







下载Hadoop安装包
下载地址:http://archive.apache.org/dist/hadoop/core/
hadoop-2.6.5.tar.gz
JDK安装
Hadoop2.7以及之后的版本需要装JAVA7+,Hadoop2.6以及之前的版本需要JAVA6,安装配置参考https://blog.csdn.net/xixiangdeshaonian/article/details/87357813
配置网络和主机名
三节点集群,1个Master,2个Slave
vi /etc/hosts
#新增以下内容
192.168.1.111 Master
192.168.1.112 Slave1
192.168.1.113 Slave2
如果主机名修改未生效
vi /etc/sysconfig/network
#新增以下内容
NETWORKING=yes
NETWORKING_IPV6=yes
HOSTNAME=Master
#保存,退出,重启
service network restart
关闭防火墙与SELINUX
“注意:Master、Slave1、Slave2均要操作”
查看防火墙状态
systemctl status firewalld

关闭防火墙
systemctl disable firewalld
systemctl stop firewalld
查看SELinux状态
sestatus
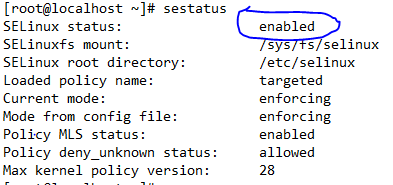
关闭SELinux
vi /etc/selinux/config
#将SELINUX的值设置为disabled

SELINUX修改需要重启linux生效
配置SSH
“注意:Master、Slave1、Slave2均要操作”
ssh-keygen -t rsa
一路回车,此时会生成一个.ssh的隐藏文件夹,里面存放的是公钥密钥文件

在Master上执行以下操作
cat ~/.ssh/id_rsa.pub >authorized_keys
将Slave1和Slave2的id_rsa.pub内容追加到Master的authorized_keys文件中,在Master上执行以下操作
chmod 600 authorized_keys
scp ~/.ssh/authorized_keys root@Slave1:~/.ssh/
scp ~/.ssh/authorized_keys root@Slave2:~/.ssh/
三节点之间可以通过ssh免密登录
配置Hadoop
“注意:只在Master上操作”
tar -zvxf hadoop-2.6.5.tar.gz
配置Hadoop环境变量
vi /etc/profile
####
JAVA_HOME=/usr/local/jdk1.8.0_191/
JRE_HOME=$JAVA_HOME/jre
HADOOP_HOME=/opt/hadoop-2.6.5
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME JRE_HOME HADOOP_HOME CLASS_PATH PATH
配置文件目录
$HADOOP_HOME /etc/hadoop

export JAVA_HOME=/usr/local/jdk1.8.0_191
配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.111:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
</configuration>
fs.defaultFS就是描述HDFS文件系统的URI,其主机是namenode的主机或IP地址,端口是namenode监听RPC的端口。如果没有指定,那么默认端口是8020
io.file.buffer.size,io读写文件时的块大小,一般为131072K(128M)
hadoop再次启动时会自动寻找/tmp/hadoop-grid/dfs/name文件
由于重新启动Linux服务时,会自动清空/tmp目录,因此hadoop找不到文件就会出错,所以一定要先指明hadoop.tmp.dir目录
配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.1.111:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>fslse</value>
</property>
</configuration>
先拷贝一份mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.111:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.1.111:19888</value>
</property>
</configuration>
配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.1.111:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.1.111:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.1.:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.1.:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.1.:8088</value>
</property>
</configuration>
配置slaves文件
[root@Master hadoop]# cat slaves
Slave1
Slave2
分发配置好的Hadoop给其它节点
“注意:只在Master上操作”
scp -r /opt/hadoop-2.6.5 root@Slave1:/opt
scp -r /opt/hadoop-2.6.5 root@Slave2:/opt
格式化namenode
“注意:只在Master上操作”
hdfs namenode -format
启动Hadoop集群
“注意:只在Master上操作”
cd $HADOOP_HOME/sbin
start-all.sh
查看是否启动成功
Master
[root@Master hadoop]# jps
17431 SecondaryNameNode
17595 ResourceManager
30013 Jps
17246 NameNode
Slave1
[root@Slave1 ~]# jps
13730 Jps
9418 DataNode
9517 NodeManager
Slave2
[root@Slave2 ~]# jps
8166 DataNode
8265 NodeManager
12681 Jps














 144
144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









