







介绍
hive在执行查询的时候会把sql任务分解成mapreduce job去执行,所以hive一般作为批量查询的场景比较多,mapreduce job启动较慢,经常有job运行时间在30分钟以上,作为分析人员肯定要崩溃的,而impala作为交互查询的场景比较多,不过自从hvie 1.1之后,hive查询可以采用spark引擎去执行的时候,我们又多了一个可选的方案。
注意
要使用Hive on Spark,所用的Spark版本必须不包含Hive的相关jar包,hive on spark 的官网上说“Note that you must have a version of Spark which does not include the Hive jars”。在spark官网下载的编译的Spark都是有集成Hive的,因此需要自己下载源码来编译,并且编译的时候不指定Hive,而且,你使用的Hive版本编译时候用的哪个版本的Spark,那么就需要使用相同版本的Spark。
环境
操作系统:Centos 6.7
hadoop:CDH 5.10
maven:apache-maven-3.3.9
JDK:java 1.7.0_67
组件
| Host | HDFS | YARN | Hive | Spark | Impala | Zookeeper |
|---|---|---|---|---|---|---|
| hadoop1 | NameNode | ResourceManager | Work | |||
| hadoop2 | DateNode | NodeManager | Work | ZKServer | ||
| hadoop3 | DateNode | NodeManager | Work | ZKServer | ||
| hadoop4 | DateNode | NodeManager | Work | ZKServer | ||
| hadoop5 | DateNode | NodeManager | HiveServer | Work | ||
| hadoop6 | NameNode | ResourceManager | Master/History/Work |
ps:提前做好hadoop1到hadoop2-6的无密码登录,hadoop6到hadoop1-5的无密码登录,因为NM和RM是HA模式部署的。
编译
下载spark源码
wget 'http://archive.cloudera.com/cdh5/cdh/5/spark-1.6.0-cdh5.10.0-src.tar.gz'解压
默认软件安装目录为/opt/programs/
tar zxvf spark-1.6.0-cdh5.10.0-src.tar.gz设置好mvn/java路径
export JAVA_HOME=/opt/programs/java_1.7.0
PATH=$PATH:/opt/programs/maven_3.3.9/bin
export PATH设置mvn堆栈大小
因为编译时间较长,软件较大,为了缩短时间,需要提前设置mvn堆栈大小
export MAVEN_OPTS="-Xmx6g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"编译spark
程序目录:/opt/programs/spark-1.6.0-cdh5.10.0
./make-distribution.sh --name "hadoop2-without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.6,parquet-provided"ps:编译时间较长,网络不好的情况下,经常中断
结果
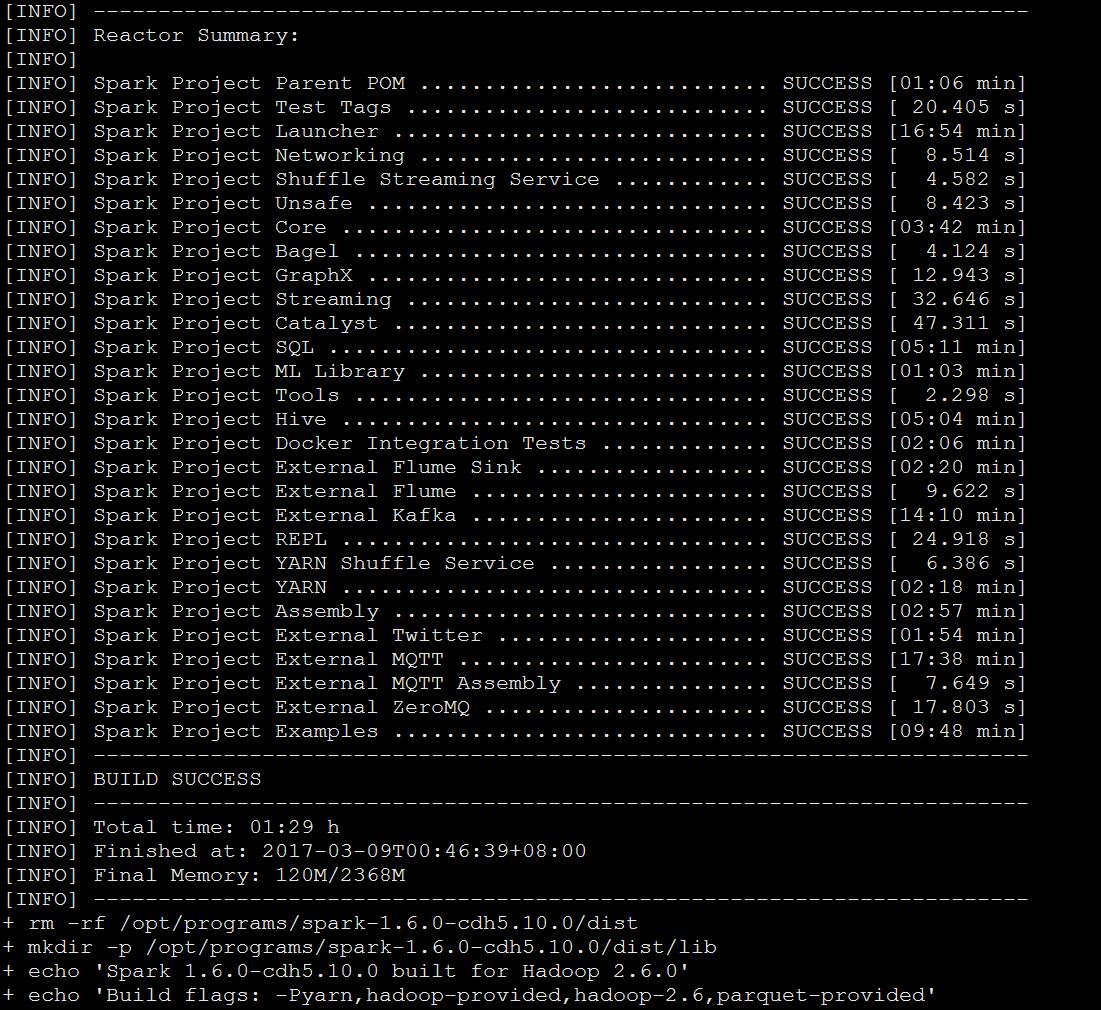
ps:虽然之前也搞过CDH5.5的hive on spark,再一次编译乘成功,还是小小激动了一下
鄙视CDH一下
用惯了CDH发行版hadoop的人,在安装完CDH自带的spark之后,发现系统中没有spark-sql,CDH为了推广自家的impala,在编译完成后把spark-sql删除了。
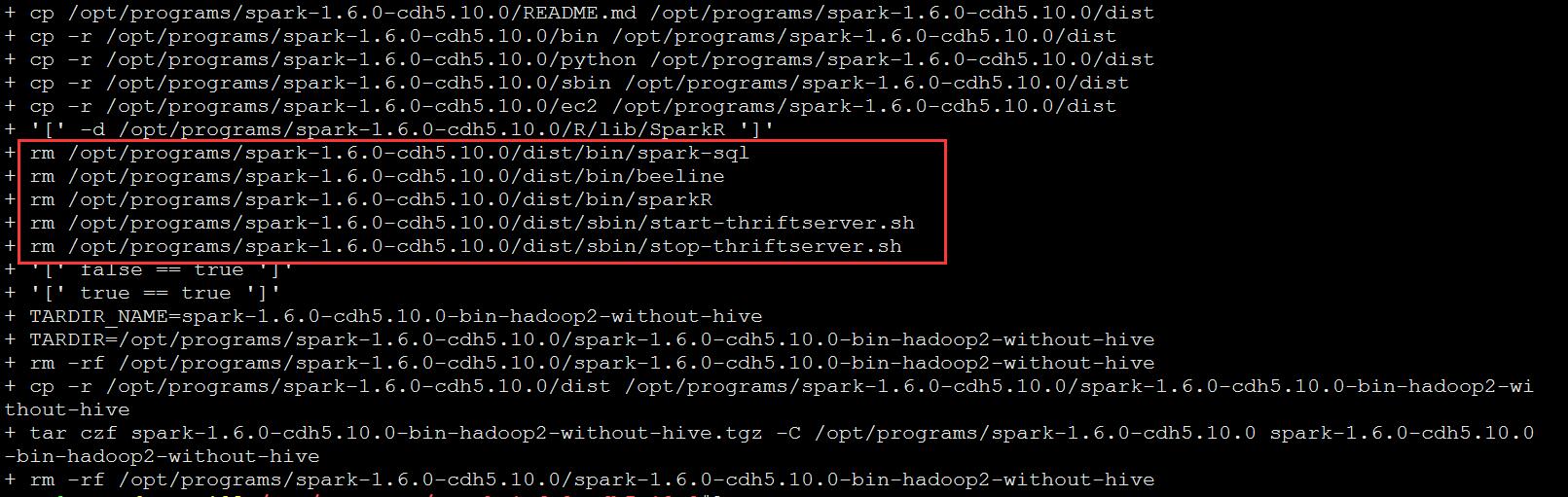
打包
在/opt/programs/spark-1.6.0-cdh5.10.0目录下面生成了一个spark-1.6.0-cdh5.10.0-bin-hadoop2-without-hive.tgz安装包,不过,在部署的时候还需要assembly、lib_managed两个目录,

tar czvf spark-1.6.0.tgz spark-1.6.0-cdh5.10.0-bin-hadoop2-without-hive.tgz assembly lib_managedps:打包好的spark-1.6.0.tgz文件拷贝到hadoop1-hadoop6,部署目录
部署spark
master
把spark-1.6.0.tgz解压到/opt/programs/spark_1.6.0目录下面
tar zxvf spark-1.6.0.tgz -C /opt/programs/spark_1.6.0/
cd /opt/programs/spark_1.6.0
tar zxvf spark-1.6.0-cdh5.10.0-bin-hadoop2-without-hive.tgz 
ps:删除了spark-1.6.0-cdh5.10.0-bin-hadoop2-without-hive.tgz解压出来后一些无关紧要的目录
配置
slaves
hadoop1
hadoop2
hadoop3
hadoop4
hadoop5
hadoop6spark-env.sh
#!/usr/bin/env bash
export SPARK_HOME=/opt/programs/spark_1.6.0
export HADOOP_HOME=/usr/lib/hadoop
export JAVA_HOME=/opt/programs/jdk1.7.0_67
export HADOOP_HOME=/usr/lib/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_LAUNCH_WITH_SCALA=0
export SPARK_WORKER_MEMORY=300M
export SPARK_DRIVER_MEMORY=300M
export SPARK_EXECUTOR_MEMORY=300M
export SPARK_MASTER_IP=192.168.1.6
export SPARK_LIBRARY_PATH=${SPARK_HOME}/lib
export SPARK_MASTER_WEBUI_PORT=18080
export SPARK_WORKER_DIR=${SPARK_HOME}/work
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_PORT=7078
export SPARK_LOG_DIR=${SPARK_HOME}/log
export SPARK_PID_DIR=${SPARK_HOME}/run
export SCALA_HOME="/opt/programs/scala_2.10.6"
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://dev-guol:8020/spark/log"
if [ -n "$HADOOP_HOME" ]; then
export LD_LIBRARY_PATH=:/usr/lib/hadoop/lib/native
fi
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/etc/hadoop/conf}
if [[ -d $SPARK_HOME/python ]]
then
for i in
do
SPARK_DIST_CLASSPATH=${SPARK_DIST_CLASSPATH}:$i
done
fi
SPARK_DIST_CLASSPATH="$SPARK_DIST_CLASSPATH:$SPARK_LIBRARY_PATH/spark-assembly-1.6.0-cdh5.10.0-hadoop2.6.0.jar"
SPARK_DIST_CLASSPATH="$SPARK_DIST_CLASSPATH:/usr/lib/hadoop/lib/*"
SPARK_DIST_CLASSPATH="$SPARK_DIST_CLASSPATH:/usr/lib/hadoop/*"
SPARK_DIST_CLASSPATH="$SPARK_DIST_CLASSPATH:/usr/lib/hadoop-hdfs/lib/*"
SPARK_DIST_CLASSPATH="$SPARK_DIST_CLASSPATH:/usr/lib/hadoop-hdfs/*"
SPARK_DIST_CLASSPATH="$SPARK_DIST_CLASSPATH:/usr/lib/hadoop-mapreduce/lib/*"
SPARK_DIST_CLASSPATH="$SPARK_DIST_CLASSPATH:/usr/lib/hadoop-mapreduce/*"
SPARK_DIST_CLASSPATH="$SPARK_DIST_CLASSPATH:/usr/lib/hadoop-yarn/lib/*"
SPARK_DIST_CLASSPATH="$SPARK_DIST_CLASSPATH:/usr/lib/hadoop-yarn/*"
SPARK_DIST_CLASSPATH="$SPARK_DIST_CLASSPATH:/usr/lib/hive/lib/*"
SPARK_DIST_CLASSPATH="$SPARK_DIST_CLASSPATH:/usr/lib/flume-ng/lib/*"
SPARK_DIST_CLASSPATH="$SPARK_DIST_CLASSPATH:/usr/lib/paquet/lib/*"
SPARK_DIST_CLASSPATH="$SPARK_DIST_CLASSPATH:/usr/lib/avro/lib/*"
spark-defaults.conf
spark.master yarn-cluster
spark.home /opt/programs/spark_1.6.0
spark.eventLog.enabled true
spark.eventLog.dir hdfs://dalu:8020/spark/log
spark.eventLog.compress true
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.executor.memory 300m
spark.driver.memory 300m
ps:提前在HDFS上创建/spark/log目录,并注意权限
worker
work的部署和master一样,只需要吧master的spark_1.6.0目录打包拷贝到work的相同目录下即可。
启动
在master上启动整个spark集群
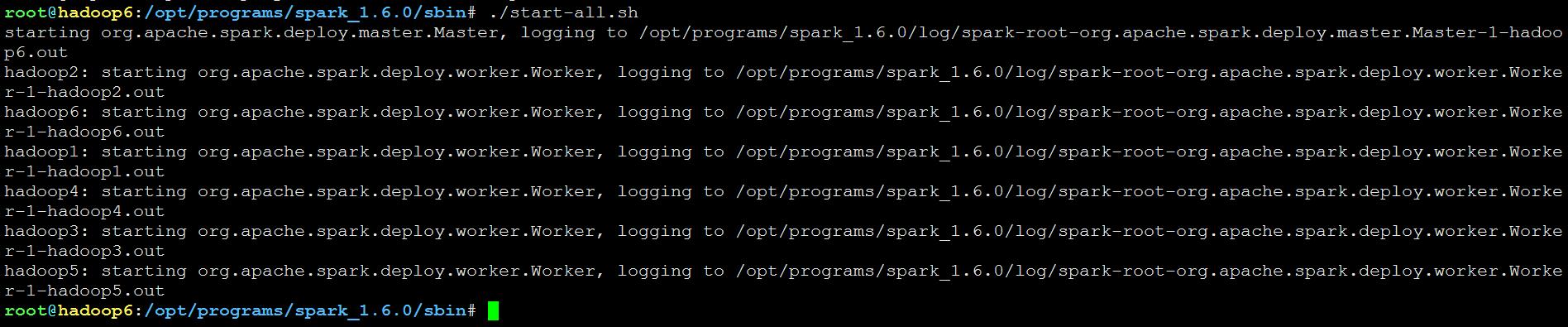
测试spark
查看UI
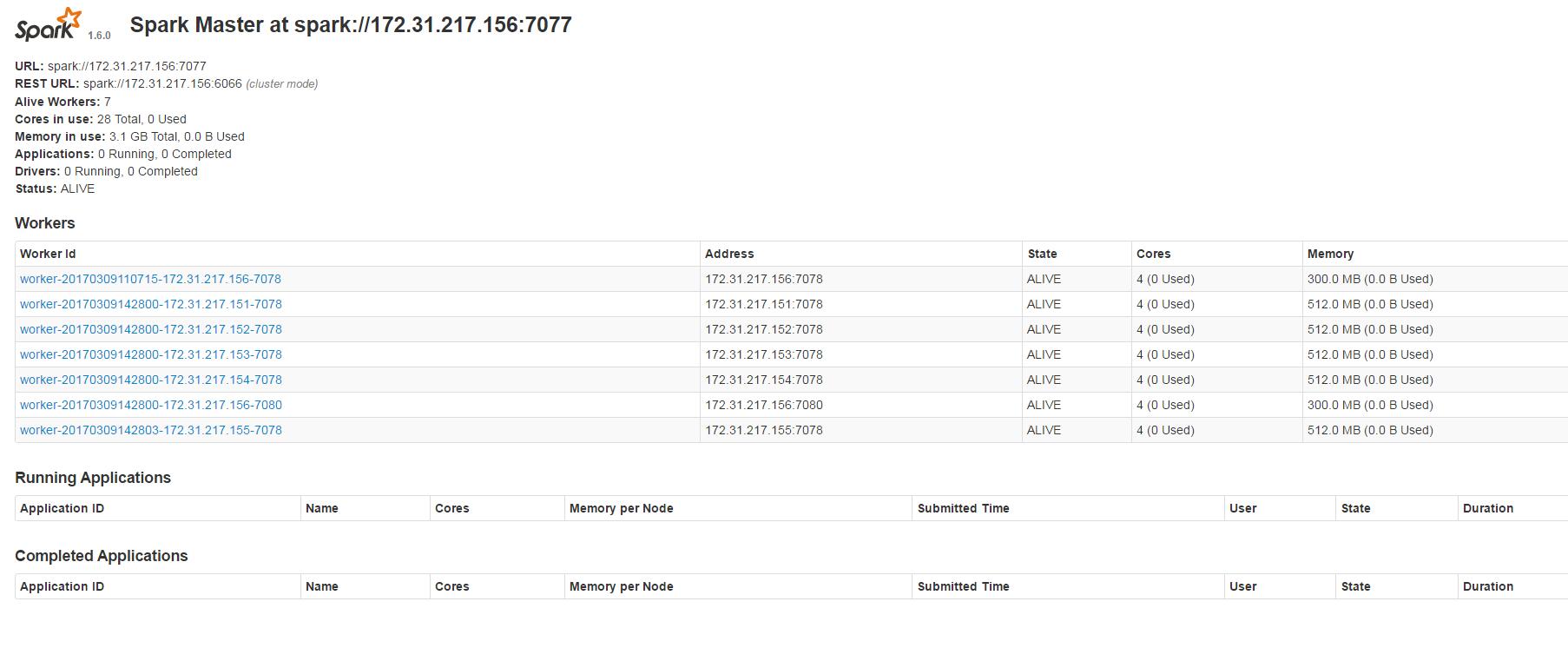
执行spark任务
cd /opt/programs/spark_1.6.0/bin
./spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ../lib/spark-examples-1.6.0-cdh5.10.0-hadoop2.6.0.jar 10结果:

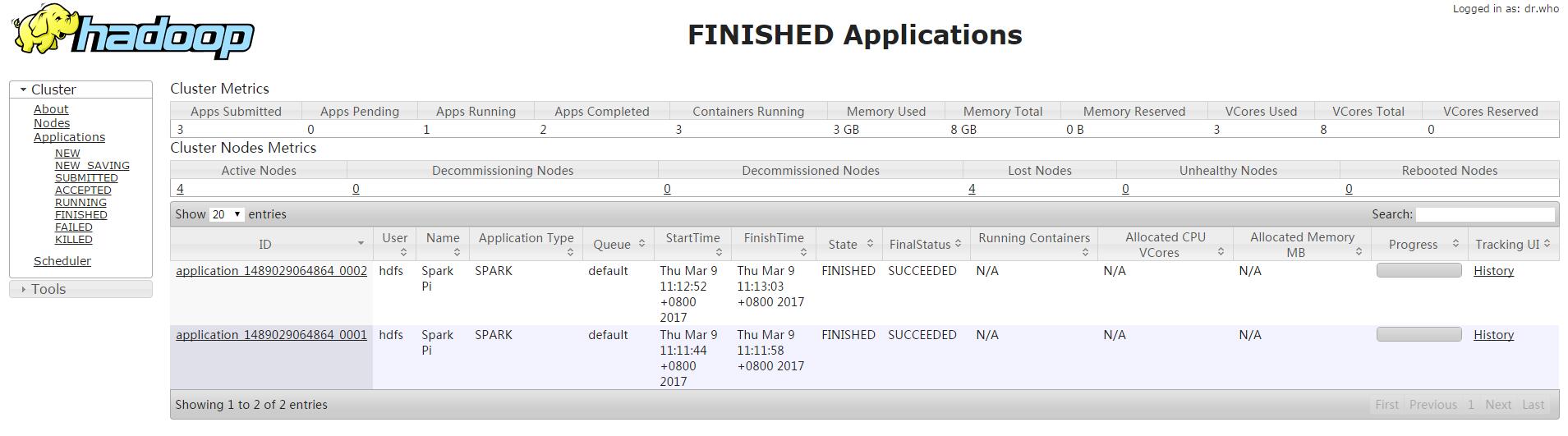
ps:至此,spark集群已经安装完毕
调整hive配置(hadoop5)
hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.1.2:3306/metastore</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>datanucleus.readOnlyDatastore</name>
<value>false</value>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>false</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateTables</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateColumns</name>
<value>true</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>haddop1:23125,hadoop6:23125</value>
</property>
<property>
<name>hive.auto.convert.join</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.warehouse.subdir.inherit.perms</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop5:9083</value>
</property>
<property>
<name>hive.metastore.client.socket.timeout</name>
<value>36000</value>
</property>
<property>
<name>hive.zookeeper.quorum</name>
<value>hadoop2:2181,hadoop3:2181,hadoop4:2181</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hive.server2.thrift.min.worker.threads</name>
<value>2</value>
</property>
<property>
<name>hive.server2.thrift.max.worker.threads</name>
<value>10</value>
</property>
<property>
<name>hive.metastore.authorization.storage.checks</name>
<value>true</value>
</property>
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/var/lib/hadoop-hdfs/dn_socket</value>
</property>
<!-- hive on spark -->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<property>
<name>hive.enable.spark.execution.engine</name>
<value>true</value>
</property>
<property>
<name>spark.home</name>
<value>/opt/programs/spark_1.6.0</value>
</property>
</configuration>
ps:主要是追加最后三个属性
添加lib
cp /opt/programs/spark_1.6.0/lib/spark-assembly-1.6.0-cdh5.10.0-hadoop2.6.0.jar /usr/lib/hive/lib/重启hive
/etc/init.d/hive-metastore restart
/etc/init.d/hive-server2 restart测试hive
使用beeline连接hiveserver,执行查询语句
beeline -u jdbc:hive2://hadoop5:10000
select count(*) from weblog3;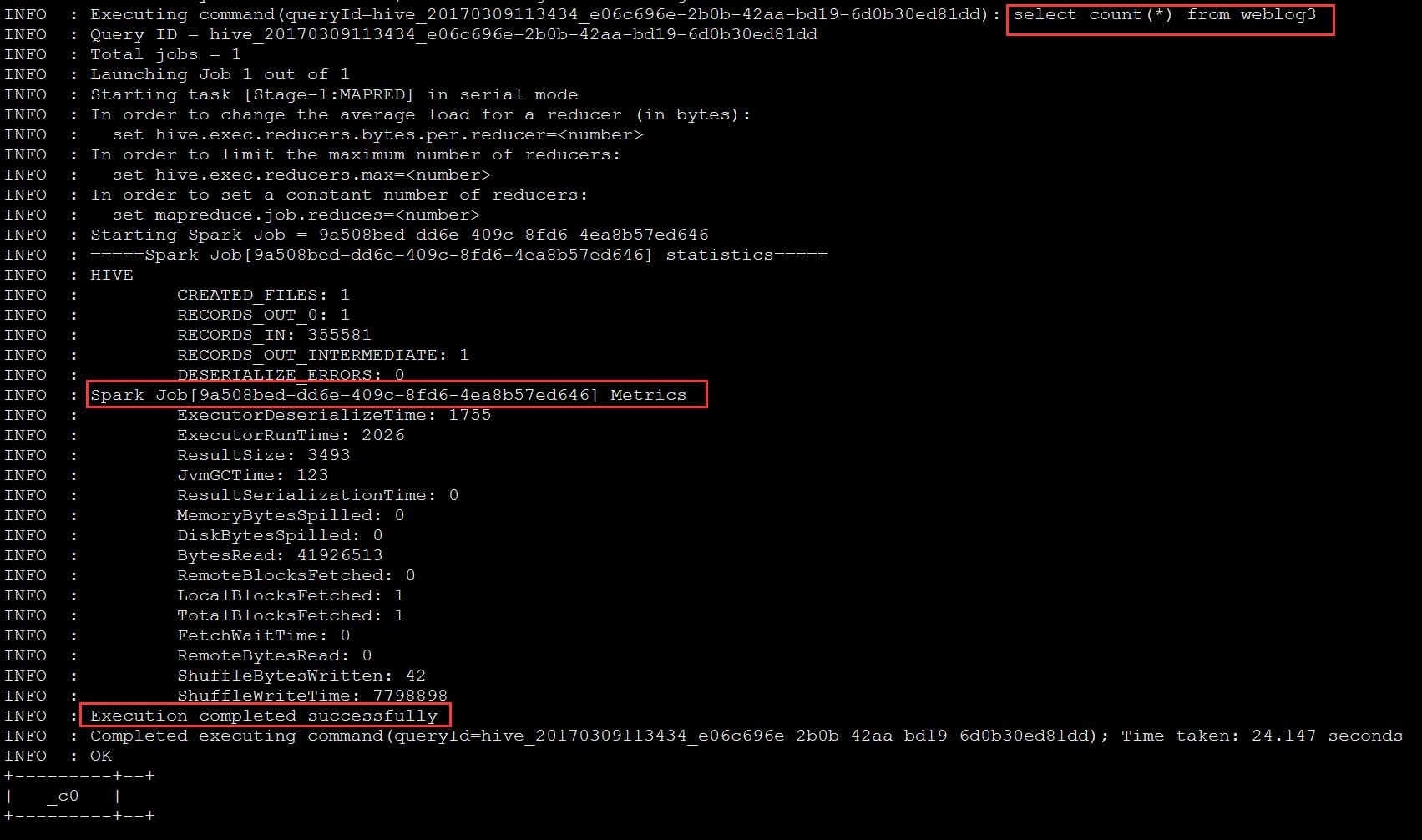
查看YARN
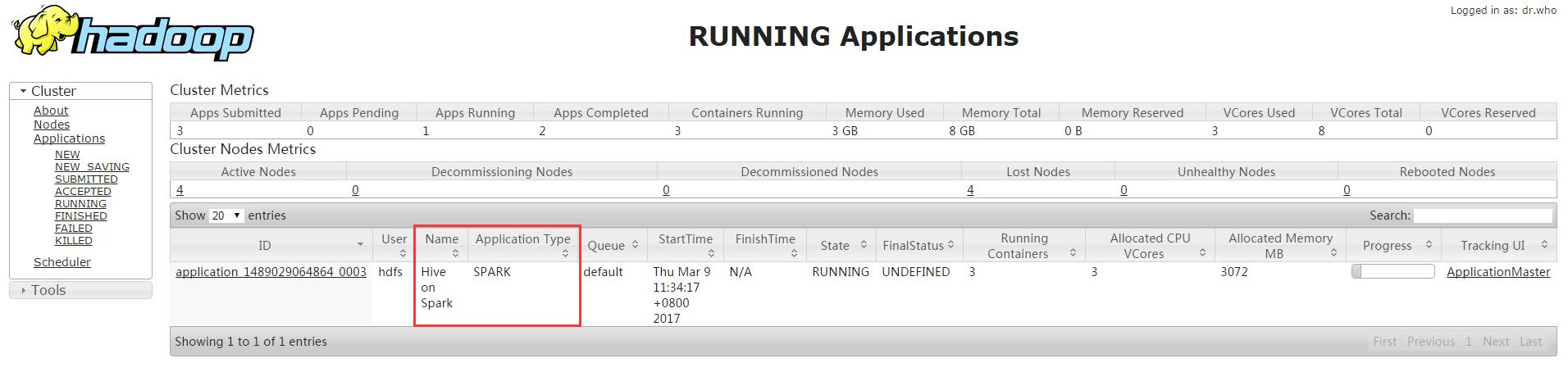
参考















 3602
3602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









