







一、HDFS体系结构
1.hdfs体系结构
大文件会被分割成多个block进行存储,block大小默认为64MB。每一个block会在多个datanode上存储多份副本,默认是3份。
HDFS是按照Master和Slave的结构进行设计的。分为NameNode、SecondaryNameNode、DataNode这几个角色。
namenode:
namenode是Master节点,负责管理文件目录、文件和block的对应关系以及block和datanode的对应关系还有datanode的副本信息,协调客户端对文件的访问,记录命名空间内的改动或本身属性的改变;使用事务日志记录HDFS元数据的变化,使用映像文件存储文件系统的命名空间,包括文件映射文件属性。
SecondaryNameNode:
是NameNode的冷备份,负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量。
DataNode:
datanode是Slave节点负责存储client发来的数据块block,当然大部分容错机制都是在datanode上实现的,一次写入多次读取不修改。

2.hdfs读写流程
1.从hdfs读取数据
读取流程:
客户端要访问HDFS中的一个文件,首先从namenode获取组成这个文件的数据块位置列表,根据列表知道数据块的datanode,访问datanode获取数据。(namenode不参与实际数据传输)
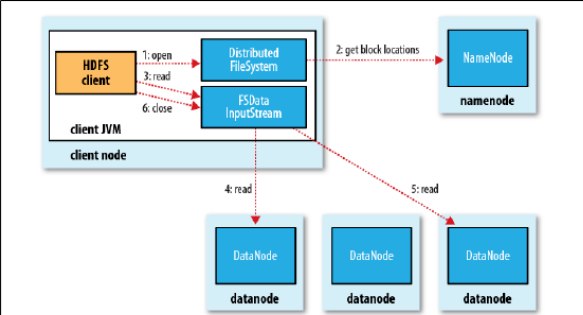
1)客户端通过调用FileSystem对象的open()来读取希望打开的文件。对于HDFS来说,这个对象是分布式文件系统的一个实例。
2)DistributedFileSystem通过RPC来调用namenode,以确定文件的开头部分的块位置。对于每一块,namenode返回具有该块副本的datanode地址。此外,这些datanode根据他们与client的距离来排序(根据网络集群的拓扑)。如果该client本身就是一个datanode,便从本地datanode中读取。DistributedFileSystem返回一个FSDataInputStream对象给client读取数据,FSDataInputStream转而包装了一个DFSInputStream对象。
3)接着client对这个输入流调用read()。存储着文件开头部分的块的数据节点的地址DFSInputStream随即与这些块最近的datanode相连接。
4)通过在数据流中反复调用read(),数据会从datanode返回client。
5)到达块的末端时,DFSInputStream会关闭与datanode间的联系,然后为下一个块找到最佳的datanode。client端只需要读取一个连续的流,这些对于client来说都是透明的。
6)在读取的时候,如果client与datanode通信时遇到一个错误,那么它就会去尝试对这个块来说下一个最近的块。它也会记住那个故障节点的datanode,以保证不会再对之后的块进行徒劳无益的尝试。client也会确认datanode发来的数据的校验和。如果发现一个损坏的块,它就会在client试图从别的datanode中读取一个块的副本之前报告给namenode。
7)这个设计的一个重点是,client直接联系datanode去检索数据,并被namenode指引到块中最好的datanode。因为数据流在此集群中是在所有datanode分散进行的。
所以这种设计能使HDFS可扩展到最大的并发client数量。同时,namenode只不过提供块的位置请求(存储在内存中,十分高效),不是提供数据。否则如果客户端数量增长,namenode就会快速成为一个“瓶颈”。
2.向hdfs写数据
客户端请求namenode创建新文件,客户端将数据写入DFSOutputStream,建立pipeline依次将目标数据块写入各个datanode,建立多个副本。

1)客户端通过在DistributedFileSystem中调用create()来创建文件。
2)DistributedFileSystem 使用RPC去调用namenode,在文件系统的命名空间创一个新的文件,没有块与之相联系。namenode执行各种不同的检查(这个文件存不存在,有没有权限去写,能不能存的下这个文件)以确保这个文件不会已经存在,并且在client有可以创建文件的适当的许可。如果检查通过,namenode就会生成一个新的文件记录;否则,文件创建失败并向client抛出一个IOException异常。分布式文件系统返回一个文件系统数据输出流,让client开始写入数据。就像读取事件一样,文件系统数据输出流控制一个DFSOutputStream,负责处理datanode和namenode之间的通信。
3)在client写入数据时,DFSOutputStream将它分成一个个的包,写入内部的队列,成为数据队列。数据队列随数据流流动,数据流的责任是根据适合的datanode的列表要求这些节点为副本分配新的块。这个数据节点的列表形成一个管线——假设副本数是3,所以有3个节点在管线中。
4)数据流将包分流给管线中第一个的datanode,这个节点会存储包并且发送给管线中的第二个datanode。同样地,第二个datanode存储包并且传给管线中的第三个数据节点。
5)DFSOutputStream也有一个内部的包队列来等待datanode收到确认,成为确认队列。一个包只有在被管线中所有的节点确认后才会被移除出确认队列。如果在有数据写入期间,datanode发生故障,首先管线被关闭,确认队列中的任何包都会被添加回数据队列的前面,以确保故障节点下游的datanode不会漏掉任意一个包。为存储在另一正常datanode的当前数据块制定一个新的标识,并将该标识传给namenode,以便故障节点datanode在恢复后可以删除存储的部分数据块。从管线中删除故障数据节点并且把余下的数据块写入管线中的两个正常的datanode。namenode注意到块复本量不足时,会在另一个节点上创建一个新的复本。后续的数据块继续正常接收处理。只要dfs.replication.min的副本(默认是1)被写入,写操作就是成功的,并且这个块会在集群中被异步复制,直到其满足目标副本数(dfs.replication 默认值为3)。
6)client完成数据的写入后,就会在流中调用close()。
7)在向namenode节点发送完消息之前,此方法会将余下的所有包放入datanode管线并等待确认。namenode节点已经知道文件由哪些块组成(通过Data streamer 询问块分配),所以它只需在返回成功前等待块进行最小量的复制。
8)复本的布局:Hadoop的默认布局策略是在运行客户端的节点上放第1个复本(如果客户端运行在集群之外,就随机选择一个节点,不过系统会避免挑选那些存储太满或太忙的节点。)第2个复本放在与第1个复本不同且随机另外选择的机架的节点上(离架)。第3个复本与第2个复本放在相同的机架,且随机选择另一个节点。其他复本放在集群中随机的节点上,不过系统会尽量避免相同的机架放太多复本。
3.通过实例说明HDFS读写过程
1.写入操作
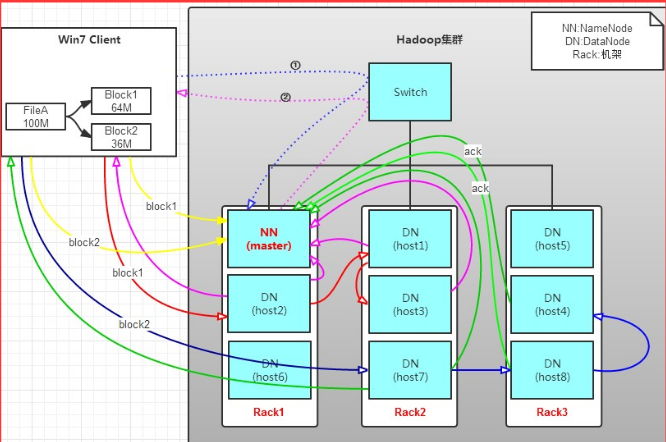
前提:
有一个文件FileA,100M大小。Client将FileA写入到HDFS上。
HDFS按默认配置
HDFS分布在三个机架上Rack1,Rack2,Rack3。
步骤:
1) Client将FileA按64M分块。分成两块,block1和Block2;
2) Client向nameNode发送写数据请求,如图蓝色虚线①------>。
3) NameNode节点,记录block信息。并返回可用的DataNode,如粉色虚线②--------->
Block1: host2,host1,host3
Block2: host7,host8,host4
原理:
NameNode具有RackAware机架感知功能,这个可以配置。
若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
4)client向DataNode发送block1;发送过程是以流式写入。
第一步:将64M的block1按64k的package划分;
第二步:然后将第一个package发送给host2;
第三步:host2接收完后,将第一个package发送给host1,同时client想host2发送第二个package;
第四步:host1接收完第一个package后,发送给host3,同时接收host2发来的第二个package。
第五步:以此类推,如图红线实线所示,直到将block1发送完毕。
第六步:host2,host1,host3向NameNode,host2向Client发送通知,说“消息发送完了”。如图粉红颜色实线所示。
第七步:client收到最后一个host2发来的消息后,向namenode发送消息,说我写完了。这样就真完成了。如图黄色粗实线
第八步:发送完block1后,再向host7,host8,host4发送block2,如图蓝色实线所示。
第九步:发送完block2后,host7,host8,host4向NameNode,host7向Client发送通知,如图浅绿色实线所示。
第十步:client向NameNode发送消息,说我写完了,如图黄色粗实线。。。这样就完毕了。
通过写过程,我们可以了解到:
1)写1T文件,我们需要3T的存储,3T的网络流量贷款。
2)在执行读或写的过程中,NameNode和DataNode通过HeartBeat进行保存通信,确定DataNode活着。如果发现DataNode死掉了,就将死掉的DataNode上的数据,放到其他节点去。读取时,要读其他节点。
3)挂掉一个节点,没关系,还有其他节点可以备份;甚至,挂掉某一个机架,也没关系;其他机架上,也有备份。
2.读取操作

前提:
client要从datanode上,读取FileA。而FileA由block1和block2组成。
2)namenode查看Metadata信息,返回fileA的block的位置。
block1:host2,host1,host3
block2:host7,host8,host4
3)block的位置是有先后顺序的,先读block1,再读block2。而且block1去host2上读取;然后block2,去host7上读取;
4.HDFS文件操作
1.Linux 命令操作
列出HDFS下所有文件夹:
./bin/hadoop fs -ls
列出HDFS下input目录下文件:
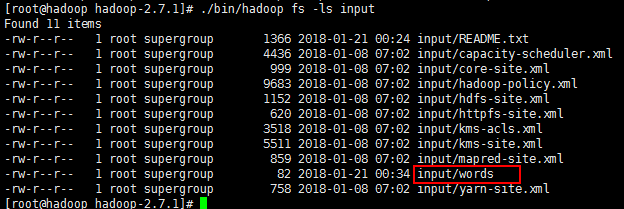
./bin/hadoop fs -ls input
上传文件到指定目录:这里上传/home/data/words文件 到input目录。
./bin/hadoop fs -put /home/data/words input查看上传结果
从HDFS中复制文件到本地文件夹:复制HDFS中input/words文件到 hadoop目录下tmp文件夹
./bin/hadoop fs -get input/words tmp/删除HDFS中文件:将HDFS中文件input/README.txt删除
./bin/hadoop fs -rmr input/README.txt查看HDFS基本统计信息:
[root@hadoop hadoop-2.7.1]# ./bin/hadoop dfsadmin -report
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
Configured Capacity: 18779398144 (17.49 GB)
Present Capacity: 9945313280 (9.26 GB)
DFS Remaining: 9944788992 (9.26 GB)
DFS Used: 524288 (512 KB)
DFS Used%: 0.01%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
Live datanodes (1):
Name: 192.168.1.113:50010 (hadoop)
Hostname: hadoop
Decommission Status : Normal
Configured Capacity: 18779398144 (17.49 GB)
DFS Used: 524288 (512 KB)
Non DFS Used: 8834084864 (8.23 GB)
DFS Remaining: 9944788992 (9.26 GB)
DFS Used%: 0.00%
DFS Remaining%: 52.96%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sun Jan 21 00:48:13 PST 2018















 968
968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









