






如果各位对不熟悉JAVA的 HashMap原理和实现,那么这篇文章可能值得一看。
HashMap 简介: 基于哈希表的 Map 接口的非同步实现。允许使用null值和null键。键不允许重复,值允许重复。存储是无序的,是按照哈希散列排序的。底层数据结构:Hash链表。
图示:
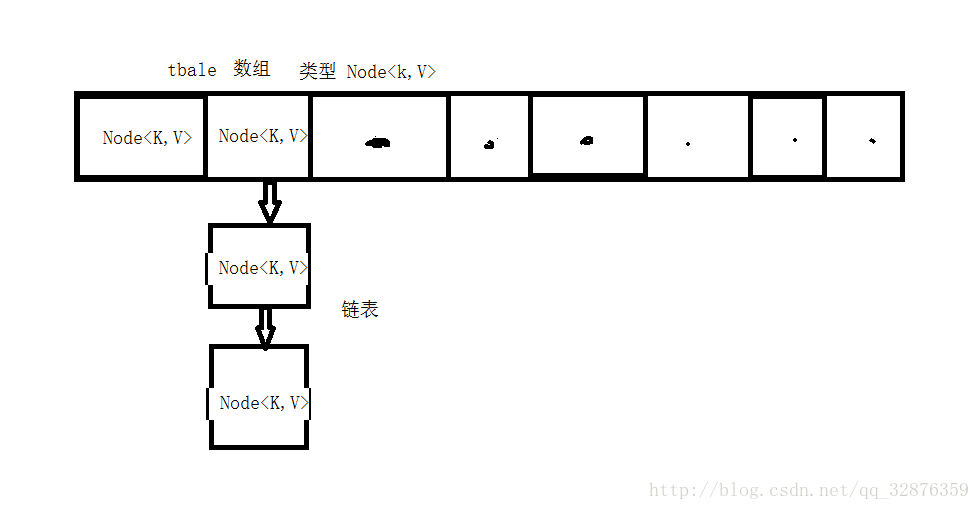
一 :实现原理(结合JDK源码片段):
1.初始化HashMap : 更具给定的参数初始化一个数据类型为Node的table数组。
transientNode[] table;
2.存入键值对:
2.1 判断该table是否为空,若为空则初始化该table。
2.2 判断该key是否为null,若为null ,则将该放置到数组的第一个位置。否则继续。
2.3 先使用hash(k) 计算得到该k对应的hash数值。
//计算key的 hash数值static final inthash(Object key) {
inth;
return(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
2.4 使用该hash 对整个表的长度进行取模运算,以求该k能放在数组中的坐标I 。
tab[i = (n - 1) & hash]
2.5判断table[i]处是否有数据,若不为空,则遍历该位置的链表,比较是否有相同的key,如果有相同的key则用的新的V覆盖旧的V,否则在该链表的顶部插入该节点。
判断是否为同一个key:
if(p.hash== hash && ((k = p.key) == key || (key != null&& key.equals(k))))
3.获取key对应的value。步骤和存入数据差不多。
二.MyHashMap的代码实现(肯定有不足之处):
importjava.io.Serializable;
importjava.util.*;
//zhaoke 2018-1-8public classMyHashMapimplementsCloneable, Serializable {
//设置初始的容量为16static final intDEFAULT_INITIAL_CAPACITY= 1 << 4;
//设置其最大容量为1024static final intMAXIMUM_CAPACITY= 1 << 30;
//设置其容量阈值因子为0.75static final floatDEFAULT_LOAD_FACTOR= 0.75f;
//实际储存的大小transient intsize;
//阈值intthreshold;
//设置每一个节点 实现 Map.Entry是为了实现一个链表static classNodeimplementsMap.Entry{
final inthash;
finalK key;
V value;
MyHashMap.Nodenext;
Node(inthash, K key, V value, MyHashMap.Nodenext) {
this.hash= hash;
this.key= key;
this.value= value;
this.next= next;
}
public finalK getKey() {
returnkey;
}
public finalV getValue() {
returnvalue;
}
public finalString toString() {
returnkey+ "="+ value;
}
public final inthashCode() {
returnObjects.hashCode(key) ^ Objects.hashCode(value); // 调用 Objects的hashCode() 进行异或计算}
public finalV setValue(V newValue) {
V oldValue = value;
value= newValue;
returnoldValue;
}
public final booleanequals(Object o) {
if(o == this)
return true;
if(o instanceofMap.Entry) {
Map.Entry, ?> e = (Map.Entry, ?>) o;
if(Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
//用一个数据类型为Node 的 数组充当 MyHashMapprivateNode[] table;
transient intmodCount;
//计算key的 hash数值static final inthash(Object key) {
inth;
return(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//初始化MyHashmappublicMyHashMap() {
initTable();
}
//将数据插入MyHashMap中publicV put(K key, V value) {
//如果是空的,则进行初始化大小if(table== null) {
initTable();
}
//允许K/V存放null//若key为null则调用putForNullKey方法 放在数组第一位置if(key == null)
returnputNullKey(value);
//计算hashinthash = hash(key);
//搜索指定hash值在对应table中的索引。inti = indexFor(hash, table.length);
//如果i处不为空,则循环遍历下一个元素,产生链表for(Noden = table[i]; n != null; n = n.next) {
Object k;
if(n.hash== hash && ((k = n.key) == key || key.equals(k))) {
V oldValue = n.value;
n.value= value;
returnoldValue;
}
}
//如果i处索引为null或没有相同的,则表明还没有EntrymodCount++;
//插入,将k v插入到i处addNode(hash, key, value, i);
return null;
}
voidaddNode(inthash, K key, V value, intbucketIndex) {
//若大小不够就扩充到原来的2倍if((size>= threshold) && (null!= table[bucketIndex])) {
resize(2 * table.length);
hash = (null!= key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
//创建新NodecreateNode(hash, key, value, bucketIndex);
}
voidcreateNode(inthash, K key, V value, intbucketIndex) {
//获取指定索引处的NodeNoden = table[bucketIndex];
//将新创建的 Node放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entrytable[bucketIndex] = newNode<>(hash, key, value, n);
//增加大小size++;
}
//初始化table数组private voidinitTable() {
table= newNode[DEFAULT_INITIAL_CAPACITY];
//初始化阈值threshold=(int) Math.floor(DEFAULT_INITIAL_CAPACITY*DEFAULT_LOAD_FACTOR);
}
//只放空数值privateV putNullKey(V value) {
Node oldnode = table[0];
Node node = newNode(0, null, value, null);
table[0] = node;
return(oldnode == null) ? null: ((V) oldnode.getValue());
}
//返回对应key的 在数组的位置 取代模 % 取余运算static intindexFor(inth, intlength) {
// length 必须为 2 的N 次returnh & (length - 1);
}
//获取该MyHashMap的sizepublic intsize() {
returnsize;
}
//判断该MyHashMap是否为空public booleanisEmpty() {
returnsize== 0;
}
//重新修改起容量 新的容量voidresize(intnewCapacity) {
//引用扩容前的Node数组Node[] oldTable = table;
intoldCapacity = oldTable.length;
//扩容前的数组大小如果已经达到最大(2^30)了 1Gif(oldCapacity == MAXIMUM_CAPACITY) {
//修改阈值为int的最大值(2^31-1),这样以后就不会扩容了threshold= Integer.MAX_VALUE;
return;
}
//初始化一个新的Node数组Node[] newTable = newNode[newCapacity];
//将数据转移到新的Node数组里transfer(newTable);
//将新table 赋值给原来的tabletable= newTable;
threshold= (int)(newCapacity * DEFAULT_LOAD_FACTOR);//修改阈值}
voidtransfer(Node[] newTable) {
//oldtable 引用原来的tableNode[] oldtable = table;
intnewCapacity = newTable.length;
//遍历原来的tablefor(intj = 0; j < oldtable.length; j++) {
//取得旧oldtable数组的每个元素Noden = oldtable[j];
if(n != null) {
//释放我们可爱的oldtableoldtable[j] = null;
do{
Nodenext = n.next;
//!!重新计算每个元素在数组中的位置inti = indexFor(n.hash, newCapacity);
//此处注意 越最近添加的k 对应的节点 其距离 数组越进 可以理解为链表的头插n.next= newTable[i];
//将元素放在数组上newTable[i] = n;
//访问下一个Node链上的元素n = next;
} while(n != null);
}
}
}
//获取数值publicV get(K key) {
if(key == null)
returngetForNullKey();
Nodenode = getNode(key);
return null== node ? null: node.getValue();
}
publicNode getNode(K key){
//如果是空的 则返回nullif(table== null) {
return null;
}
inthash = hash(key);
//搜索指定hash值在对应table中的索引。inti = indexFor(hash, table.length);
//如果i处不为空,则循环遍历下一个元素for(Noden = table[i]; n != null; n = n.next) {
Object k;
if(n.hash== hash && ((k = n.key) == key || key.equals(k))) {
returnn;
}
}
return null;
}
//获取key为Null的valuepublicV getForNullKey(){
return(table[0]==null)?null:(table[0].value);
}
}
文章代码肯定有不足之处,各位老铁一定要私信我哟。















 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









