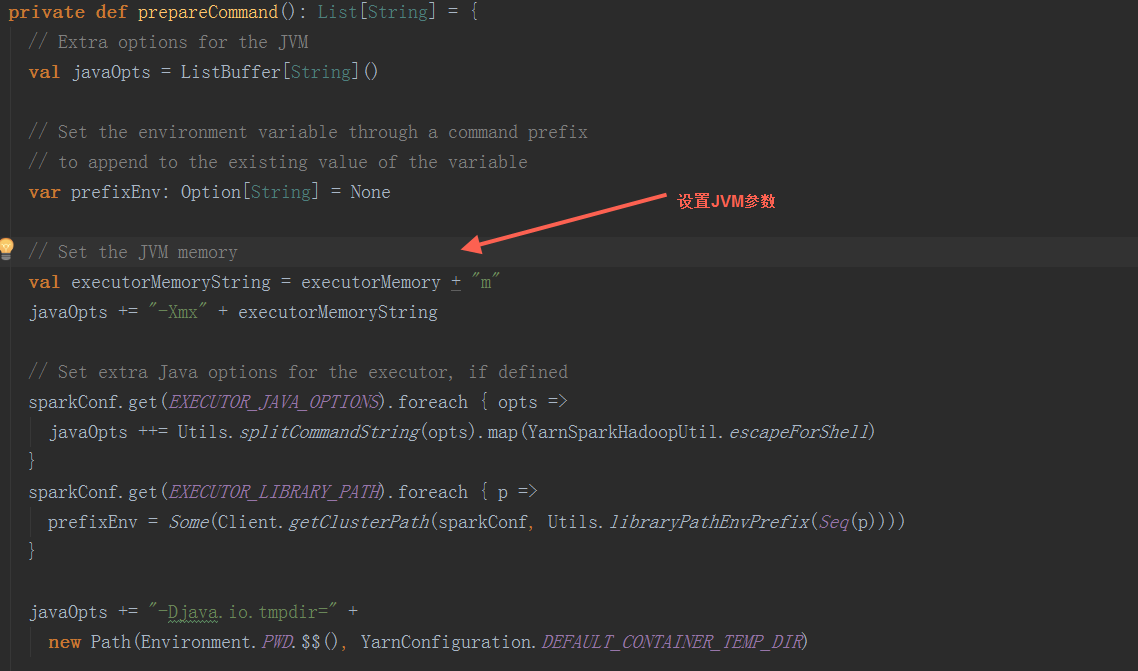
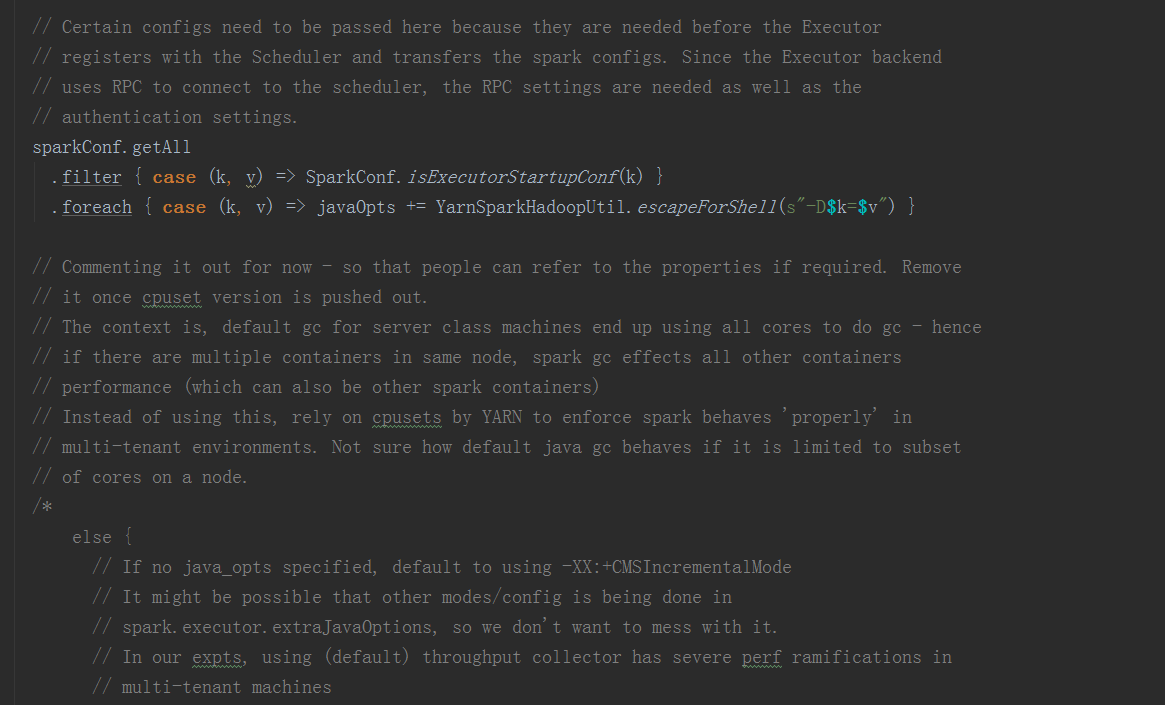
 在org.apache.spark.executor.CoarseGrainedExecutorBackend类中,在其main方法中,先构造参数后,调用run方法进入启动注册ExecutorBackend:
在org.apache.spark.executor.CoarseGrainedExecutorBackend类中,在其main方法中,先构造参数后,调用run方法进入启动注册ExecutorBackend: 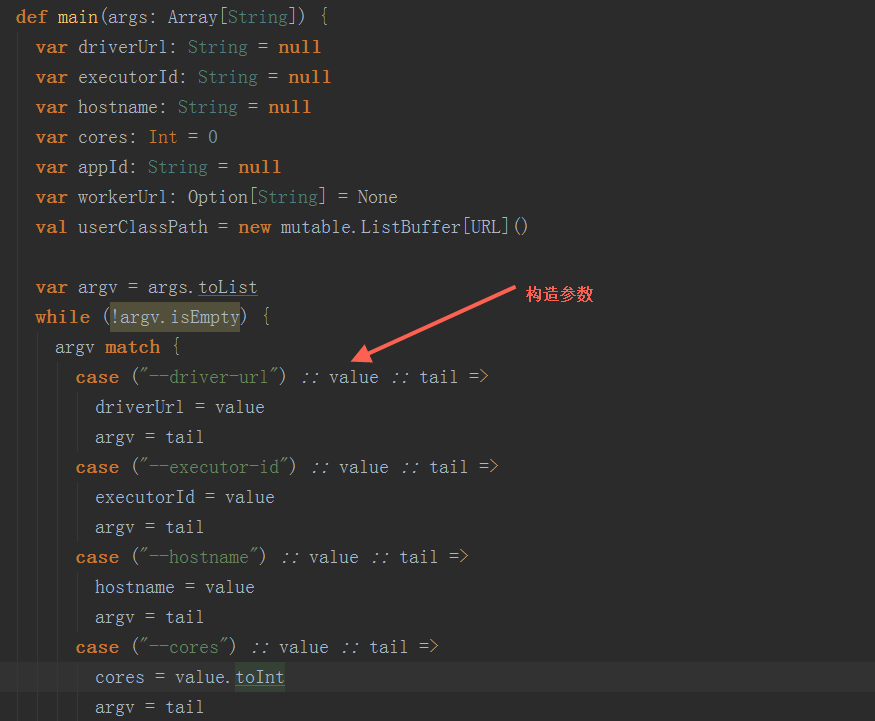
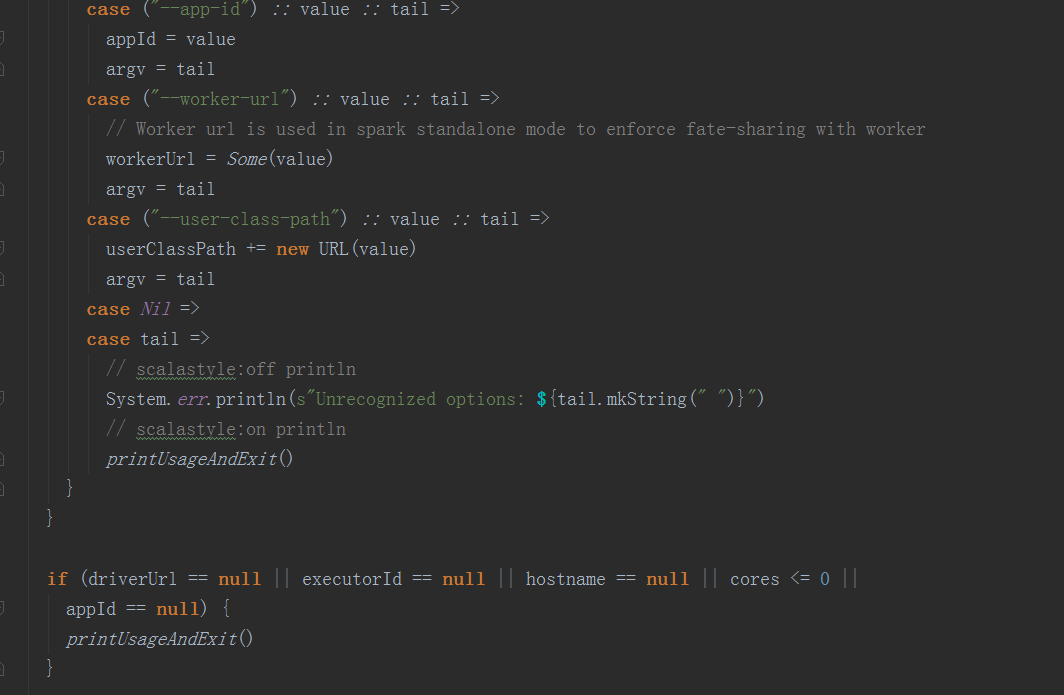
 在run方法中,调用SparkEnv.createExecutorEnv方法创建SprkEnv对象,并把当前ExcutorBackend注册到Driver,因为CoarseGrainedExecutorBackend是一个消息体,注册后会自动调用其onStart方法
在run方法中,调用SparkEnv.createExecutorEnv方法创建SprkEnv对象,并把当前ExcutorBackend注册到Driver,因为CoarseGrainedExecutorBackend是一个消息体,注册后会自动调用其onStart方法 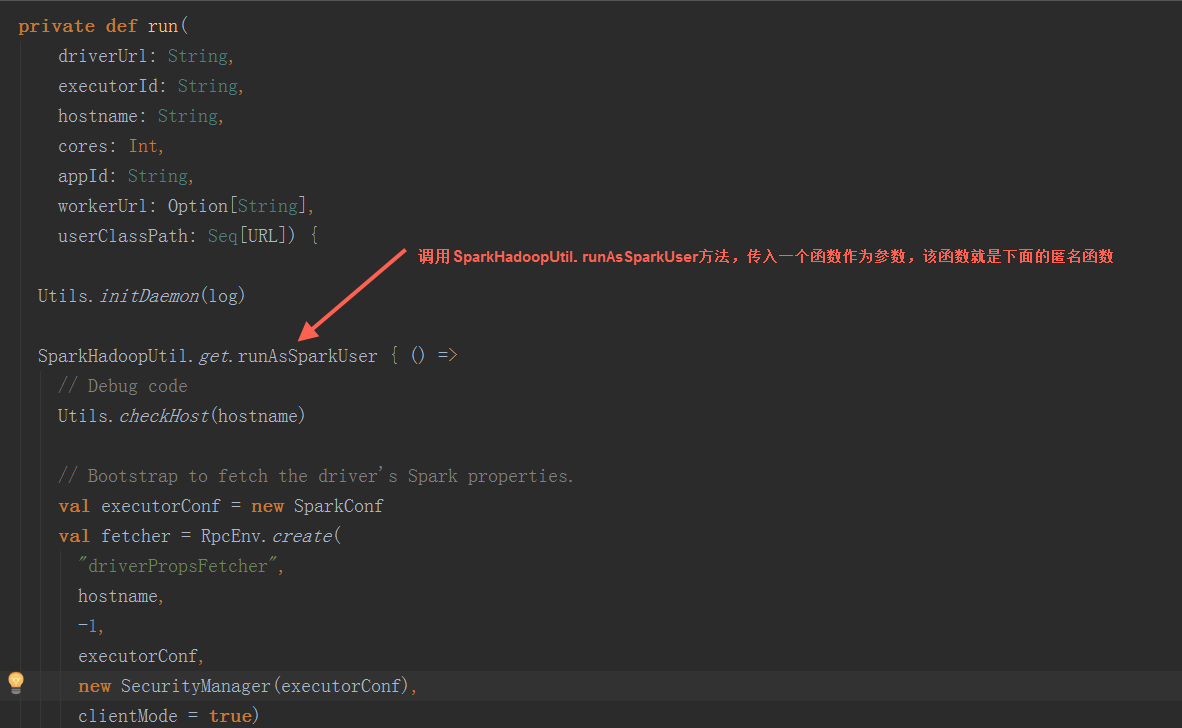

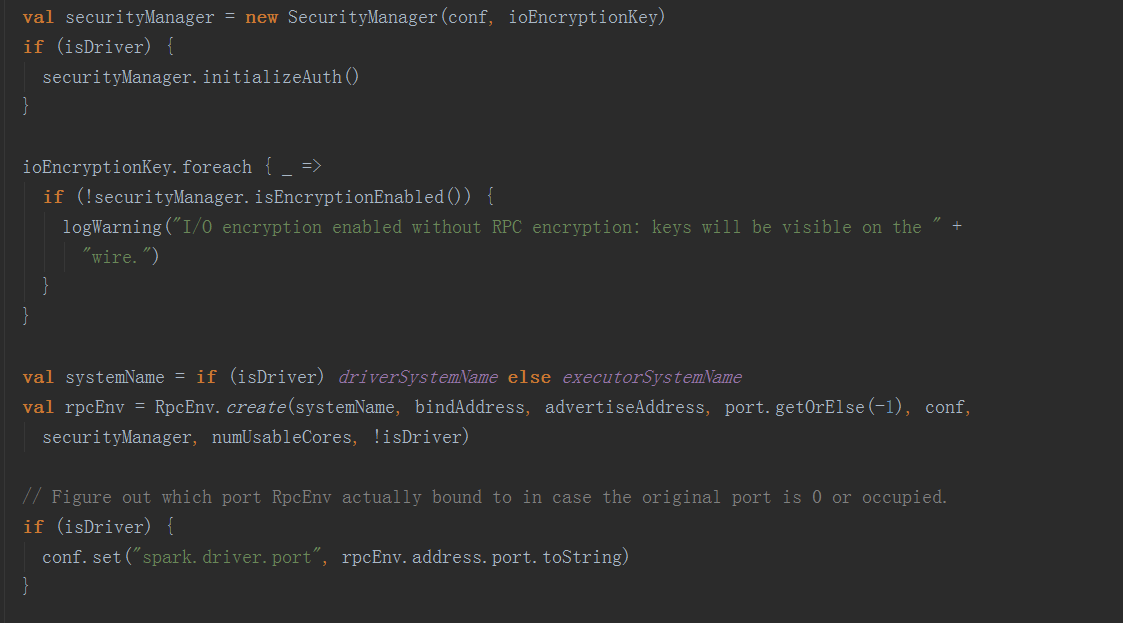
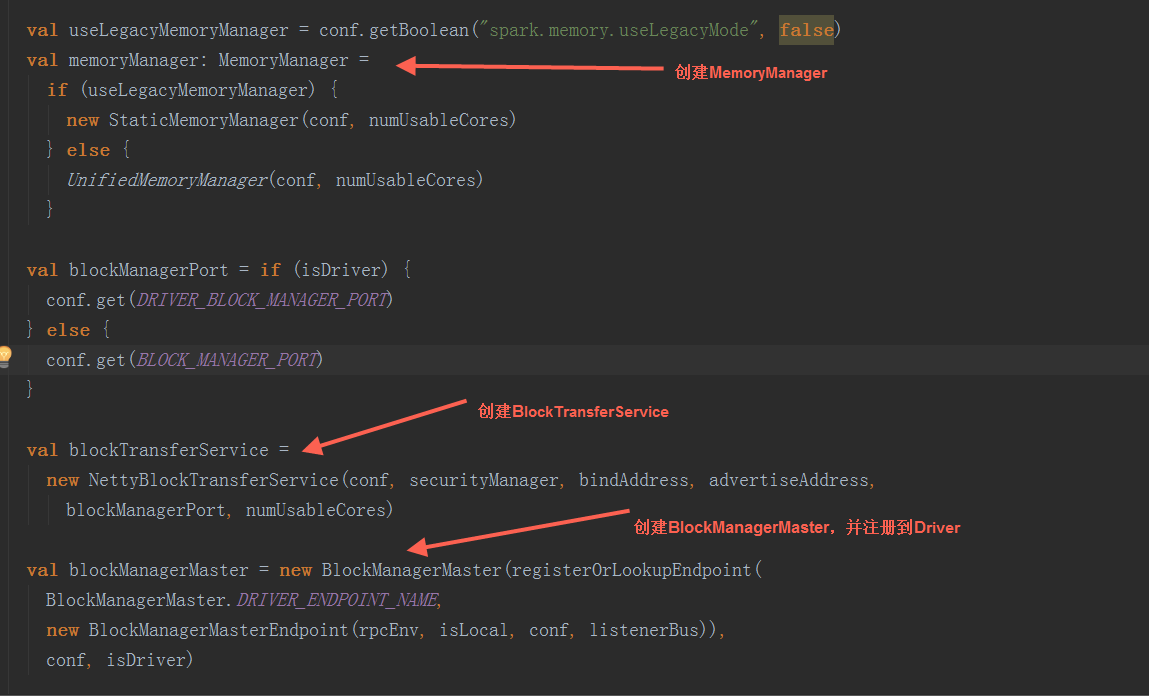
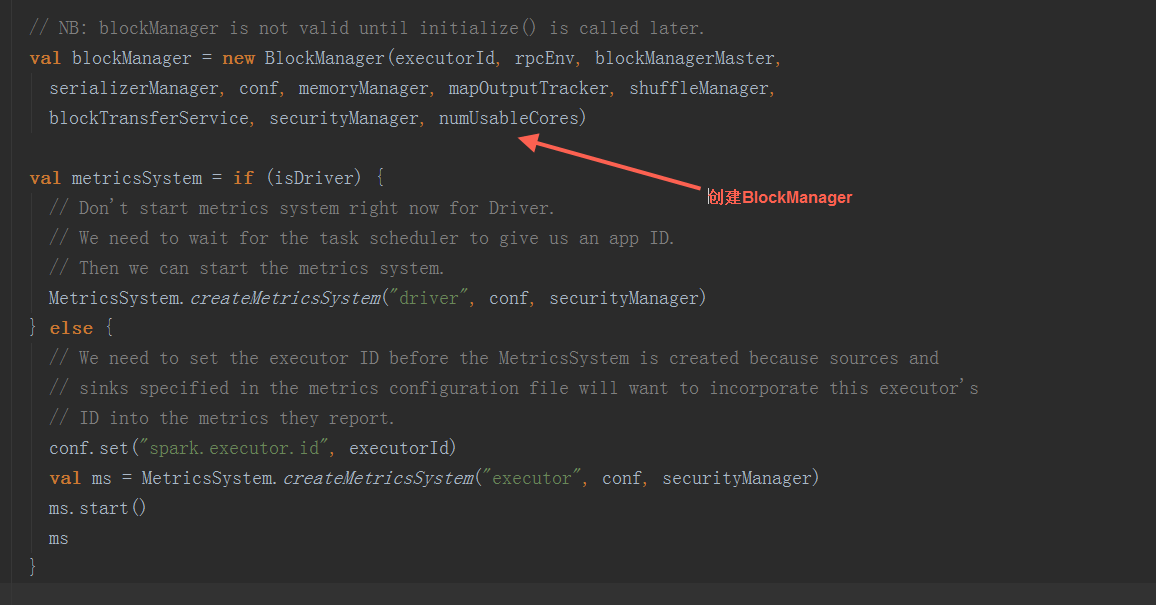
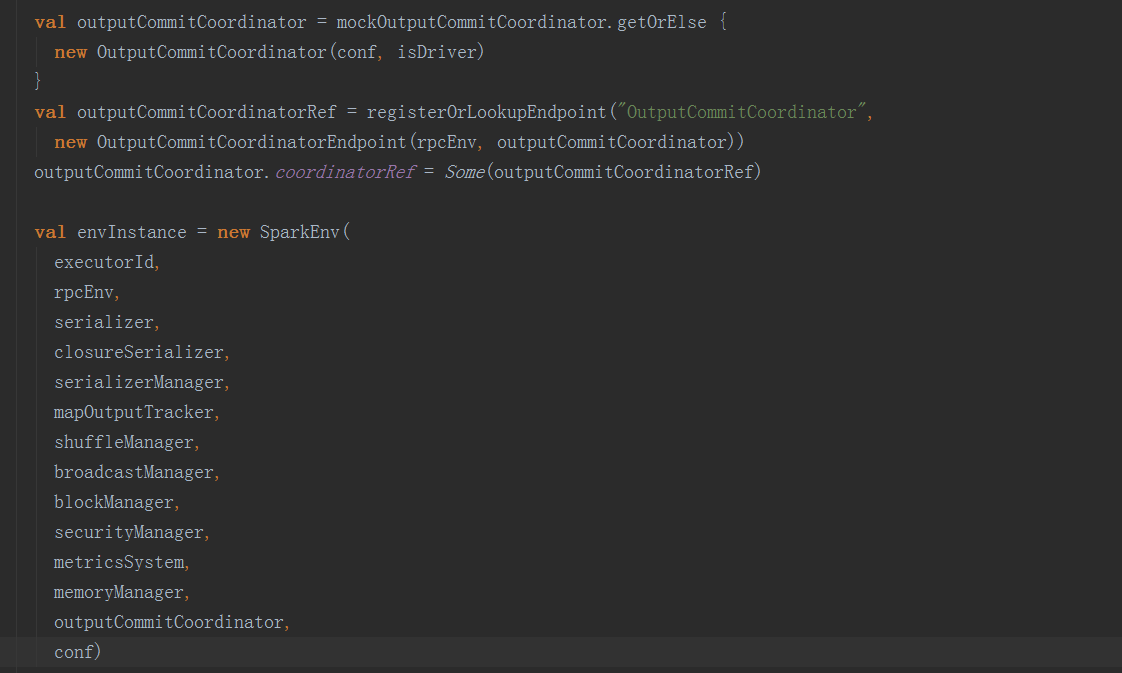
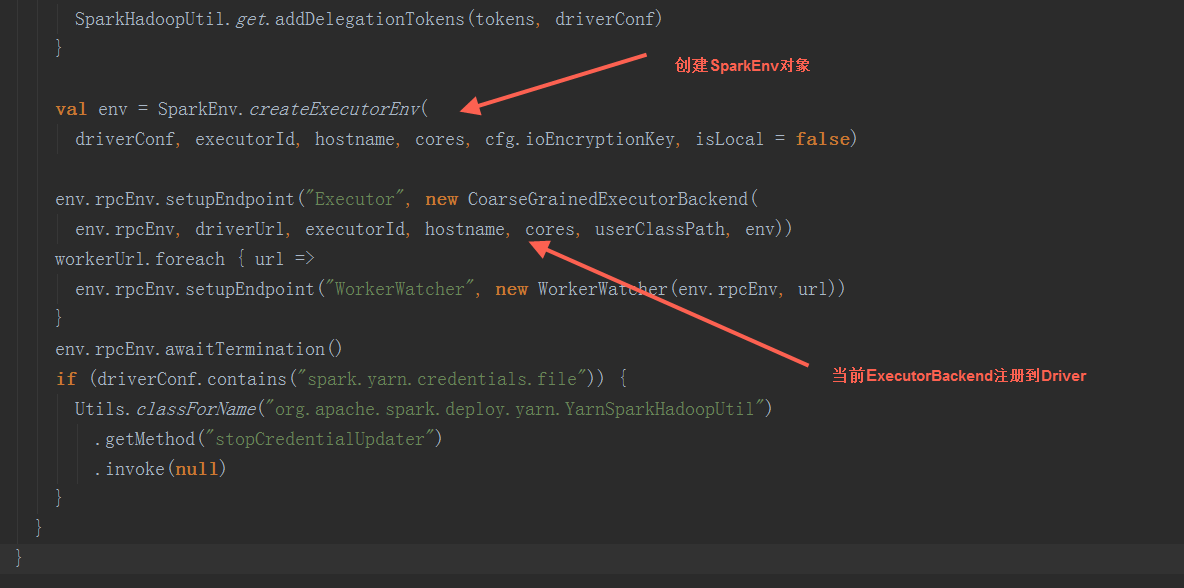 在SparkEnv.create方法中,创建BroadcastManager,MapOutputTracker,ShuffleManager,MemoryManager(分StaticMemoryManager和UnifiedMemoryManager),BlockTransferService,BlockManagerMaster,BlockManager
在SparkEnv.create方法中,创建BroadcastManager,MapOutputTracker,ShuffleManager,MemoryManager(分StaticMemoryManager和UnifiedMemoryManager),BlockTransferService,BlockManagerMaster,BlockManager 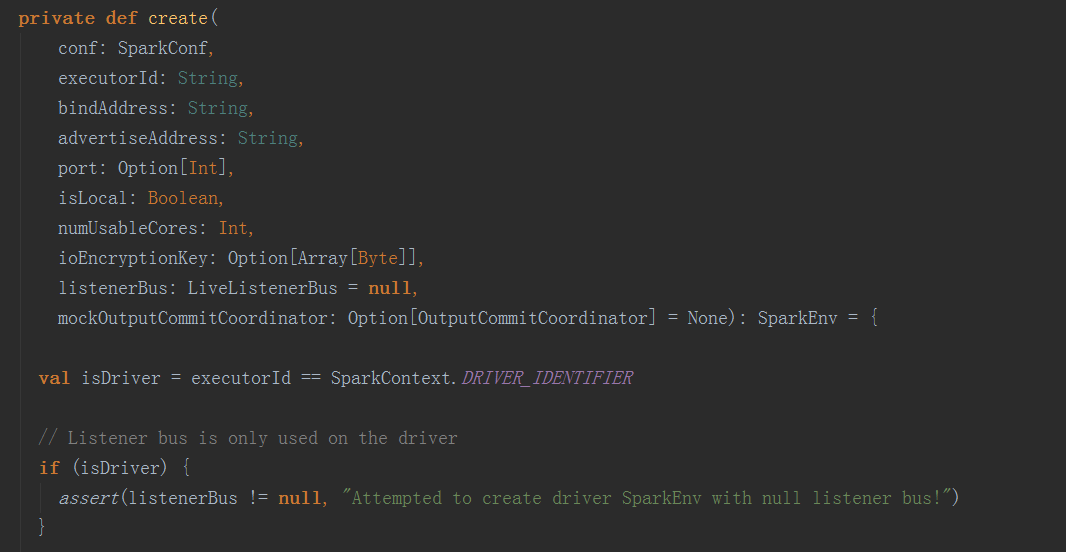


 Driver端CoarseGrainedSchedulerBackend(为何是这个,存疑)接收RegisterExecutor消息
Driver端CoarseGrainedSchedulerBackend(为何是这个,存疑)接收RegisterExecutor消息
二、 Job创建 (一) RDD 1. 性质 1) partitions:分区的集合
1) partitions:分区的集合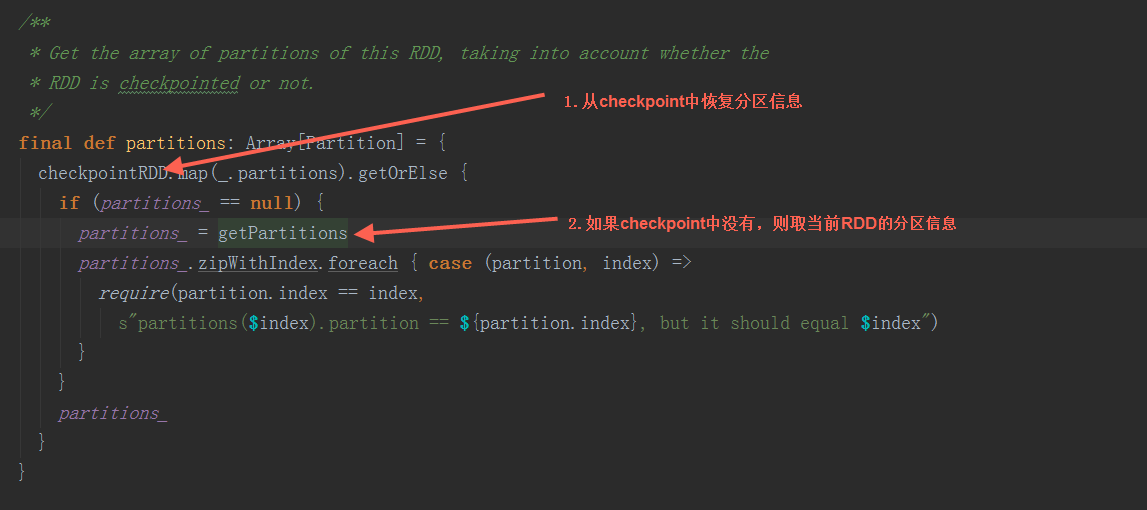 2) preferredLocations:根据本地性快速访问到数据的偏好位置
2) preferredLocations:根据本地性快速访问到数据的偏好位置
3) dependencies:依赖列表 4) getNumPartitions:分区数
4) getNumPartitions:分区数
取当前RDD分区数组的长度  5) iterator:计算迭代器
5) iterator:计算迭代器
a) 根据当前RDD的存储级别,如果没有存储级别,则调用BlockManager. getOrElseUpdate方法,根据driver端RDD的blockId与executor端BlockId的对应关系,取得数据(后续存储部分详细解析)。
b) 从checkpoint恢复。
Refer:
[1] Spark源码分析
http://tech.dianwoda.com/2018/01/10/sparkyuan-ma-fen-xi/
[2] Spark源码分析 之 Driver和Excutor是怎么跑起来的?(2.2.0版本)
https://www.cnblogs.com/xing901022/p/8260362.html
[3] Spark - 源码分析(一)
https://sycki.com/articles/spark/spark-source-code-1
[4] Spark源码分析之分区器的作用
http://support.huawei.com/huaweiconnect/enterprise/zh/thread-411653.html















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









