







环境信息
完全分布式集群(一)集群基础环境及zookeeper-3.4.10安装部署
创建用户用户组
在集群中各个节点执行以下命令,创建hadoop用户组,hadoop用户,设置hadoop用户的密码
groupadd hadoop
useradd -g hadoop hadoop
passwd hadoop解压授权
通过FTP上传hadoop-2.6.5.tar.gz安装包,解压至/usr/local/目录,并将解压后的目录授权给hadoop用户
gtar -xzf /home/hadoop/hadoop-2.6.5.tar.gz -C /usr/local/
chown -R hadoop:hadoop /usr/local/hadoop-2.6.5配置免密码登录
集群节点间需要相互调用访问,所以需要在各节点上配置hadoop用户免密码登录,注意此处包括节点本身也要设置免密码登录
# 每个节点上执行,切换至hadoop用户,生成各节点秘钥对
su - hadoop
ssh-keygen -t rsa
# 一路回车完成
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
7f:f2:71:39:b8:9d:20:6b:9b:03:7d:f8:ab:a1:6d:b5 hadoop@node222
The key's randomart image is:
+--[ RSA 2048]----+
| |
| |
| |
| |
| S. . |
| ..o o. . |
| .=+=.+ |
| o+OE* o |
| .o*++.o |
+-----------------+通过ssh-copy-id将各节点公钥复制到需要无密码登陆的服务器上,包括节点自己
# 在yes/no处输入yes,其余一路回车
[hadoop@node222 .ssh]$ ssh-copy-id -i id_rsa.pub -p 22 hadoop@node224
The authenticity of host 'node224 (192.168.0.224)' can't be established.
ECDSA key fingerprint is 12:37:f3:be:f5:f5:2b:eb:24:fd:08:b2:e0:d9:4f:03.
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
hadoop@node224's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh -p '22' 'hadoop@node224'"
and check to make sure that only the key(s) you wanted were added.
# 同时拷贝至node225,node222(自己本节点)
[hadoop@node222 .ssh]$ ssh-copy-id -i id_rsa.pub -p 22 hadoop@node225
[hadoop@node222 .ssh]$ ssh-copy-id -i id_rsa.pub -p 22 hadoop@node222
# node224
[hadoop@node224 .ssh]$ ssh-copy-id -i id_rsa.pub -p 22 hadoop@node225
[hadoop@node224 .ssh]$ ssh-copy-id -i id_rsa.pub -p 22 hadoop@node222
[hadoop@node224 .ssh]$ ssh-copy-id -i id_rsa.pub -p 22 hadoop@node224
# node225
[hadoop@node225 .ssh]$ ssh-copy-id -i id_rsa.pub -p 22 hadoop@node225
[hadoop@node225 .ssh]$ ssh-copy-id -i id_rsa.pub -p 22 hadoop@node222
[hadoop@node225 .ssh]$ ssh-copy-id -i id_rsa.pub -p 22 hadoop@node224完成以上配置后,分别测试各节点间相互SSH免密码登录情况,正常无需密码登录即完成配置
[hadoop@node222 .ssh]$ ssh node224
Last login: Fri Sep 28 15:25:27 2018
[hadoop@node224 ~]$ exit
logout
Connection to node224 closed.
[hadoop@node222 .ssh]$ ssh node225
Last login: Fri Sep 28 15:25:50 2018
[hadoop@node225 ~]$ exit
logout创建相关目录
创建集群所需要的配置目录,在node222节点上创建,配置完成后将相关目录拷贝至其他节点。
mkdir -p /home/hadoop/log/hadoop
mkdir -p /home/hadoop/log/yarn
mkdir -p /usr/local/hadoop-2.6.5/dfs
mkdir -p /usr/local/hadoop-2.6.5/dfs/name
mkdir -p /usr/local/hadoop-2.6.5/dfs/data
mkdir -p /usr/local/hadoop-2.6.5/tmp
mkdir -p /usr/local/hadoop-2.6.5/journal
mkdir -p /usr/local/hadoop-2.6.5/yarn/local分离配置文件与安装目录,方便hadoop升级,将hadoop的配置文件放置在/home/hadoop/config目录下即hadoop用户的“家目录”下,node222节点上hadoop用户操作
cp -r /usr/local/hadoop-2.6.5/etc/hadoop/ /home/hadoop/config/修改配置文件
配置hadoop-env.sh,修改对应环境变量配置项,node222节点上hadoop用户操作
vi /home/hadoop/config/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_66/
export HADOOP_CONF_DIR=/home/hadoop/config/
export HADOOP_LOG_DIR=/home/hadoop/log/hadoop配置yarn-env.sh,修改对应环境变量配置项,node222节点上hadoop用户操作
YARN_LOG_DIR="/home/hadoop/log/yarn"
export JAVA_HOME=/usr/local/jdk1.8.0_66/配置core-site.xml,在configuration节点中增加如下配置项,node222节点上hadoop用户操作
vi /home/hadoop/config/core-site.xml
<configuration>
<!-- 定义hdfs集群的名称 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.6.5/tmp</value>
</property>
<!-- 指定zookeeper集群个节点地址端口 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>node222:2181,node224:2181,node225:2181</value>
</property>
</configuration>
配置hdfs-site.xml,在configuration节点中增加如下配置项,node222节点上hadoop用户操作
vi /home/hadoop/config/hdfs-site.xml
<configuration>
<!--指定namenode名称空间的存储地址-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop-2.6.5/dfs/name</value>
</property>
<!--指定datanode数据存储地址-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop-2.6.5/dfs/data</value>
</property>
<!--指定数据冗余份数-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1 下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>node222:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>node222:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>node224:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>node224:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node222:8485;node224:8485;node225:8485/ns1</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop-2.6.5/journal</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.ha.automatic-failover.enabled.ns1</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免密码登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>配置mapred-site.xml,默认没有mapred-site.xml,需要通过mapred-site.xml.template模板拷贝生成,在configuration节点中增加如下配置项,node222节点上hadoop用户操作
cp /home/hadoop/config/mapred-site.xml.template /home/hadoop/config/mapred-site.xml
vi /home/hadoop/config/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置 MapReduce JobHistory Server 地址 ,默认端口10020 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
<description>MapReduce JobHistory Server IPC host:port</description>
</property>
<!-- 配置 MapReduce JobHistory Server web ui 地址, 默认端口19888 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
<description>MapReduce JobHistory Server Web UI host:port</description>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>64</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/user/history/done_intermediate</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/user/history</value>
</property>
</configuration>配置yarn-site.xml,在configuration节点中增加如下配置项,node222节点上hadoop用户操作
vi /home/hadoop/config/yarn-site.xml
<configuration>
<!--rm失联后重新链接的时间-->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<!--开启resourcemanagerHA,默认为false-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--配置resourcemanager-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node222:2181,node224:2181,node225:2181</value>
</property>
<!--开启故障自动切换-->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node222</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node224</value>
</property>
<!--***********不同节点需要修改****************-->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
<description>If we want to launch more than one RM in single node,we need this configuration</description>
</property>
<!--开启自动恢复功能-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--配置与zookeeper的连接地址-->
<property>
<name>yarn.resourcemanager.zk-state-store.address</name>
<value>node222:2181,node224:2181,node225:2181</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node222:2181,node224:2181,node225:2181</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>ns1-yarn</value>
</property>
<!--schelduler失联等待连接时间-->
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<!--配置rm1-->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>node222:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>node222:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node222:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>node222:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>node222:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>node222:23142</value>
</property>
<!--配置rm2-->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>node224:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>node224:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node224:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>node224:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>node224:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>node224:23142</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/usr/local/hadoop-2.6.5/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/home/hadoop/log/yarn</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<!--故障处理类-->
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.zk-base-path</name>
<value>/yarn-leader-election</value>
<description>Optionalsetting.Thedefaultvalueis/yarn-leader-election</description>
</property>
</configuration>将要配置为DataNode的节点hostname添加至slaves 文件,node222节点上hadoop用户操作
vi /home/hadoop/config/slaves
# 添加如下内容
node222
node224
node225用root用户将hadoop拷贝至其他集群节点,因为默认的安装目录/usr/local目录hadoop用户没有权限操作。同时在其他接收节点将相关目录的权限授予hadoop用户
# node222 root用户操作
scp -r /usr/local/hadoop-2.6.5 node224:/usr/local/
scp -r /home/hadoop/config/ /home/hadoop/log/ node224:/home/hadoop/
scp -r /usr/local/hadoop-2.6.5 node225:/usr/local/
scp -r /home/hadoop/config/ /home/hadoop/log/ node225:/home/hadoop/
# node224 root用户操作
chown -R hadoop:hadoop /home/hadoop
chown -R hadoop:hadoop /usr/local/hadoop-2.6.5
# node225 root用户操作
chown -R hadoop:hadoop /home/hadoop
chown -R hadoop:hadoop /usr/local/hadoop-2.6.5修改备Namenode节点上的yarn-site.xml配置文件中的yarn.resourcemanager.ha.id,其中node222为rm1,node224为rm2。node224节点上hadoop用户操作。
<!--***********不同节点需要修改****************-->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
<description>If we want to launch more than one RM in single node,we need this configuration</description>
</property>将hadoop相关环境变量注入/etc/profile中,每个节点都要操作
export HADOOP_HOME=/usr/local/hadoop-2.6.5/
export HADOOP_CONF_DIR=/home/hadoop/config/
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib:$PATH启动hadoop集群
启动zookeeper集群并确保zk集群状态正常,具体操作见
完全分布式集群(一)集群基础环境及zookeeper-3.4.10安装部署
格式化ZooKeeper集群,在ZooKeeper集群上建立HA的相应节点。
[hadoop@node222 ~]$ /usr/local/hadoop-2.6.5/bin/hdfs zkfc -formatZK
18/09/29 09:16:54 INFO tools.DFSZKFailoverController: Failover controller configured for NameNode NameNode at node222/192.168.0.222:9000
18/09/29 09:16:54 INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT
18/09/29 09:16:54 INFO zookeeper.ZooKeeper: Client environment:host.name=node222
18/09/29 09:16:54 INFO zookeeper.ZooKeeper: Client environment:java.version=1.8.0_66
18/09/29 09:16:54 INFO zookeeper.ZooKeeper: Client environment:java.vendor=Oracle Corporation
18/09/29 09:16:54 INFO zookeeper.ZooKeeper: Client environment:java.home=/usr/local/jdk1.8.0_66/jre
18/09/29 09:16:54 INFO zookeeper.ZooKeeper: Client
......
18/09/29 09:16:55 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/ns1 in ZK.
18/09/29 09:16:55 INFO zookeeper.ZooKeeper: Session: 0x1661fcbe83d0000 closed
18/09/29 09:16:55 WARN ha.ActiveStandbyElector: Ignoring stale result from old client with sessionId 0x1661fcbe83d0000
18/09/29 09:16:55 INFO zookeeper.ClientCnxn: EventThread shut down通过zk客户端工具检查格式化结果
[hadoop@node222 ~]$ zkCli.sh -server node222:2181
Connecting to node222:2181
2018-09-29 09:20:09,065 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.10-39d3a4f269333c922ed3db283be479f9deacaa0f, built on 03/23/2017 10:13 GMT
......
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: node222:2181(CONNECTED) 0] ls /
[zookeeper, hadoop-ha]
[zk: node222:2181(CONNECTED) 1] ls /hadoop-ha
[ns1]启动日志程序
依次启动各节点上的日志程序journalnode,启动后通过jps能查询到JournalNode进程及说明启动正常。
[hadoop@node222 ~]$ /usr/local/hadoop-2.6.5/sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/hadoop/log/hadoop//hadoop-hadoop-journalnode-node222.out
[hadoop@node224 ~]$ /usr/local/hadoop-2.6.5/sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/hadoop/log/hadoop//hadoop-hadoop-journalnode-node224.out
[hadoop@node225 ~]$ /usr/local/hadoop-2.6.5/sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/hadoop/log/hadoop//hadoop-hadoop-journalnode-node225.out格式化namenode
在主节node222点上执行
[hadoop@node222 ~]$ /usr/local/hadoop-2.6.5/bin/hdfs namenode -format
18/09/29 09:27:15 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = node222/192.168.0.222
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.6.5
STARTUP_MSG: classpath =
......
18/09/29 09:27:20 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
18/09/29 09:27:20 INFO util.ExitUtil: Exiting with status 0
18/09/29 09:27:20 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node222/192.168.0.222
************************************************************/启动主节点
[hadoop@node222 ~]$ /usr/local/hadoop-2.6.5/sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /home/hadoop/log/hadoop//hadoop-hadoop-namenode-node222.out
[hadoop@node222 ~]$ jps
4724 NameNode
3879 QuorumPeerMain
4796 Jps
4605 JournalNode从namenode节点上同步数据
从节点上执行,在从节点上同步主节点数据,同步完成后会关闭从节点的namenode进程
[hadoop@node224 ~]$ /usr/local/hadoop-2.6.5/bin/hdfs namenode -bootstrapStandby
18/09/29 09:29:15 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = node224/192.168.0.224
STARTUP_MSG: args = [-bootstrapStandby]
STARTUP_MSG: version = 2.6.5
STARTUP_MSG: classpath =
......
18/09/29 09:29:15 INFO namenode.NameNode: createNameNode [-bootstrapStandby]
=====================================================
About to bootstrap Standby ID nn2 from:
Nameservice ID: ns1
Other Namenode ID: nn1
Other NN's HTTP address: http://node222:50070
Other NN's IPC address: node222/192.168.0.222:9000
Namespace ID: 172841409
Block pool ID: BP-1584106043-192.168.0.222-1538184439585
Cluster ID: CID-5cd9a86e-92ab-4fb4-b5c6-212638251d2c
Layout version: -60
isUpgradeFinalized: true
=====================================================
18/09/29 09:29:17 INFO common.Storage: Storage directory /usr/local/hadoop-2.6.5/dfs/name has been successfully formatted.
18/09/29 09:29:18 INFO namenode.TransferFsImage: Opening connection to http://node222:50070/imagetransfer?getimage=1&txid=0&storageInfo=-60:172841409:0:CID-5cd9a86e-92ab-4fb4-b5c6-212638251d2c
18/09/29 09:29:18 INFO namenode.TransferFsImage: Image Transfer timeout configured to 60000 milliseconds
18/09/29 09:29:18 INFO namenode.TransferFsImage: Transfer took 0.01s at 0.00 KB/s
18/09/29 09:29:18 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 322 bytes.
18/09/29 09:29:18 INFO util.ExitUtil: Exiting with status 0
18/09/29 09:29:18 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node224/192.168.0.224
************************************************************/启动从namenode节点
[hadoop@node224 ~]$ /usr/local/hadoop-2.6.5/sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /home/hadoop/log/hadoop//hadoop-hadoop-namenode-node224.out
[hadoop@node224 ~]$ jps
5008 NameNode
4888 JournalNode
5085 Jps启动所有DataNode节点
[hadoop@node222 ~]$ /usr/local/hadoop-2.6.5/sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /home/hadoop/log/hadoop//hadoop-hadoop-datanode-node222.out
[hadoop@node222 ~]$ jps
4724 NameNode
3879 QuorumPeerMain
4935 Jps
4605 JournalNode
4862 DataNode
[hadoop@node224 ~]$ /usr/local/hadoop-2.6.5/sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /home/hadoop/log/hadoop//hadoop-hadoop-datanode-node224.out
[hadoop@node224 ~]$ jps
5008 NameNode
5473 QuorumPeerMain
4888 JournalNode
5530 Jps
5133 DataNode
[hadoop@node225 ~]$ /usr/local/hadoop-2.6.5/sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /home/hadoop/log/hadoop//hadoop-hadoop-datanode-node225.out
[hadoop@node225 ~]$ jps
5075 JournalNode
5446 QuorumPeerMain
5244 DataNode
5503 Jps启动namenode节点的ZooKeeperFailoverController
否则通过hadfs的9000端口查看,两个namenode均处于standby状态
[hadoop@node222 ~]$ /usr/local/hadoop-2.6.5/sbin/hadoop-daemon.sh start zkfc
starting zkfc, logging to /home/hadoop/log/hadoop//hadoop-hadoop-zkfc-node222.out
[hadoop@node222 ~]$ jps
4724 NameNode
3879 QuorumPeerMain
5002 DFSZKFailoverController
5066 Jps
4605 JournalNode
4862 DataNode
[hadoop@node222 ~]$
[hadoop@node224 ~]$ /usr/local/hadoop-2.6.5/sbin/hadoop-daemon.sh start zkfc
starting zkfc, logging to /home/hadoop/log/hadoop//hadoop-hadoop-zkfc-node224.out
[hadoop@node224 ~]$ jps
5008 NameNode
5473 QuorumPeerMain
5573 DFSZKFailoverController
5621 Jps
4888 JournalNode
5133 DataNode启动yarn
[hadoop@node222 ~]$ /usr/local/hadoop-2.6.5/sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /home/hadoop/log/yarn/yarn-hadoop-resourcemanager-node222.out
[hadoop@node222 ~]$ /usr/local/hadoop-2.6.5/bin/yarn rmadmin -getServiceState rm1
active
[hadoop@node224 ~]$ /usr/local/hadoop-2.6.5/sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /home/hadoop/log/yarn/yarn-hadoop-resourcemanager-node224.out
[hadoop@node224 ~]$ /usr/local/hadoop-2.6.5/bin/yarn rmadmin -getServiceState rm2
standby测试hdfs的故障转移
执行主从切换命令后通过web客户端查看各节点的状态,执行切换后可通过web界面确认两个namenode节点状态的切换
[hadoop@node222 ~]$ /usr/local/hadoop-2.6.5/bin/hdfs haadmin -failover nn1 nn2
Failover to NameNode at node224/192.168.0.224:9000 successful
[hadoop@node222 ~]$ /usr/local/hadoop-2.6.5/bin/hdfs haadmin -failover nn2 nn1
Failover to NameNode at node222/192.168.0.222:9000 successfulweb界面访问
hdfs web访问 NameNode:50070
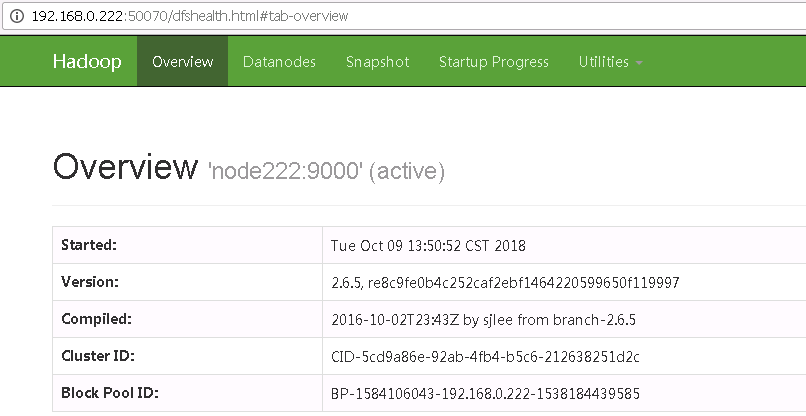
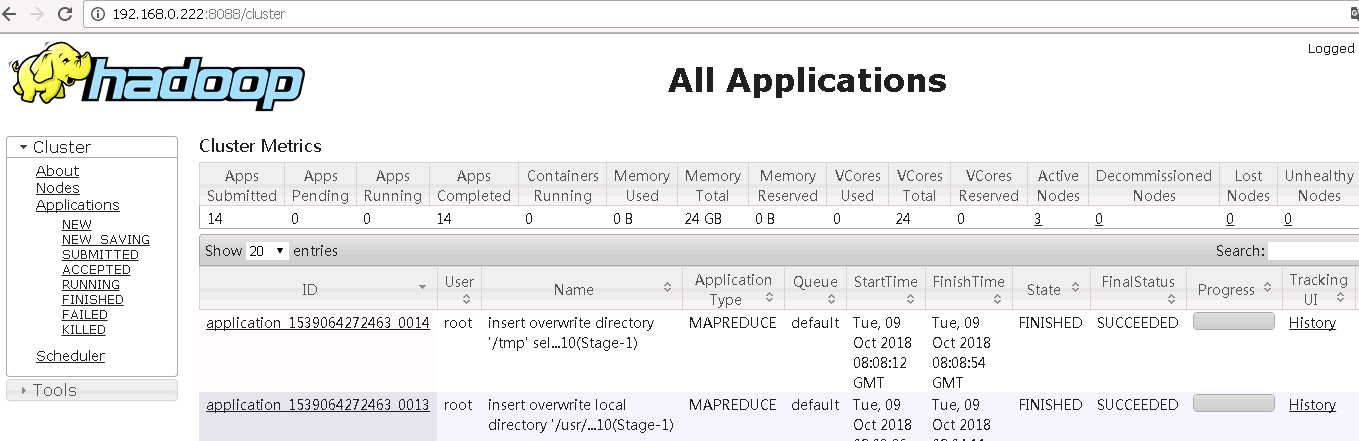
yarn web访问web界面 NameNode:8088
start-all.sh启动hadoop集群
通过start-all.sh 启动缺少备主节点上的resourcemanager,需要手动启动
# 主节点上启动
[hadoop@node222 ~]$ /usr/local/hadoop-2.6.5/sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [node222 node224]
node222: starting namenode, logging to /home/hadoop/log/hadoop/hadoop-hadoop-namenode-node222.out
node224: starting namenode, logging to /home/hadoop/log/hadoop/hadoop-hadoop-namenode-node224.out
node224: starting datanode, logging to /home/hadoop/log/hadoop/hadoop-hadoop-datanode-node224.out
node222: starting datanode, logging to /home/hadoop/log/hadoop/hadoop-hadoop-datanode-node222.out
node225: starting datanode, logging to /home/hadoop/log/hadoop/hadoop-hadoop-datanode-node225.out
Starting journal nodes [node222 node224 node225]
node225: starting journalnode, logging to /home/hadoop/log/hadoop/hadoop-hadoop-journalnode-node225.out
node222: starting journalnode, logging to /home/hadoop/log/hadoop/hadoop-hadoop-journalnode-node222.out
node224: starting journalnode, logging to /home/hadoop/log/hadoop/hadoop-hadoop-journalnode-node224.out
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/log/yarn/yarn-hadoop-resourcemanager-node222.out
node225: starting nodemanager, logging to /home/hadoop/log/yarn/yarn-hadoop-nodemanager-node225.out
node222: starting nodemanager, logging to /home/hadoop/log/yarn/yarn-hadoop-nodemanager-node222.out
node224: starting nodemanager, logging to /home/hadoop/log/yarn/yarn-hadoop-nodemanager-node224.out
# 启动备namenode节点上的resourcemanager
[hadoop@node224 .ssh]$ /usr/local/hadoop-2.6.5/sbin/yarn-daemon.sh start resourcemanager
# 启动主备namenode节点的zkfc
[hadoop@node222 ~]$ /usr/local/hadoop-2.6.5/sbin/hadoop-daemon.sh start zkfc
[hadoop@node224 ~]$ /usr/local/hadoop-2.6.5/sbin/hadoop-daemon.sh start zkfcstop-all.sh关闭集群
# 主节点上关闭
[hadoop@node222 ~]$ /usr/local/hadoop-2.6.5/sbin/stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [node222 node224]
node224: stopping namenode
node222: stopping namenode
node225: stopping datanode
node222: stopping datanode
node224: stopping datanode
Stopping journal nodes [node222 node224 node225]
node222: stopping journalnode
node224: stopping journalnode
node225: stopping journalnode
stopping yarn daemons
stopping resourcemanager
node222: stopping nodemanager
node225: stopping nodemanager
node224: stopping nodemanager
no proxyserver to stop
# 备namenode节点关闭resourcemanager
[hadoop@node224 ~]$ /usr/local/hadoop-2.6.5/sbin/yarn-daemon.sh stop resourcemanager
# 关闭namenode节点上的zkfc
[hadoop@node222 ~]$ /usr/local/hadoop-2.6.5/sbin/hadoop-daemon.sh stop zkfc
[hadoop@node224 ~]$ /usr/local/hadoop-2.6.5/sbin/hadoop-daemon.sh stop zkfc执行hdfs shell命令测试集群是否正常
hdfs dfs -ls /
hdfs dfs -mkdir /buaa
hdfs dfs -put /home/hadoop/a.txt /buaa
......















 3021
3021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









