






这个问题以前也遇到过,这是第二次了。这个问题比较有意思,一开始考虑的很多因素都被一一排除了,最后才发现问题所在。当使用select min(col1) from t或者select max(col1)的时候,如果xx字段上有合适的索引的话,oracle就会使用index full scan(min/max)的route。这个route是怎么的呢,很简单,如果是min从index(这里指的是asc排序的index)的最左边(root--> branch block --> leaf block )一直下去,找到第一个leaf block,从里面找出最小值。如果是max就是从最右边找到最右边的leaf block,找出最大值。我画了简单的图示如下:
这样走应该是很快的,即使是level=4的index也只需要走5个block就可以了,不会出现很慢的情况。
但是遇到很慢的情况,查看执行计划没有错。
1 0 SORT (AGGREGATE)
2 1 FIRST ROW (Cost=1 Card=1 Bytes=8)
3 2 INDEX (RANGE SCAN (MIN/MAX)) OF xxxxx
' (UNIQUE) (Cost=1 Card=1)
排除了一些其他的因素后,开始怀疑就是这个route耗费了时间。查看statistics,发现logical read很高,达到10w级别。于是设计下面的试验,使用10202 event,一目了然。
SQL> create table test as select * from dba_objects;
Table created.
SQL> create index idx_test on test(owner,object_id);
Index created.
SQL> analyze table test estimate statistics;
Table analyzed.
SQL> select max(object_id ) from test where wner='PUBLIC';
MAX(OBJECT_ID)
--------------
631657
2 consistent gets
SQL> select max(object_id ) from test where wner='PUBLIC';
MAX(OBJECT_ID)
--------------
7 consistent gets
Here is the 10202 dump file:
Dump file c:\oracle\admin\test\udump\test_ora_1124.trc
Fri Aug 05 11:38:09 2005
ORACLE V9.2.0.1.0 - Production vsnsta=0
vsnsql=12 vsnxtr=3
Windows 2000 Version 5.1 Service Pack 2, CPU type 586
Oracle9i Enterprise Edition Release 9.2.0.1.0 - Production
With the OLAP and Oracle Data Mining options
JServer Release 9.2.0.1.0 - Production
Windows 2000 Version 5.1 Service Pack 2, CPU type 586
Instance name: test
Redo thread mounted by this instance: 1
Oracle process number: 10
Windows thread id: 1124, image: ORACLE.EXE
*** 2005-08-05 11:38:09.000
*** SESSION ID:(9.9) 2005-08-05 11:38:09.000
Consistent read complete...
Block header dump:0x0040f2f7
Object id on Block? Y
seg/obj: 0x199e csc: 0x00.127368 itc: 2 flg: O typ: 2 - INDEX
fsl: 2 fnx: 0x40f2f6 ver: 0x01
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
0x02 0x0008.019.000001df 0x00801c7e.008c.10 --U- 327 fsc 0x1c02.00127461
Consistent read complete...
Block header dump:0x0040f2f6
Object id on Block? Y
seg/obj: 0x199e csc: 0x00.127368 itc: 2 flg: O typ: 2 - INDEX
fsl: 2 fnx: 0x40f2f4 ver: 0x01
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
0x02 0x0008.019.000001df 0x00801c7d.008c.2f --U- 327 fsc 0x1c03.00127461
Consistent read complete...
Block header dump:0x0040f2f5
Object id on Block? Y
seg/obj: 0x199e csc: 0x00.127368 itc: 2 flg: O typ: 2 - INDEX
fsl: 2 fnx: 0x40f301 ver: 0x01
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
0x02 0x0008.019.000001df 0x00801c76.008c.34 --U- 327 fsc 0x1c03.00127461
Consistent read complete...
Block header dump:0x0040f2f4
Object id on Block? Y
seg/obj: 0x199e csc: 0x00.127368 itc: 2 flg: O typ: 2 - INDEX
fsl: 2 fnx: 0x40f2f5 ver: 0x01
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
0x02 0x0008.019.000001df 0x00801c7c.008c.16 --U- 327 fsc 0x1bff.00127461
Consistent read complete...
Block header dump:0x0040f2f3
Object id on Block? Y
seg/obj: 0x199e csc: 0x00.127368 itc: 2 flg: O typ: 2 - INDEX
fsl: 2 fnx: 0x40f304 ver: 0x01
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
0x02 0x0008.019.000001df 0x00800084.008e.36 --U- 334 fsc 0x1bfe.00127461
(补充:上面红色的标注的address对应于index的tree dump便产生了下面的route路线图)
Seems the select go the following route
Found the most right leaf block is empty, it went back until find one leaf block contains value. If all the leaf blocks in the range are empty, it will scan all leaf blocks in the range.
所以出现这种很慢情况的原因就是删除了大量的记录,所以路线中从leaf block到leaf block的过程需要读取大量的blocks(实际情况下读取了十万左右的block数),耗费了大量的时间。
解决这个问题有两个办法,一个是rebuild index (online),另外一个是coalesce index。两者各有优劣,Lewis在IOUG 2005 seminar上有一篇文章中有关于rebuild和coalesce的比较,大家有兴趣可以去找找。我这边节选一点:
Feature Pro Con
Coalesce
Completely "online" process as it doesn't do any table locking. Repacks within existing index structure.
Can generate a lot of redo. Not very aggressive about repacking so only useful for special cases (until 10g). Can 'cause' ORA-01555 errors
Rebuild ("offline")
Can use the existing index to create the new version. Can be optimized for reduced overheads.
Locks the table for the duration of the rebuild. "Doubles" space usage temporarily. May require massive sorts. Can "cause" Oracle error 01410.
Rebuild online
Does not lock table for entire rebuild. Can be optimized for minimal overheads.
Locks table at start and end of rebuild. Cannot use the index to rebuild the index. "Doubles" space usage temporarily. Adds row-level trigger to table actions. May require massive sorts. Can "cause" Oracle error 01410.
This is from Oracle8i administrator’s guide chapter 14 (managing indexes)
Figure 14-1 Coalescing Indexes
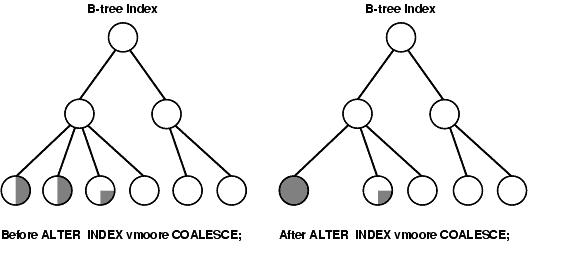
原文引用eagle's blod :http://oracledba.spaces.live.com/blog/cns!57D0C396BA028F14!247.entry















 8189
8189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









