







Linux版本
Centos 6.5 (64位)Hadoop版本
Hadoop 2.7.3其他所需软件
java (1.7+) [安装、配置,参考 http://blog.csdn.net/molaifeng/article/details/50160929]
ssh [安装、配置,参考 http://blog.csdn.net/molaifeng/article/details/51684086]
vim [安装,yum install -y vim]集群概况
皆为虚拟机,网络为桥接
10.254.21.30 Master
10.254.21.122 Slave1
10.254.21.29 Slave2
10.254.21.35 Slave3
添加用户
添加用户
useradd hadoop设置密码
passwd拥有管理员权限
vim /etc/sudoers
hadoop ALL=(ALL) ALL 配置网络和主机名
配置网络
在/etc/hosts里加上
10.254.21.30 Master
10.254.21.122 Slave1
10.254.21.29 Slave2
10.254.21.35 Slave3
同时,需查看localhost对应的是127.0.0.1
127.0.0.1 localhost即
127.0.0.1 localhost
10.254.21.30 Master
10.254.21.122 Slave1
10.254.21.29 Slave2
10.254.21.35 Slave3
修改主机名
四台服务器修改主机名分别为Master、Slave1、Slave2、Slave3
vim /etc/sysconfig/network
HOSTNAME=Master重启
reboot查看主机名
hostname在Master服务器上,显示Master则成功了。
SSH无密码登录
切换到hadoop用户
su hadoop设置无密码登录
cd ~/.ssh/
ssh-keygen -t rsa # 只管按按回车即可
cat id_rsa.pub >> authorized_keys # 加入本机授权
chmod 600 authorized_keys 配置好后,ssh localhost便不用输入密码了,其余三台服务器都操作。最后把Master服务器上的id_rsa.pub文件内容追加到三台Slave服务器上的authorized_keys,使得Master无需密码即可登录三台Slave服务器。
注:如果在ssh登录过程中出现“Permanently added (RSA) to the list of known hosts”提示,进入
/etc/ssh/ssh_config,把StrictHostKeyChecking no及UserKnownHostsFile /dev/null给注释了即可。
关闭防火墙
sudo service iptables stop或是不让其开启
sudo chkconfig iptables off安装、配置Hadoop
安装
也可以到官网去下载稳定版本.
cd /usr/localhost
sudo wget http://mirrors.cnnic.cn/apache/hadoop/common/stable/hadoop-2.7.3.tar.gz
sudo tar zxf hadoop-2.7.3.tar.gz
sudo mv hadoop-2.7.3 hadoop
sudo chown hadoop.hadoop hadoop -R由于下载的是编译的版本,因此可以开箱即用,先看看版本,检查下是否可用
cd /usr/local/hadoop
./bin/hadoop version出现版本信息说明可用
Hadoop 2.7.3
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff
Compiled by root on 2016-08-18T01:41Z
Compiled with protoc 2.5.0
From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4
This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-2.7.3.jar配置
- 修改环境变量,将hadoop加进去,其余三台服务器都要操作
sudo vim /etc/profile
export HADOOP_HOME = /usr/local/hadoop
export PATH = $JAVA_HOme/bin:$HADOOP_HOME/bin:$PATH在命令行输入. /etc/profile并回车使其生效
- 修改配置文件【/usr/local/hadoop/etc/hadoop/】
slaves,去掉localhost,添加Slave,即NameNode为Master服务器,DataNode为三台Slave服务器
Slave1
Slave2
Slave3hadoop-env.sh
export JAVA_HOME='/usr/lib/jvm/java-1.8.0-openjdk.x86_64'core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
</configuration>若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。由于默认的安装包没有tmp目录,因此需要手动添加, sudo mkdir /usr/local/hadoop/tmp
hdfs-site.xml,其中dfs.replication为3,因为有三个DataNode节点
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>打包hadoop目录,发送给三台Slave服务器
sudo tar -zcf ~/hadoop.master.tar.gz /user/local/hadoop
scp ~/hadoop.master.tar.gz hadoop@Slave1:/home/hadoop在Slave1服务器上解压、修改权限
tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown hadoop.hadoop hadoop -R其余Slave两台服务器操作也一样。至此,Master、Slave服务器上环境都配好了,接下来就是在Master服务器上启动Hadoop。
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver分别在Master和Slave服务器上输入jps,查看运行的JAVA进程
Master
[hadoop@Master hadoop]$ jps
6096 NameNode
6704 JobHistoryServer
6281 SecondaryNameNode
6427 ResourceManager
29535 JpsSlave1
[hadoop@Slave1 hadoop]$ jps
83617 Jps
56530 DataNode
56635 NodeManager在Master服务器上输入hdfs dfsadmin -report查看DataNode是否正常启动
Configured Capacity: 55574487040 (51.76 GB)
Present Capacity: 16329748480 (15.21 GB)
DFS Remaining: 16329654272 (15.21 GB)
DFS Used: 94208 (92 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
Live datanodes (3):
Name: 10.254.21.35:50010 (Slave3)
Hostname: Slave3
Decommission Status : Normal
Configured Capacity: 18569568256 (17.29 GB)
DFS Used: 28672 (28 KB)
Non DFS Used: 11105554432 (10.34 GB)
DFS Remaining: 7463985152 (6.95 GB)
DFS Used%: 0.00%
DFS Remaining%: 40.19%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Oct 27 11:16:56 CST 2016
Name: 10.254.21.29:50010 (Slave2)
Hostname: Slave2
Decommission Status : Normal
Configured Capacity: 18569568256 (17.29 GB)
DFS Used: 32768 (32 KB)
Non DFS Used: 11105423360 (10.34 GB)
DFS Remaining: 7464112128 (6.95 GB)
DFS Used%: 0.00%
DFS Remaining%: 40.20%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Oct 27 11:16:56 CST 2016
Name: 10.254.21.122:50010 (Slave1)
Hostname: Slave1
Decommission Status : Normal
Configured Capacity: 18435350528 (17.17 GB)
DFS Used: 32768 (32 KB)
Non DFS Used: 17033760768 (15.86 GB)
DFS Remaining: 1401556992 (1.31 GB)
DFS Used%: 0.00%
DFS Remaining%: 7.60%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Oct 27 11:16:56 CST 2016也可以在浏览器上输入http://10.254.21.110:50070查看NameNode和DataNode信息。
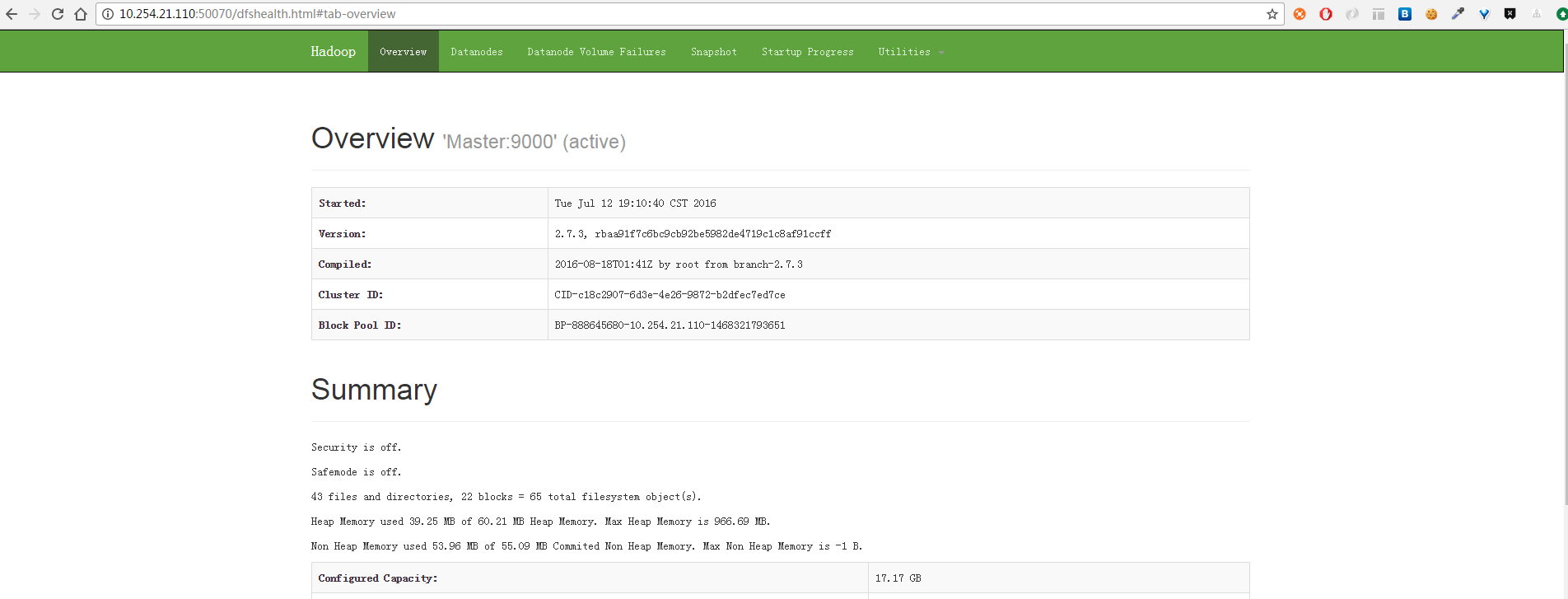
运行DEMO
在Master服务器上创建 HDFS 上的用户目录
hdfs dfs -mkdir -p /user/hadoop查看
[hadoop@Master hadoop]$ hdfs dfs -ls /user
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2016-10-21 17:46 /user/hadoop创建Hadoop用户的input目录
hdfs dfs -mkdir input上传到input目录
./bin/hdfs dfs -put ./etc/hadoop/*.xml input查看
[hadoop@Master hadoop]$ hdfs dfs -ls input
Found 9 items
-rw-r--r-- 1 hadoop supergroup 4436 2016-10-24 10:03 input/capacity-scheduler.xml
-rw-r--r-- 1 hadoop supergroup 1072 2016-10-24 10:03 input/core-site.xml
-rw-r--r-- 1 hadoop supergroup 9683 2016-10-24 10:03 input/hadoop-policy.xml
-rw-r--r-- 1 hadoop supergroup 1322 2016-10-24 10:03 input/hdfs-site.xml
-rw-r--r-- 1 hadoop supergroup 620 2016-10-24 10:03 input/httpfs-site.xml
-rw-r--r-- 1 hadoop supergroup 3518 2016-10-24 10:03 input/kms-acls.xml
-rw-r--r-- 1 hadoop supergroup 5511 2016-10-24 10:03 input/kms-site.xml
-rw-r--r-- 1 hadoop supergroup 1134 2016-10-24 10:03 input/mapred-site.xml
-rw-r--r-- 1 hadoop supergroup 930 2016-10-24 10:03 input/yarn-site.xml运行实例
./bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'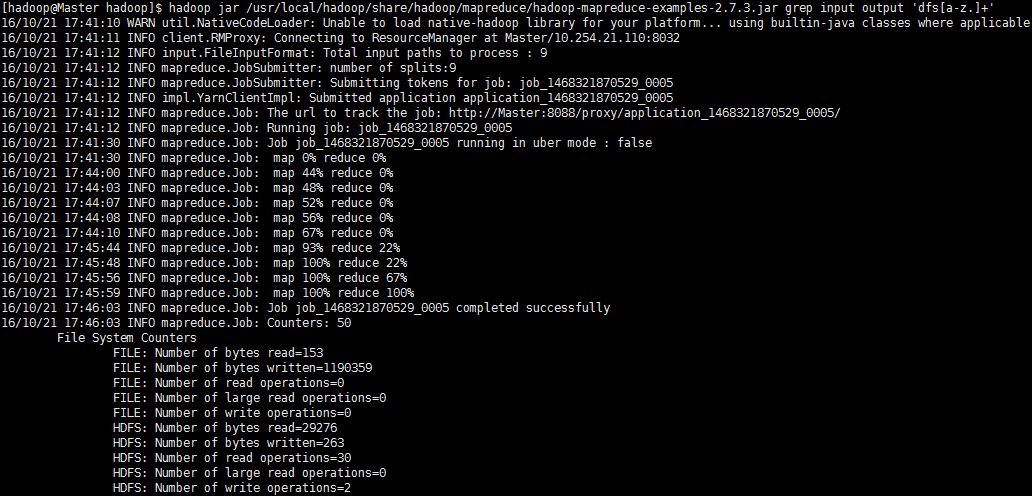
在Master服务器上关闭 Hadoop 集群
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.sh stop historyserver遇到的坑
由于是在虚拟机上安装、配置,时间上是不一致的,需要同步时间
ntpdate pool.ntp.org当命令行报WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable此警告时,无需担心,因为下的二进制包,若是碍眼,可以去官网下载源码包,安装、编译即可。
当启动Hadoop遇到DataNode没起来时,可以在Slave服务器上删除tmp目录,之后再重新启动。
sudo rm -rf tmp
sudo rm -rf logs/*
hdfs namenode -format














 954
954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









